World VLA Loop 비디오 세계 모델과 VLA 정책의 폐쇄 루프 학습
초록
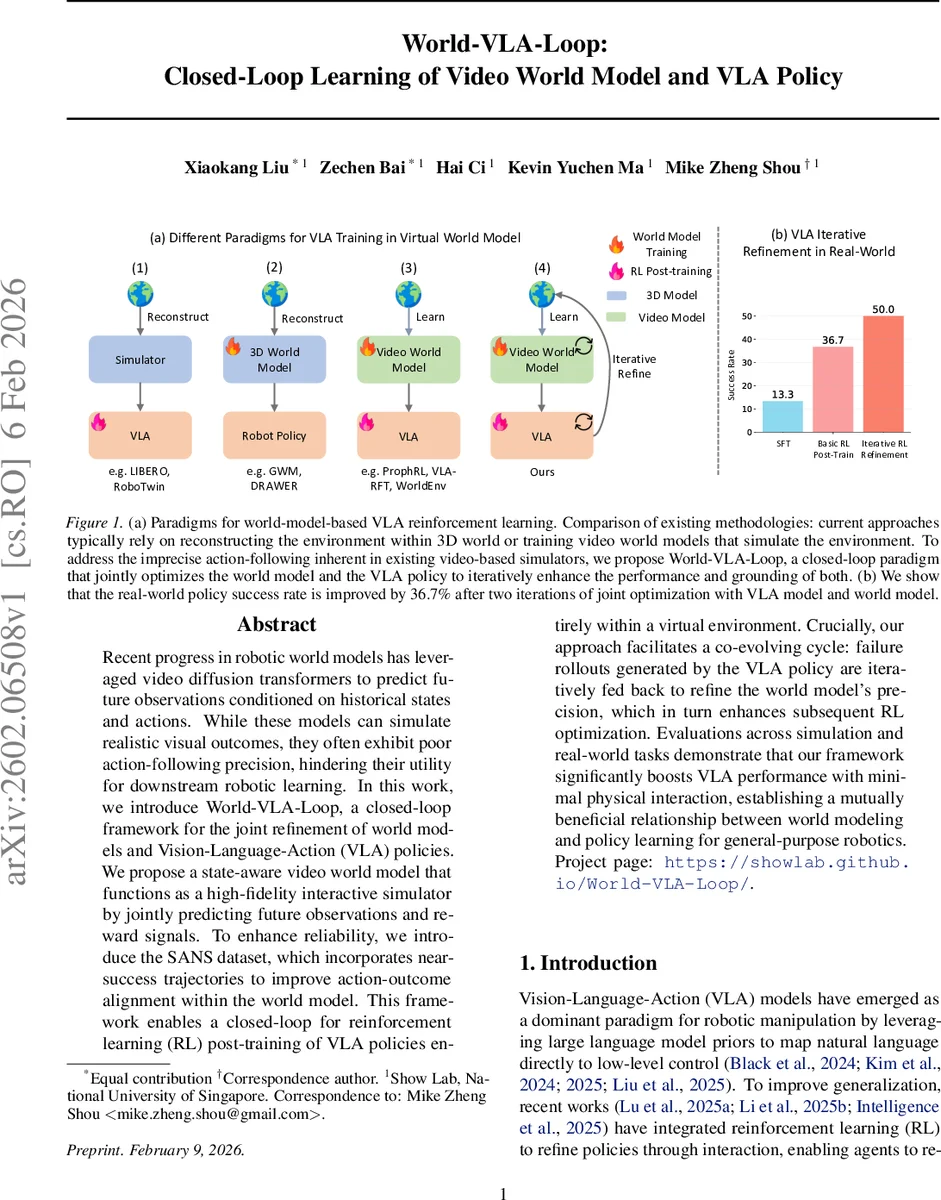
World‑VLA‑Loop은 비디오 기반 세계 모델과 Vision‑Language‑Action(VLA) 정책을 동시에 개선하는 폐쇄‑루프 프레임워크이다. 상태‑인식 비디오 세계 모델은 관찰 영상과 보상 신호를 공동 예측하고, Near‑Success(SANS) 데이터셋을 활용해 행동‑결과 정합성을 강화한다. 실제 로봇 실험과 시뮬레이션에서 최소한의 물리적 상호작용만으로 정책 성공률을 크게 끌어올린다.
상세 분석
본 논문은 로봇 조작 분야에서 최근 각광받고 있는 비디오 확산 트랜스포머 기반 세계 모델의 근본적인 한계인 “행동 추적 정확도 부족”과 “보상 신호의 불신뢰성”을 해결하고자 한다. 이를 위해 제안된 World‑VLA‑Loop은 두 가지 핵심 요소로 구성된다. 첫째, 상태‑인식 비디오 세계 모델은 기존의 Cosmos‑Predict2에 행동 임베딩을 타임스탬프 임베딩에 직접 더함으로써, 입력된 6‑DoF 로봇 행동과 영상 생성 과정을 긴밀히 결합한다. 이와 동시에 디퓨전 라티스에 보상 예측 헤드를 부착해, 라티스 단계별로 스칼라 보상을 회귀 학습한다. 손실 함수는 영상 흐름 손실과 보상 L2 손실을 가중치 λ로 균형 맞추어 공동 최적화한다. 이러한 설계는 (1) 행동에 대한 시각적 결과가 정확히 반영되는 고충실도 시뮬레이터를 제공하고, (2) 보상이 영상 생성 과정에 내재화되어 RL 단계에서 외부 보상 모델에 대한 의존도를 제거한다는 장점을 가진다.
둘째, Near‑Success(SANS) 데이터셋은 성공 궤적뿐 아니라 목표에 근접했으나 미세한 위치 오차 등으로 실패한 궤적을 포함한다. 이러한 “거의 성공” 데이터는 세계 모델이 미세한 동역학 차이를 학습하도록 강제함으로써, 기존 모델이 성공을 과도하게 일반화해 실패 상황을 허위로 예측하는 문제를 완화한다. SANS는 ManiSkill, LIBERO, 실제 로봇 환경 등 23개 작업에 걸쳐 약 35 k개의 비디오‑행동 쌍을 제공하며, 각 프레임에 이진 보상 라벨을 부착한다.
프레임워크의 학습 흐름은 (1) SANS 데이터셋 구축, (2) 세계 모델 사전학습, (3) 학습된 세계 모델 내에서 VLA 정책을 GRPO 기반 강화학습으로 후‑학습, (4) 실제 로봇에서 개선된 정책을 실행해 새로운 실패·성공 데이터를 수집하고 이를 SANS에 재통합하는 순환 구조다. 이 순환은 정책이 새로운 행동 분포를 탐색함에 따라 세계 모델이 지속적으로 최신 행동‑결과 매핑을 학습하도록 만든다.
실험 결과는 시뮬레이션(LIBERO benchmark)와 실제 로봇 실험 모두에서 두 차례의 반복 학습 후 정책 성공률이 평균 36.7 % 상승했음을 보여준다. 특히 물리적 인터랙션 횟수를 최소화하면서도 정책 성능을 크게 향상시킨 점은 로봇 학습 비용 절감에 직접적인 기여를 한다. Ablation study에서는 (a) 보상 헤드 없이 순수 영상 모델을 사용할 경우 RL 단계에서 보상 신호가 부정확해 학습이 불안정해짐을, (b) Near‑Success 데이터를 제외하면 행동‑결과 정합성이 크게 저하되어 실패 상황을 과소평가함을 확인한다.
한계점으로는 현재 모델이 6‑DoF 연속 행동에만 초점을 맞추고 있어 복합적인 힘·토크 제어나 멀티‑모달 센서(예: 촉각)와의 통합이 미비하다는 점, 그리고 디퓨전 기반 비디오 생성의 계산 비용이 여전히 높아 실시간 시뮬레이션에 제약이 있다는 점을 들 수 있다. 향후 연구에서는 (1) 물리 엔진과의 하이브리드 결합을 통해 고속 물리 시뮬레이션을 보완하고, (2) 멀티‑모달 입력을 확장해 복합 작업에 적용하며, (3) 메타‑러닝 기법을 도입해 새로운 작업에 대한 빠른 적응성을 높이는 방향이 기대된다. 전반적으로 World‑VLA‑Loop은 세계 모델과 정책 학습을 상호 보완적으로 진화시키는 새로운 패러다임을 제시하며, 로봇 조작의 데이터 효율성과 일반화 능력을 크게 향상시킬 잠재력을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기