Euphonium: 프로세스 보상 그래디언트로 비디오 흐름 매칭을 안내하는 새로운 프레임워크
초록
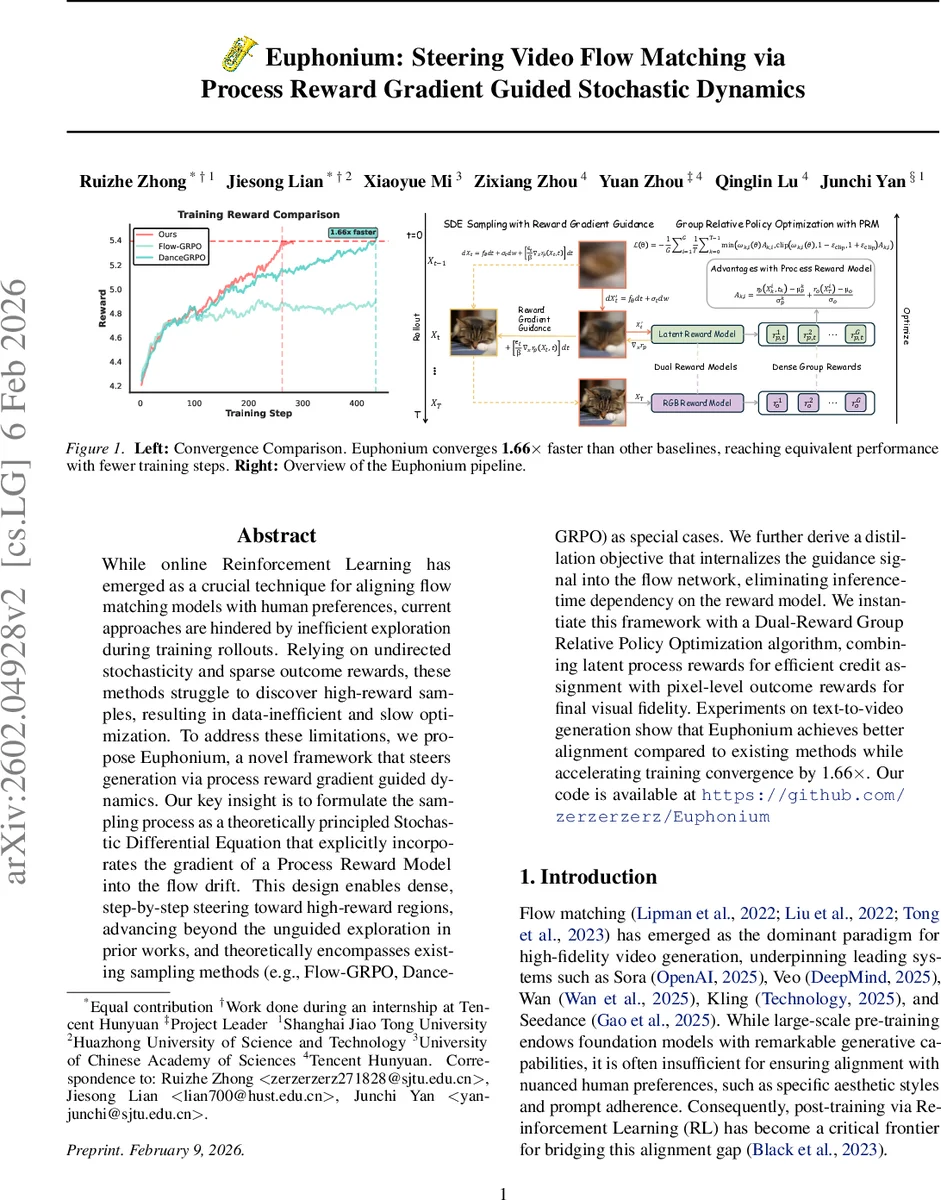
Euphonium은 흐름 매칭 기반 비디오 생성 모델에 프로세스 보상 모델의 그래디언트를 SDE 드리프트에 직접 삽입해 단계별 밀집 보상 신호로 탐색을 안내한다. 이를 통해 기존의 무작위 탐색 방식보다 데이터 효율성을 높이고 학습 수렴을 1.66배 가속화한다. 또한, 보상 신호를 흐름 네트워크에 증류해 추론 시 보상 모델 의존성을 제거한다.
상세 분석
본 논문은 비디오 생성 분야에서 흐름 매칭(flow matching) 모델을 인간 선호와 정렬시키기 위한 온라인 강화학습(RL) 접근법의 근본적인 한계를 지적한다. 기존의 Flow‑GRPO, DanceGRPO 등은 확률적 미분방정식(SDE)을 도입해 탐색성을 확보했지만, 탐색이 완전히 무방향적이며 보상이 최종 결과에만 부여되는 희소 구조이기 때문에 고보상 궤적을 찾기가 어렵다. 이러한 문제를 해결하기 위해 저자들은 두 가지 핵심 아이디어를 제시한다.
첫째, 프로세스 보상 그래디언트 가이드(Stochastic Dynamics with Process Reward Gradient) 를 도입한다. 비디오 생성 과정을 시간‑의존 잠재 변수 Xₜ에 대한 SDE
dXₜ = (u_θ(Xₜ, t) – εₜ∇Uₜ(Xₜ))dt + √(2εₜ)dWₜ
에 기반해 정의하고, 여기서 Uₜ는 –log pₜ(x)와 보상 모델 rₚ(x, t) 를 결합한 포텐셜이다. 구체적으로
Uₜ(x) = –log pₜ(x) – (1/β) rₚ(x, t) + Cₜ
이며, β는 KL 정규화 강도이다. 이 식을 대입하면 보상 그래디언트 ϵₜβ∇ₓrₚ가 드리프트에 직접 추가되어, 매 타임스텝마다 고보상 영역으로 샘플이 밀집하도록 유도한다. 이는 기존 무작위 탐색을 대체하는 밀집형 가이드 메커니즘이며, β→0 일 때는 순수 보상‑주도 탐색, β→∞ 일 때는 기존 흐름 매칭과 동일해지는 연속성을 제공한다.
둘째, Dual‑Reward GRPO 를 설계한다. 여기서는 (i) 잠재 공간에서의 프로세스 보상 rₚ(x, t)와 (ii) 최종 영상 수준의 픽셀‑레벨 보상 rₒ(x)를 동시에 활용한다. 각 타임스텝 k에 대해
Aₖ,i = (rₚ(Xₖ,i, tₖ) – μₖᵖ)/σₖᵖ + (rₒ(X_T,i) – μₒ)/σₒ
와 같이 그룹 정규화된 어드밴티지를 합산하고, 이를 기존 GRPO의 정책 업데이트에 적용한다. 이렇게 하면 신속한 크레딧 할당이 가능해져, 초기 단계에서의 프로세스 보상이 학습 신호를 제공하고, 최종 단계에서는 실제 시각적 품질을 보장한다.
또한, 보상 모델에 대한 의존성을 없애기 위해 증류(distillation) 목표를 도입한다. 보상‑가이드가 적용된 SDE로 생성된 샘플을 교사 데이터로 삼아, 흐름 네트워크 u_θ가 직접 보상 신호를 내재하도록 학습한다. 결과적으로 추론 시에는 순수 흐름 ODE/SDE만 실행하면 되며, 외부 보상 모델을 호출할 필요가 없어 실시간 서비스에 적합하다.
이론적 측면에서는 NETS(Non‑Equilibrium Transport Sampling) 프레임워크를 기반으로, 포텐셜에 보상 항을 추가함으로써 비평형 통계역학 관점에서 샘플링이 정당화된다. 또한, 보상‑가이드가 없는 경우 기존 Flow‑GRPO·DanceGRPO와 동일한 SDE 형태가 도출돼, 제안 방법이 기존 기법을 일반화한다는 점을 증명한다.
실험에서는 텍스트‑투‑비디오 벤치마크 VBench2에서 Euphonium이 기존 방법보다 높은 인간 선호 점수를 기록했으며, 학습 곡선이 1.66배 빨라졌다. 특히, 프로세스 보상만을 사용한 경우와 픽셀 보상만을 사용한 경우를 각각 Ablation 실험으로 비교했을 때, 두 보상을 결합했을 때 가장 큰 성능 향상이 관찰되었다. 코드와 사전 학습된 모델을 공개함으로써 재현성을 확보했다.
요약하면, Euphonium은 (1) 단계별 밀집 보상 그래디언트를 통한 가이드 탐색, (2) 이중 보상을 활용한 효율적 정책 학습, (3) 보상‑프리 추론을 위한 증류 메커니즘이라는 세 축으로 기존 흐름 매칭 기반 RL 정렬 방법의 한계를 극복한다.
댓글 및 학술 토론
Loading comments...
의견 남기기