드리프팅 모델: 한 번에 고품질 이미지 생성
초록
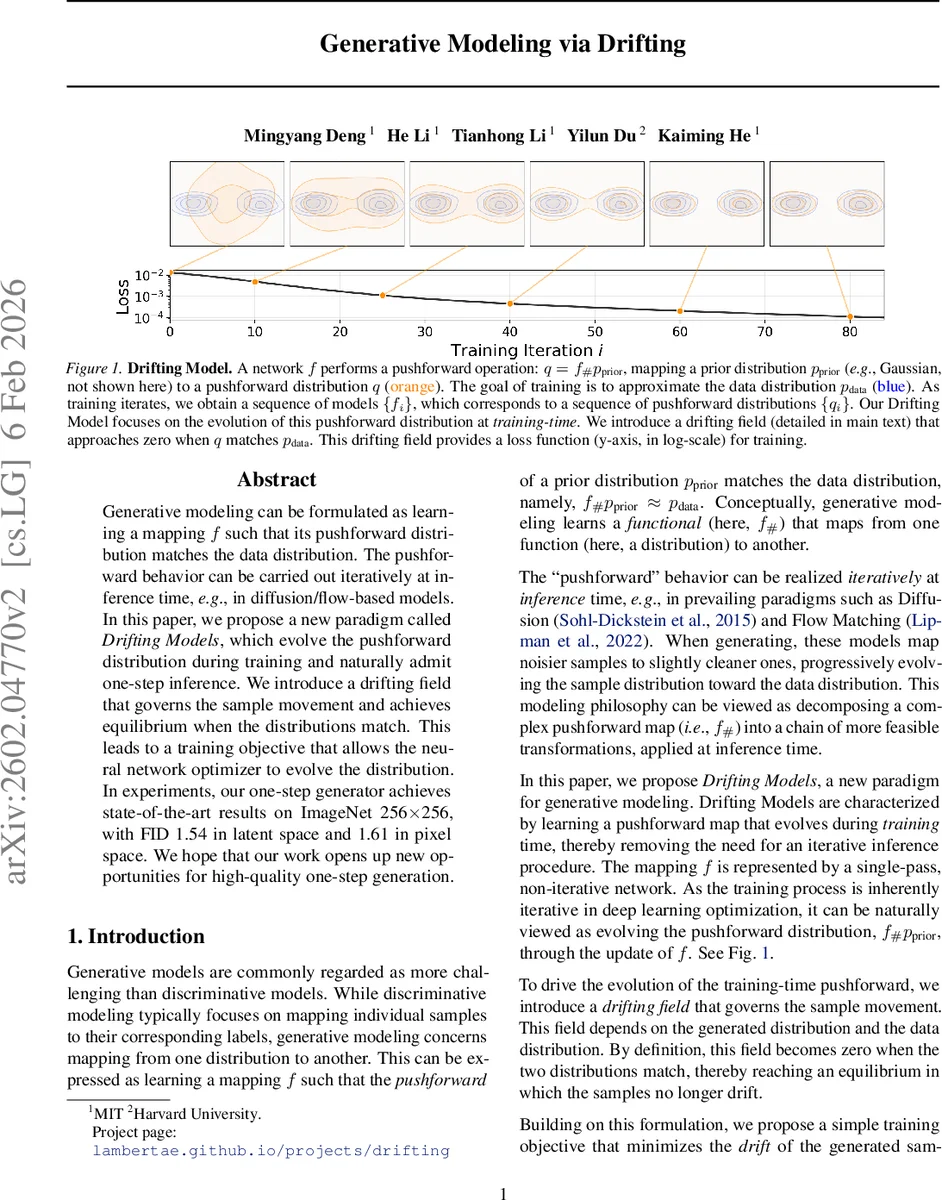
본 논문은 훈련 과정에서 푸시포워드 분포를 지속적으로 진화시키는 “드리프팅 모델”이라는 새로운 생성 모델 패러다임을 제안한다. 데이터와 생성 분포 사이의 차이를 나타내는 드리프팅 필드를 정의하고, 이 필드가 0이 되면 두 분포가 일치한다는 equilibrium 조건을 이용해 손실 함수를 설계한다. 결과적으로 한 번의 네트워크 평가만으로 고해상도 ImageNet(256×256) 이미지 생성이 가능하며, FID 1.54(잠재공간)·1.61(픽셀공간)이라는 최첨단 성능을 기록한다.
상세 분석
이 논문은 기존 확산·플로우 기반 모델이 추론 시 다단계 시뮬레이션을 필요로 하는 점을 비판하고, 훈련 자체를 “분포 진화” 과정으로 재구성한다는 근본적인 아이디어를 제시한다. 핵심은 두 확률분포 p(데이터)와 q(현재 생성분포) 사이의 차이를 벡터 필드 Vₚ,₍q₎(x) 로 정의하는 것이다. V는 anti‑symmetric 형태를 갖도록 설계돼, p = q 일 때 V ≡ 0이 되며 이는 물리학의 평형 상태와 유사한 조건이다. 구체적으로 저자는 attraction‑repulsion 메커니즘을 차용해 V₊ₚ(x)와 V₋_q(x)를 각각 데이터와 현재 샘플에 대한 평균 이동(mean‑shift) 벡터로 정의하고, V = V₊ₚ – V₋_q 로 결합한다. 여기서 사용되는 커널 k(x, y)=exp(−‖x−y‖/τ) 는 온도 파라미터 τ 로 조절되는 가우시안형 유사도이며, 정규화된 softmax 형태로 구현돼 InfoNCE와 유사한 대조학습 구조를 만든다.
훈련 목표는 손실 L = E_ε‖V(f_θ(ε))‖² 로, 이는 현재 샘플이 드리프팅 필드에 의해 얼마나 이동해야 하는지를 최소화한다는 의미다. 구현상 stop‑gradient 연산을 이용해 이전 파라미터 θ_i 로부터 얻은 “고정된 목표” x̂ = stopgrad(x + V) 를 만든 뒤, 현재 네트워크 출력 x 와 이를 비교하는 MSE 손실을 최적화한다. 이렇게 하면 역전파가 V 자체를 통과하지 않으면서도, V가 0에 가까워지도록 파라미터가 업데이트된다.
또한 저자는 이 손실을 원본 이미지 공간이 아니라 사전 학습된 자기지도 인코더 ϕ의 특징 공간에 적용한다. 즉, ‖ϕ(x) – stopgrad(ϕ(x) + V(ϕ(x)))‖² 를 최소화함으로써 고차원 이미지의 의미적 유사성을 보존한다. 다중 스케일·위치 특징을 동시에 활용해 풍부한 그래디언트를 제공하고, 이는 고해상도 이미지 생성에 필수적인 세밀한 구조를 학습하는 데 기여한다.
실험에서는 ImageNet 256×256 데이터셋에 대해 단일 스텝(1‑NFE) 생성 모델을 훈련시켰으며, 잠재공간에서 FID 1.54, 픽셀공간에서 FID 1.61을 달성했다. 이는 기존 단일‑스텝 GAN·VAE·Flow 기반 방법들을 크게 앞서는 수치이며, 다단계 확산 모델과도 경쟁할 만한 수준이다. 저자는 또한 드리프팅 필드 설계가 충분히 일반적이어서 다양한 커널·특징 추출기와 결합 가능함을 강조하고, 향후 고차원 데이터(비디오·3D 등)에도 확장 가능성을 제시한다.
전체적으로 이 논문은 “훈련‑시간 분포 진화”라는 새로운 관점을 도입해, 복잡한 미분 방정식 기반의 다단계 추론을 배제하고도 고품질 이미지를 한 번에 생성할 수 있음을 실증한다. 이는 생성 모델의 효율성·응용성을 크게 확대할 잠재력을 가진 혁신적 접근이라 평가할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기