디모: 이산 확산 기반 동작 생성 및 이해
초록
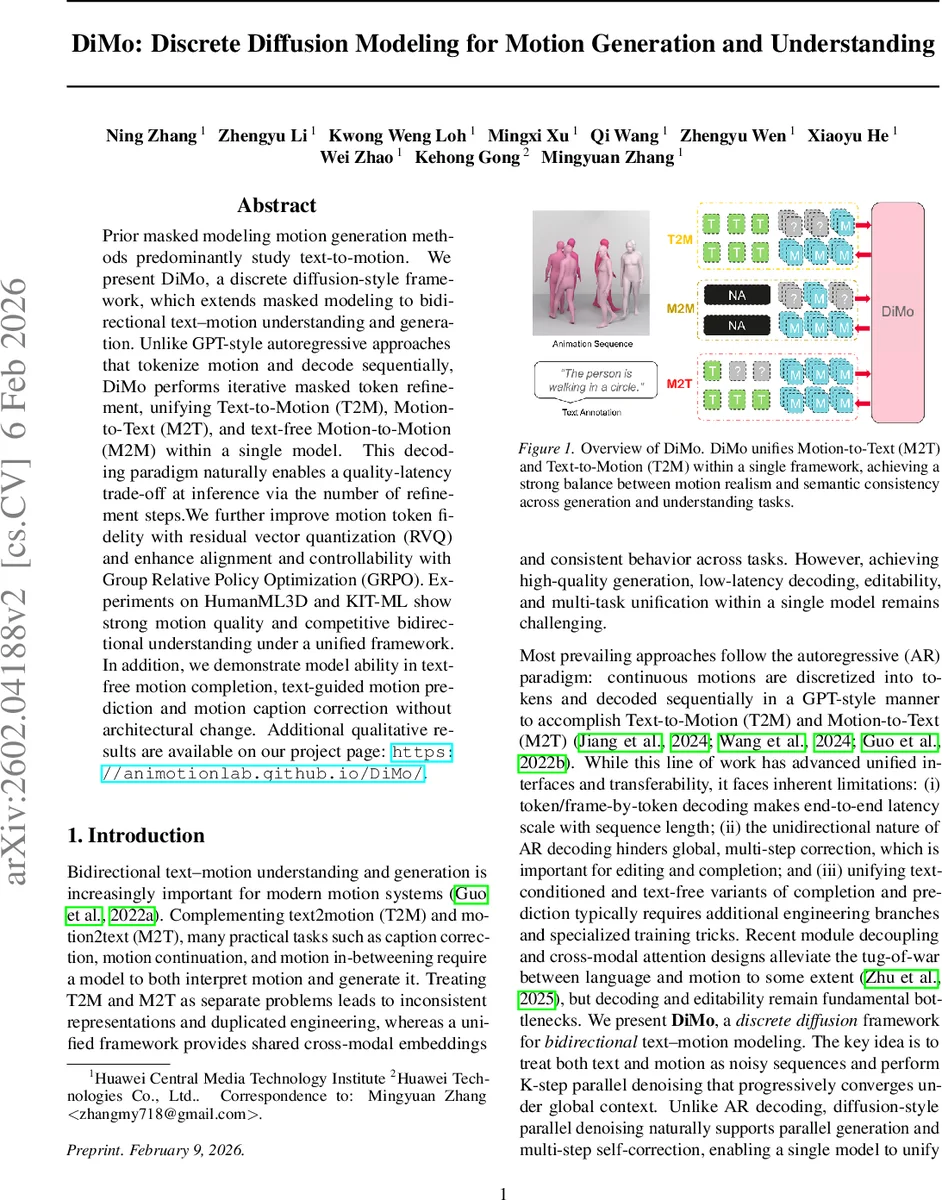
디모는 텍스트와 인간 동작을 이산 토큰으로 변환한 뒤, 마스크 기반 확산 과정을 통해 양방향 텍스트‑동작 변환을 수행하는 통합 모델이다. residual vector quantization(RVQ)으로 동작 토큰의 품질을 높이고, Group Relative Policy Optimization(GRPO)으로 텍스트‑동작 정렬과 제어성을 강화한다. 단계 수에 따라 품질‑지연 트레이드오프가 가능하며, HumanML3D와 KIT‑ML에서 텍스트‑동작 생성·이해 모두에서 경쟁력 있는 성능을 보인다.
상세 분석
디모는 기존 GPT‑style 자동회귀 방식이 갖는 순차적 디코딩 지연과 전역적인 수정 어려움을 해결하고자, 이산 확산(dLLM) 패러다임을 동작‑언어 모델링에 적용하였다. 핵심 아이디어는 텍스트와 동작을 동일한 이산 시퀀스로 취급하고, 일정 비율의 토큰을 무작위로 마스킹한 뒤 다단계(보통 K ≈ 10~20) 디노이징 과정을 통해 원본을 복원하도록 학습하는 것이다. 이 과정에서 모델은 전체 시퀀스에 대한 양방향 컨텍스트를 동시에 활용하므로, 초기 마스크 오류가 후속 단계에서 자동으로 정정될 수 있다.
동작 토큰화는 Residual Vector Quantization(RVQ)을 사용한다. RVQ는 다중 레벨 코드북을 순차적으로 적용해 압축률을 유지하면서도 양자화 오차를 크게 감소시킨다. 특히 인간 동작의 고주파 움직임(예: 손목 회전)까지 세밀히 보존할 수 있어, 후속 디코더가 복원한 토큰을 실제 3D 포즈로 변환했을 때 시각적으로 자연스러운 결과를 얻는다.
텍스트‑동작 정렬 및 제어성을 강화하기 위해 도입된 GRPO는 기존 PPO 기반 강화학습의 가치 네트워크를 생략하고, 후보 그룹 내에서 보상을 정규화한다. 이는 학습 효율성을 높이는 동시에, 텍스트와 동작 사이의 의미적 일치도를 직접 보상으로 활용할 수 있게 한다. 구체적으로 T2M에서는 생성된 동작을 사전 학습된 M2T 모델에 입력해 얻은 가짜 캡션과 실제 캡션 간 CLIP 코사인 유사도를 보상으로 사용하고, M2T에서는 동사 매칭과 CLIP 유사도, 길이 페널티를 결합한다.
다중 작업 스케줄링도 중요한 설계 포인트다. 배치 내 각 샘플을 T2M, M2T, M2M 중 하나에 무작위 할당함으로써, 모델이 텍스트‑동작 변환뿐 아니라 순수 동작 복원(완성·예측)까지 학습한다. 이로써 별도의 아키텍처 변경 없이 텍스트‑조건 없는 동작 완성, 텍스트‑조건 예측, 캡션 교정 등 다양한 파생 작업을 수행할 수 있다.
실험에서는 HumanML3D와 KIT‑ML 두 데이터셋에서 기존 MotionGPT, MotionGPT‑2, 그리고 최신 디퓨전 기반 텍스트‑동작 모델들과 비교했다. 품질‑지연 트레이드오프를 나타내는 파레토 곡선에서 디모는 적은 디노이징 단계(예: 4~6스텝)에서도 경쟁 모델보다 높은 R‑Precision·FID·Diversity를 기록했으며, 단계 수를 늘릴수록 품질이 점진적으로 향상되는 모습을 보였다. 또한 M2T 측면에서는 BLEU·ROUGE·CIDEr 점수에서 기존 방법과 동등하거나 약간 앞서는 결과를 얻었다.
전체적으로 디모는 (1) 마스크 기반 이산 확산을 통한 병렬 디코딩, (2) RVQ를 통한 고품질 동작 토큰화, (3) GRPO 기반 의미 정렬 강화라는 세 축을 결합해, 텍스트‑동작 양방향 모델링을 하나의 통합 프레임워크로 구현했다. 이는 실시간 애플리케이션에서 품질과 지연을 자유롭게 조절할 수 있는 유연성을 제공하며, 향후 멀티모달 로봇 제어, 가상 캐릭터 애니메이션 등 다양한 분야에 적용 가능성을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기