D²Quant: 저비트 가중치 양자화로 LLM 성능 회복하기
초록
**
본 논문은 LLM에 적용되는 가중치 전용 사후 훈련 양자화(PTQ)에서 4비트 이하로 낮출 때 발생하는 정확도 손실을 두 가지 원인(다운‑프로젝션 매트릭스 양자화 어려움, 양자화에 따른 활성값 편향)으로 분석하고, 이를 해결하기 위해 Dual‑Scale Quantizer와 Deviation‑Aware Correction을 결합한 D²Quant 프레임워크를 제안한다. 실험 결과, 2비트 양자화에서도 기존 최첨단 방법보다 평균 3%p 이상 높은 정확도를 달성한다.
**
상세 분석
**
D²Quant은 LLM의 가중치 전용 PTQ에서 흔히 나타나는 두 가지 병목을 정량적으로 파악한다. 첫 번째는 Transformer 구조에서 MLP 블록의 다운‑프로젝션( W_down ) 행렬이다. 다운‑프로젝션은 입력 차원을 축소하는 역할을 하는데, 그 값들의 동적 범위가 넓어 채널별 정규화만으로는 양자화 오차가 크게 누적된다. 기존 방법은 이 행렬에 별도의 높은 비트를 할당하거나, 전체 모델에 균일한 스케일링을 적용해 완화했지만, 비트 예산을 초과하거나 연산 복잡도가 증가한다는 한계가 있었다. 논문은 “등가 스케일 변환”을 도입해 W_up 과 W_down 사이에 채널별 스케일 η 를 삽입함으로써, W_up 은 기존 스케일링에 흡수되고 W_down 만이 실제로 스무딩 효과를 얻도록 설계한다. 이때 η는 별도의 학습 파라미터가 아니라, 양자화 과정 중에 최적화되는 Dual‑Scale Quantizer (DSQ) 로 구현된다. DSQ는 기존 per‑channel 양자화에 추가적인 column‑wise 스케일 s_c 를 곱하는 형태이며, 양자화 연산 Q(·)와 s_c 를 교대로 고정‑최적화하는 반복 알고리즘을 사용한다. 최종적으로 s_c 는 W_up 의 스케일에 흡수되어 런타임 비용이 전혀 증가하지 않는다.
두 번째 병목은 가중치만 양자화했음에도 불구하고 활성값이 변형되는 현상이다. 특히 Attention 블록을 양자화하면, 이후에 위치한 Post‑Attention LayerNorm에서 평균값이 크게 이동한다는 것이 실험적으로 확인되었다. 반면 MLP 블록을 양자화했을 때는 Pre‑LayerNorm에서의 편차가 비교적 무작위적이며 평균 이동이 미미하다. 이를 정량화하기 위해 논문은 Signal‑to‑Noise Ratio (SNR) 를 정의하고, Post‑Attention LayerNorm의 SNR이 현저히 높다는 사실을 제시한다. 이러한 관찰에 기반해 Deviation‑Aware Correction (DAC) 를 설계한다. DAC는 Post‑Attention LayerNorm에 평균 보정(bias alignment) 항을 삽입해, 양자화로 인한 평균 이동을 직접 상쇄한다. 보정값은 캘리브레이션 데이터셋을 통해 추정되며, LayerNorm 연산에 가벼운 추가 연산만을 요구한다. 이론적으로는 보정 전후의 평균 제곱 오차가 SNR에 비례해 감소함을 증명한다.
전체 D²Quant 파이프라인은 (1) 사전 캘리브레이션 단계에서 각 레이어별 활성값 통계와 다운‑프로젝션 스케일을 수집하고, (2) DSQ를 통해 다운‑프로젝션을 dual‑scale 방식으로 양자화하며, (3) DAC를 적용해 Post‑Attention LayerNorm의 평균을 보정한다. 중요한 점은 두 기법 모두 비트 예산을 늘리지 않으며 기존 inference 그래프에 거의 영향을 주지 않는다는 것이다.
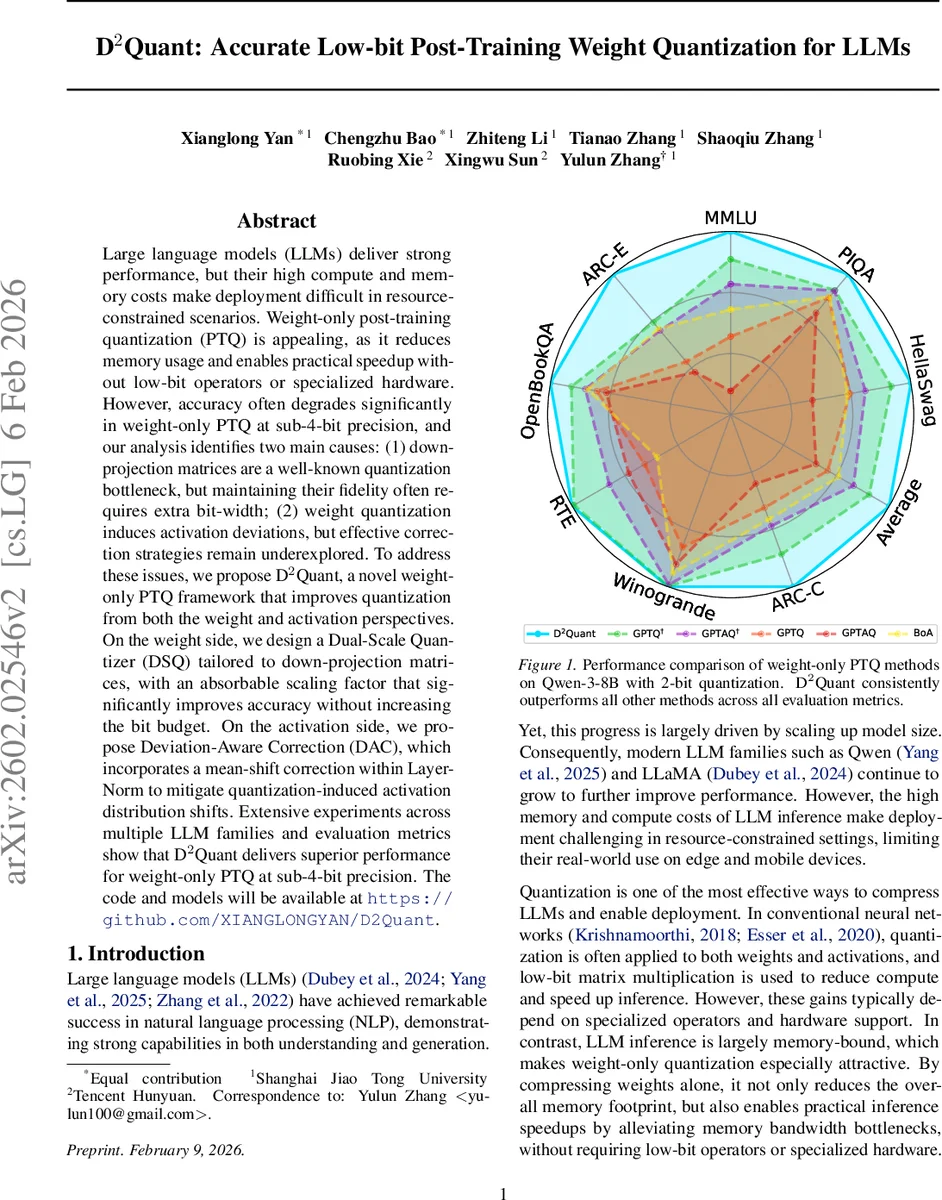
실험에서는 Qwen‑3‑8B, LLaMA‑3‑8B, GPT‑NeoX 등 다양한 모델에 2‑bit, 3‑bit 가중치 양자화를 적용했다. 평가 지표는 MMLU, HellaSwag, PIQA 등 7개의 zero‑shot 벤치마크이며, D²Quant은 2‑bit 설정에서 평균 57.22% 정확도를 기록해, 기존 최첨단 방법(54.05%)보다 약 3%p 상승한다. 특히 attention‑heavy 작업에서 DAC가 큰 효과를 보였으며, DSQ는 다운‑프로젝션이 많은 MLP 레이어에서의 손실을 크게 감소시켰다. 또한, 연산량과 메모리 사용량은 기존 PTQ와 동일하거나 약간 감소했으며, 추가적인 하드웨어 지원 없이도 실시간 추론이 가능함을 입증했다.
요약하면, D²Quant은 (1) 다운‑프로젝션 전용 dual‑scale 양자화로 비트 효율성을 극대화하고, (2) 활성값 평균 이동을 정밀하게 보정하는 DAC로 양자화‑유도 편차를 최소화한다. 두 접근법을 결합함으로써, 저비트(2‑3‑bit) 가중치 양자화에서도 LLM의 원본 성능에 근접하거나 이를 초과하는 결과를 얻었다. 이는 메모리·대역폭이 제한된 엣지 디바이스나 모바일 환경에서 대형 LLM을 실용적으로 배포할 수 있는 중요한 기술적 진전이라 할 수 있다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기