스스로 학습 커리큘럼을 만들며 추론 한계 돌파
초록
본 논문은 사전학습된 대형 언어모델이 스스로 난이도 높은 수학 문제를 풀지는 못하더라도, 내부에 잠재된 지식을 활용해 학습을 촉진할 수 있는 “스텝스톤” 문제들을 자동 생성하는 메타‑강화학습 프레임워크 SOAR를 제안한다. 교사 모델이 학생 모델에게 합성 문제를 제공하고, 학생이 실제 어려운 문제 집합에서 보이는 성능 향상을 교사의 보상으로 삼음으로써, 외부 데이터 없이도 학습 정체기를 탈피한다는 실험 결과를 제시한다.
상세 분석
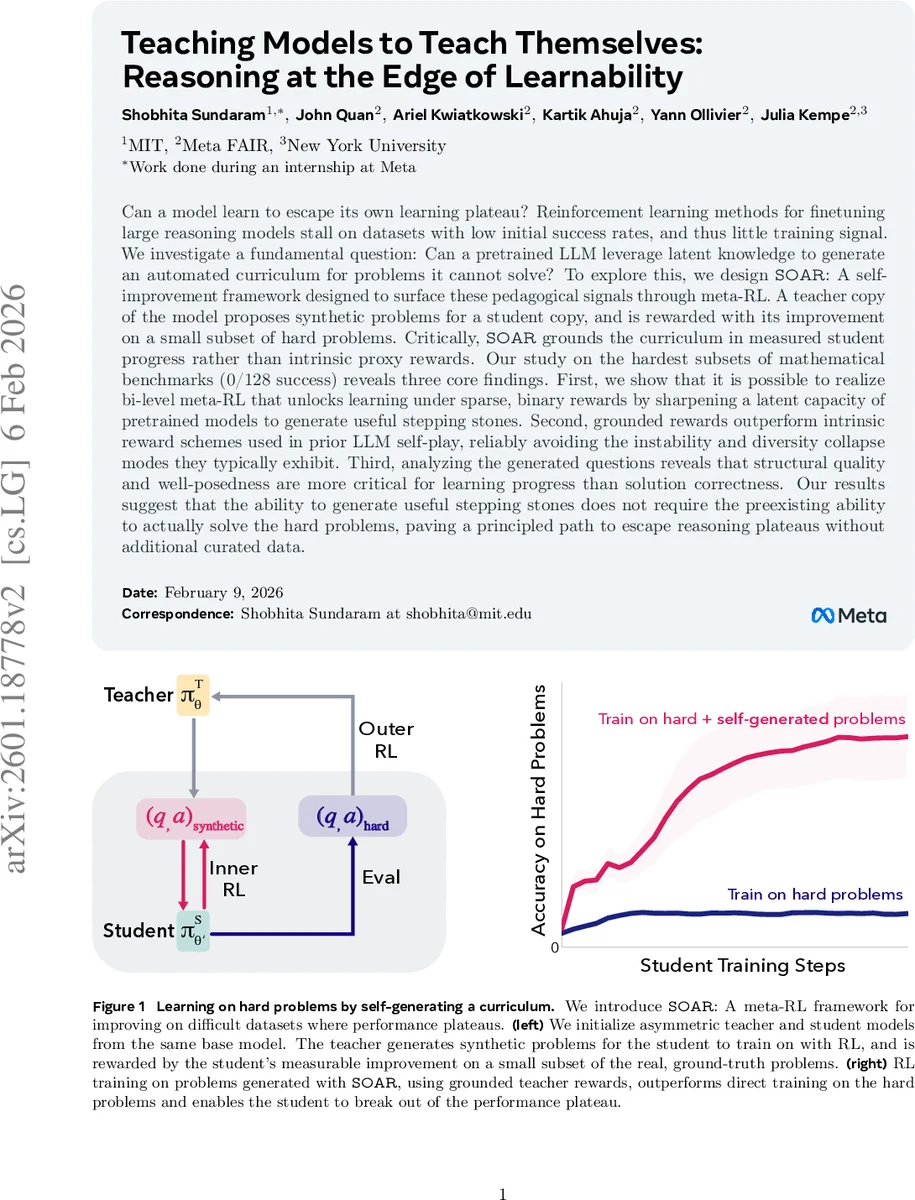
SOAR는 교사‑학생 비대칭 구조를 갖는 2단계 메타‑RL 시스템으로, 외부의 정답 검증 없이도 “질문‑답변” 쌍을 생성한다는 점에서 기존의 자체‑플레이 방식과 근본적으로 차별된다. 교사 모델(π_T)는 RLOO 기반 정책으로 무작위 롤아웃을 통해 다수의 합성 문제를 만든다. 이때 질문과 답변을 동시에 생성하도록 프롬프트를 설계했으며, 파싱 실패 시 재시도 메커니즘을 도입해 데이터 손실을 최소화한다. 생성된 문제들은 일정 크기의 배치(X_k)로 묶여 학생 모델(π_S)의 내부 RL 루프에 투입된다. 학생은 표준 RLVR(예: REINFORCE, RLOO)으로 합성 문제에 대해 학습하고, 학습 후에는 원본의 어려운 문제 집합 D_train에서 제한된 샘플(Q_R)을 평가한다. 교사의 보상 R(X_k)은 “학생이 Q_R에 대해 달성한 정확도 향상 – 초기 학생 정확도”로 정의되며, 이는 블랙박스 형태의 외부 신호이면서도 실제 학습 진행을 직접 반영한다.
핵심 기술적 기여는 두 가지이다. 첫째, 내부 루프를 명시적으로 역전파하지 않고도 외부 보상을 통해 교사를 최적화한다는 점이다. 기존 메타‑학습에서는 내부 학습 과정을 미분해 메타‑그라디언트를 계산해야 했지만, SOAR는 RLOO의 off‑policy 특성을 활용해 교사 업데이트를 샘플 기반 보상에만 의존한다. 둘째, 보상 설계에서 “내재적 난이도 추정”이나 “학습 가능성 점수”와 같은 프록시를 배제하고, 실제 성능 개선을 직접 측정함으로써 보상 해킹이나 질문 다양성 붕괴(diversity collapse)를 방지한다. 실험에서는 Llama‑3.2‑3B‑Instruct를 기반 모델로 사용했으며, 수학 벤치마크(MATH, HARP)의 가장 어려운 서브셋(성공률 0/128)에서 교사‑학생 루프를 600번 이상 반복했다. 결과적으로 Pass@1이 4배, Pass@32가 2배 이상 상승했으며, 교사가 생성한 질문이 다른 미조정 데이터셋에서도 전이 학습 효과를 보였다.
흥미로운 부수 발견은 “문제 구조와 잘 정의된 형태”가 정답의 정확성보다 학습에 더 큰 영향을 미친다는 점이다. 교사가 만든 질문 중 답변이 부정확해도, 질문 자체가 학생에게 새로운 연산 패턴이나 개념을 탐색하도록 유도하면 성능이 향상된다. 이는 LLM이 “해답을 알지 못해도” 해당 도메인의 잠재적 지식을 활용해 학습 경로를 스스로 설계할 수 있음을 시사한다. 또한, 교사와 학생을 동일한 초기 파라미터에서 시작함으로써, 모델이 자체적인 지식 구조를 재구성하고, 메타‑RL이 그 구조를 “가시화”하는 역할을 수행한다는 메타인지적 해석도 가능하다.
전반적으로 SOAR는 (1) 이중 메타‑RL 루프를 통한 효율적 바이레벨 최적화, (2) 외부 검증 없이도 학습 진행을 직접 측정하는 보상 메커니즘, (3) 질문의 형식적·구조적 품질이 학습에 미치는 영향 등 세 축을 통해 기존 자기‑플레이 기반 커리큘럼 생성의 한계를 극복한다. 향후 연구에서는 더 큰 모델, 다중 도메인(프로그래밍, 과학)으로 확장하고, 교사‑학생 비대칭성을 강화해 교사의 탐색 능력을 더욱 촉진하는 방안을 모색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기