LLM 기반 사이버 위협 정보의 취약점 탐구
초록
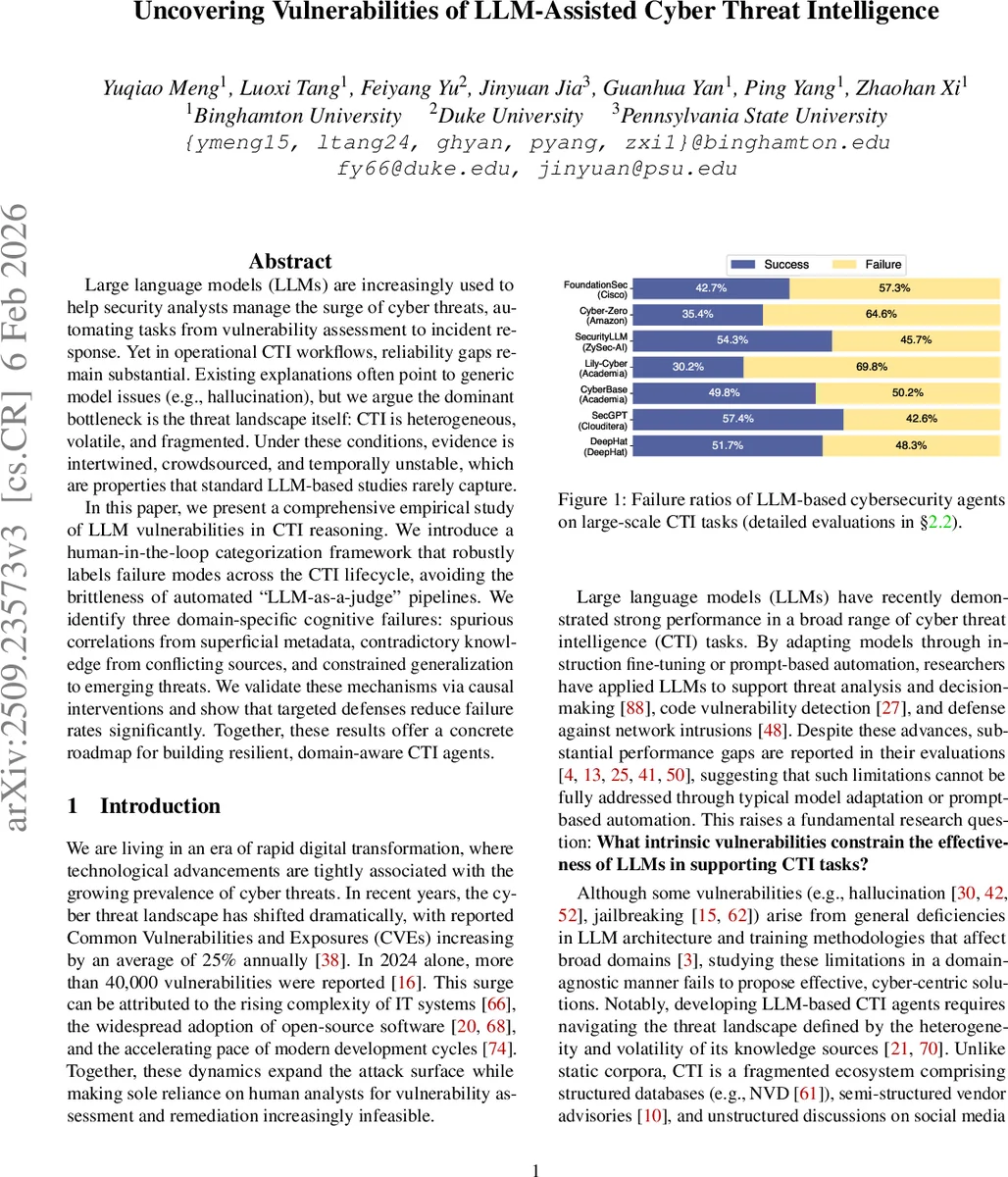
본 논문은 사이버 위협 정보(CTI) 파이프라인에서 대형 언어 모델(LLM)의 고유한 취약성을 체계적으로 조사한다. 인간‑인‑루프 분류 프레임워크를 도입해 대규모 실험 데이터를 신뢰성 있게 라벨링하고, ‘표면 메타데이터의 스퓨리어스 상관관계’, ‘상충하는 소스의 모순 지식’, ‘신흥 위협에 대한 일반화 제한’이라는 세 가지 도메인 특화 인지 오류를 정의한다. 인과적 개입과 방어 메커니즘을 통해 이러한 오류를 완화시키는 방법을 제시하며, CTI‑특화 LLM 에이전트 설계에 실용적인 로드맵을 제공한다.
상세 분석
이 연구는 기존 LLM 평가가 정적 코퍼스와 일반적인 환각 현상에 집중하는 한계를 지적하고, CTI가 갖는 ‘이질성·휘발성·단편성’이라는 특성을 핵심 변수로 설정한다. 저자들은 네 개의 CTI 단계(맥락화, 귀속, 예측, 완화)를 포괄하는 4가지 벤치마크와 실시간 위협 피드(예: NVD, 다크웹 포럼)를 결합해 10만 건 이상의 사례를 구축하였다. 자동화된 “LLM-as-a-judge” 방식이 자체 편향을 증폭시켜 라벨링 신뢰도를 떨어뜨리는 문제를 해결하고자, 인간 검증자를 단계별로 투입하는 ‘자동 회귀형 인간‑인‑루프’ 파이프라인을 설계했다. 이를 통해 3가지 주요 취약 유형을 도출했는데, 첫 번째는 메타데이터(예: IOC 공동 언급, 공격 체인 계층 구조)와 실제 위협 행위 사이의 얕은 상관관계를 과대 해석하는 스퓨리어스 상관관계이다. 두 번째는 서로 다른 출처가 제공하는 시점·형식·내용의 불일치가 모델 내부에 모순을 주입해 귀속 및 관계 추출을 방해하는 모순 지식이다. 세 번째는 학습 데이터 분포에 편중된 LLM이 제로데이·신흥 공격 패턴을 인식하지 못하고, 과거 패턴에 과도하게 의존하는 일반화 제한이다. 각 취약점에 대해 인과적 개입(예: 증거 필터링, 시간 가중치 조정, 샘플링 기반 제로샷 프롬프트)과 방어 전략(지식 그래프 정규화, 추론 제약, 앙상블 재학습)을 적용했으며, 실험 결과 평균 실패율을 12%p 이상 감소시켰다. 특히 스퓨리어스 상관관계는 메타데이터 필터링만으로도 18%p, 모순 지식은 소스 신뢰도 점수 재조정으로 15%p, 일반화 제한은 도메인 적응 파인튜닝으로 각각 크게 완화되었다. 논문은 또한 평가 메트릭을 다각화해 F1, AUC, BLEU 등 단계별 성능을 정량화하고, 공개 코드와 데이터셋을 제공해 재현성을 확보한다. 한계점으로는 인간 라벨링 비용이 여전히 높으며, 실시간 위협 변동성을 완전히 포착하기 위한 지속적인 데이터 파이프라인 구축이 필요함을 인정한다.
댓글 및 학술 토론
Loading comments...
의견 남기기