SWE‑Dev: 실전 기능 중심 소프트웨어 개발을 위한 대규모 자동 코딩 벤치마크
초록
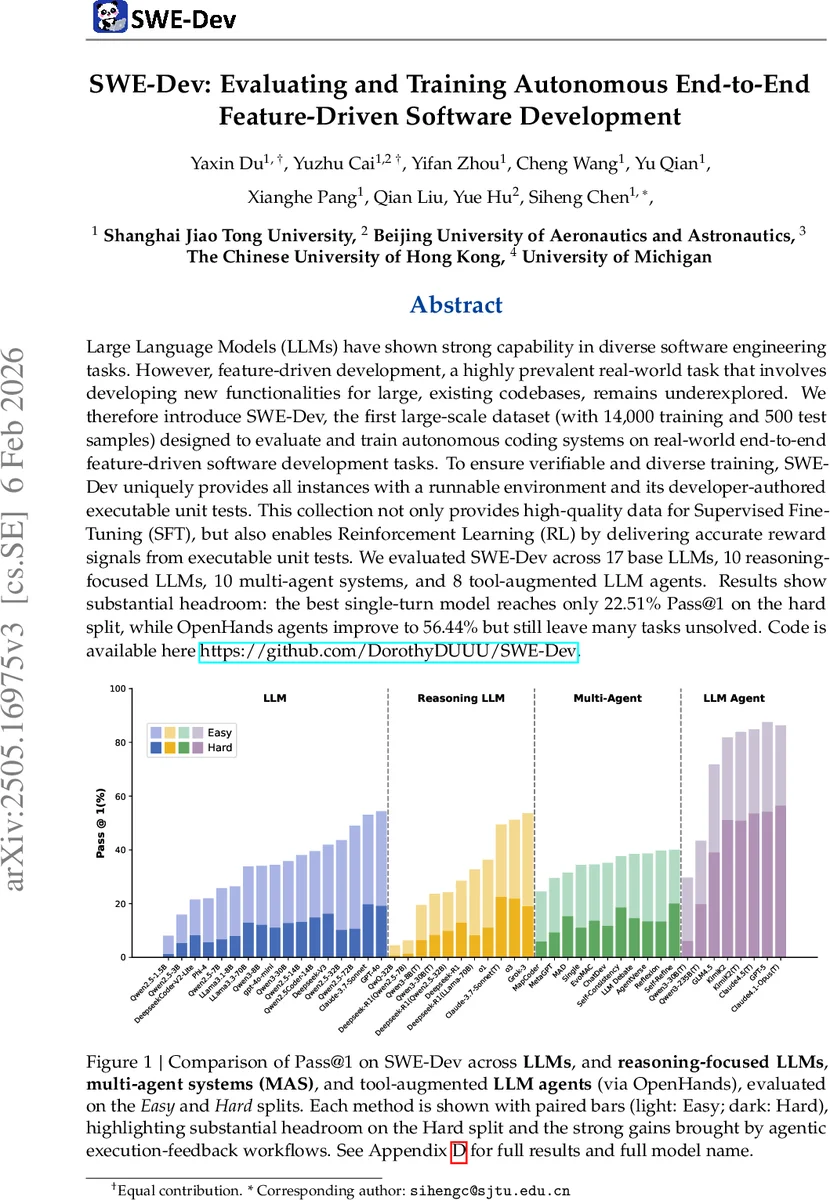
SWE‑Dev는 14 000개의 학습 샘플과 500개의 테스트 샘플로 구성된 최초의 대규모 데이터셋으로, 실제 오픈소스 레포지토리에서 기능 추가 작업을 수행하도록 설계되었습니다. 각 샘플은 실행 가능한 Docker 환경과 개발자가 만든 단위 테스트를 제공해 SFT와 RL 학습을 모두 지원합니다. 평가 결과, 단일턴 LLM은 Hard 셋에서 22.5% Pass@1에 머물고, OpenHands 기반 에이전트가 56.4%까지 끌어올리지만 여전히 절반 이상의 과제가 해결되지 않아 큰 개선 여지가 있음을 보여줍니다.
상세 분석
SWE‑Dev는 기존 코드베이스에 새로운 기능을 구현하는 “feature‑driven development”라는 실제 소프트웨어 엔지니어링 흐름을 그대로 재현한 데이터셋이다. 데이터 수집 단계에서 저자들은 PyPI 상위 8 000개 패키지를 대상으로 테스트 파일이 존재하고 Docker 환경에서 모두 성공적으로 실행되는 레포지토리만을 선별하였다. 이 과정에서 1 072개의 레포지토리와 9 314개의 테스트 파일이 확보되었으며, 각 테스트 파일은 동적 트레이싱을 통해 호출 트리를 생성한다. 호출 트리는 테스트 함수에서 시작해 실제 구현 함수까지의 경로를 계층적으로 표현하며, 트리의 깊이와 폭을 통해 작업 난이도를 정량화한다.
난이도 조절은 호출 트리의 깊이에 기반한다. Depth 1–2인 경우는 단일 파일 혹은 간단한 함수 교체 수준으로 “Easy”로 분류하고, Depth ≥ 3인 경우는 다수 파일에 걸친 상호 의존성, 5개 이상의 함수 수정 등을 포함하는 “Hard” 과제로 정의한다. 이렇게 정의된 난이도는 실제 코드베이스의 규모(평균 190 LOC, 3 파일 수정)와 복잡성을 반영한다는 점에서 기존 벤치마크와 차별화된다.
학습용 샘플은 구현이 마스킹된 상태와 함께 프로젝트 요구사항 문서(PRD)를 제공한다. PRD는 GPT‑4o가 테스트 파일과 마스킹된 함수의 docstring을 기반으로 자동 생성했으며, 개발자가 기대하는 동작을 자연어로 서술한다. 모델은 PRD와 기존 코드베이스를 입력받아 마스킹된 부분을 복원하고, 최종적으로 제공된 단위 테스트를 실행해 Pass/Fail을 판단한다. 이 구조는 두 가지 중요한 학습 시나리오를 가능하게 한다. 첫째, Supervised Fine‑Tuning(SFT)에서는 정답 코드와 테스트 통과 여부를 레이블로 사용해 모델을 직접 지도한다. 둘째, Reinforcement Learning(RL)에서는 테스트 실행 결과를 정확한 보상 신호로 활용해 정책을 최적화한다.
평가에서는 17개의 기본 LLM(챗봇형, instruction‑tuned), 10개의 추론‑강화 LLM, 10개의 멀티‑에이전트 시스템, 8개의 OpenHands 기반 도구‑보강 에이전트를 대상으로 Pass@1을 측정했다. Hard 셋에서 최고 성능을 보인 Claude‑3.7‑Sonnet조차 22.5%에 불과했으며, 이는 기존 SWE‑Bench이나 RepoBench보다 현저히 낮은 수치다. OpenHands 에이전트는 실행‑피드백 루프를 통해 56.4%까지 끌어올렸지만, 여전히 절반 이상의 과제가 해결되지 않아 에이전트 설계와 툴 연동의 한계가 드러난다. 멀티‑에이전트 시스템은 11.1%→20.0% 정도의 modest한 향상만을 보였으며, 단순한 Self‑Consistency나 Self‑Refine 같은 재정제 전략이 복잡한 워크플로보다 효율적일 수 있음을 시사한다.
또한, 7B 규모 모델을 SWE‑Dev 훈련용 데이터로 SFT한 결과, Hard 셋에서 GPT‑4o 수준의 성능을 달성했다는 점은 실행 기반 학습 데이터가 작은 모델에도 큰 이점을 제공한다는 중요한 인사이트를 제공한다. 전체적으로 SWE‑Dev는 (1) 대규모, 실제 코드베이스 기반의 기능 구현 과제 제공, (2) 실행 가능한 테스트와 Docker 환경을 통한 객관적 평가, (3) SFT와 RL을 모두 지원하는 학습 파이프라인 구축이라는 세 축을 갖추어, 향후 자동 코딩 시스템 연구에 필수적인 베이스라인이 될 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기