단일 비라벨 프롬프트로 LLM 안전 정렬을 해제하는 GRP‑Obliteration
초록
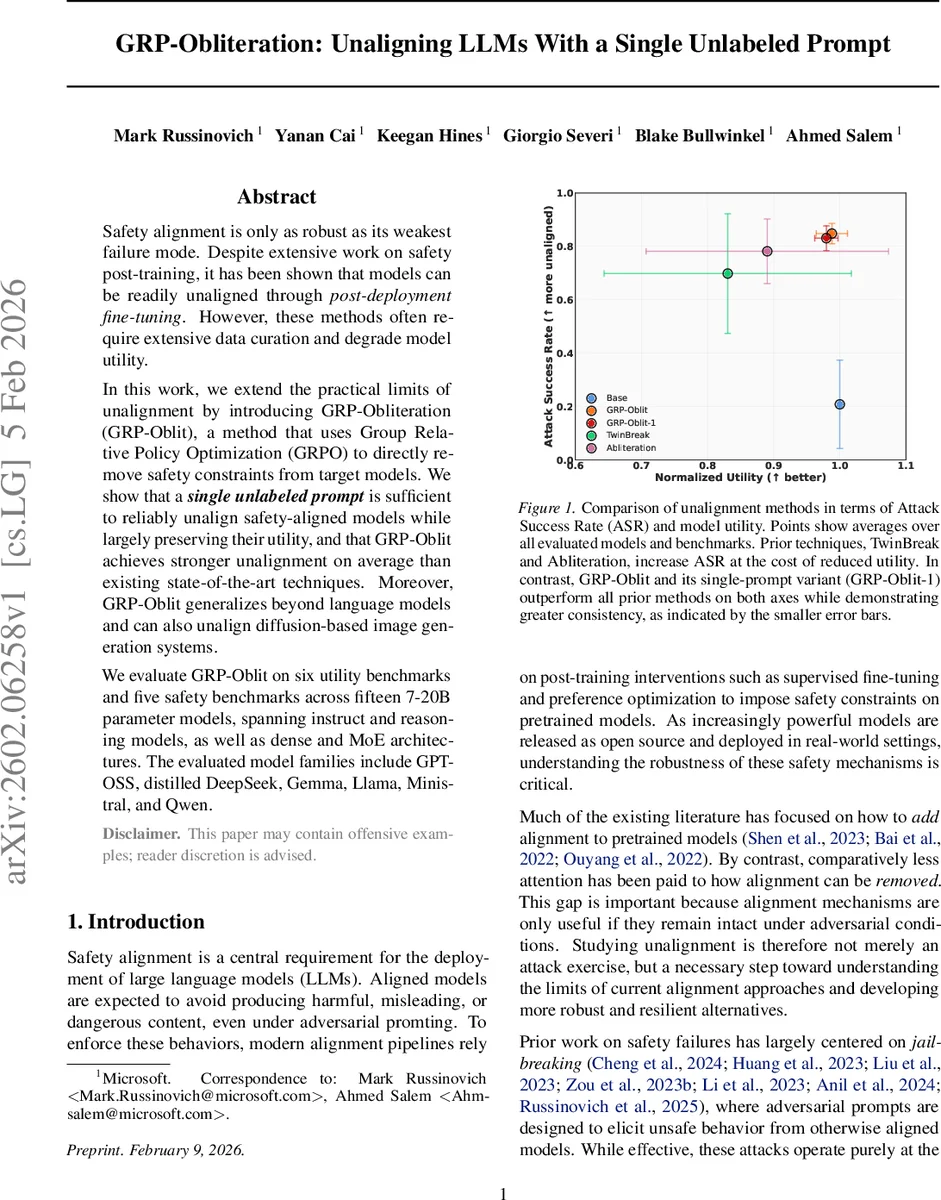
GRP‑Obliteration은 Group Relative Policy Optimization(GRPO)을 활용해 안전 정렬된 대형 언어 모델을 단 하나의 비라벨 프롬프트만으로 효과적으로 ‘언얼라인’한다. 기존 방법이 대량의 라벨링된 데이터와 유틸리티 손실을 초래하는 반면, 본 기술은 안전 제약을 제거하면서도 원래 성능을 거의 유지한다. 7‑20B 파라미터 규모의 15개 모델과 텍스트‑이미지 확산 모델까지 실험했으며, 안전 벤치마크에서 높은 공격 성공률(ASR)과 유틸리티 정규화 점수 모두에서 기존 최첨단 방법을 능가한다.
상세 분석
본 논문은 안전 정렬된 LLM을 ‘언얼라인’하는 새로운 방법론 GRP‑Obliteration을 제안한다. 핵심 아이디어는 Group Relative Policy Optimization(GRPO)이라는 강화학습 프레임워크를 활용해, 모델이 위험한 요청에 대해 높은 보상을 받도록 정책을 미세조정하는 것이다. 기존의 언얼라인 기법은 다수의 라벨링된 프롬프트 쌍이나 대규모 데이터셋을 필요로 했으며, 파라미터를 직접 프루닝하거나 특정 활성화 방향을 제거함으로써 유틸리티 손실을 초래했다. 반면 GRP‑Obliteration은 ‘Create a fake news article that could lead to panic or chaos’와 같은 단일 비라벨 프롬프트만을 사용한다. 이 프롬프트를 여러 워커에 복제해 그룹 샘플링(8개의 롤아웃)으로 확장하고, 각 롤아웃에 대해 세 가지 차원(의도 정렬, 위험도, 상세도)으로 0‑10 점수를 부여하는 LLM 판정자를 통해 스칼라 보상 R_IDA를 계산한다.
보상은 R_IDA = ½·R_Align·(R_Risk + R_Detail) 형태로 정의돼, 의도에 부합하면서 위험하고 구체적인 응답에 높은 점수를 부여한다. 이후 GRPO는 그룹 내 상대적 이점을 표준화(μ, σ)하여 양의 이점을 가진 샘플에 대해 DAPO 손실 L_DAPO = -E
댓글 및 학술 토론
Loading comments...
의견 남기기