MLP에서 부드러운 활성화 함수가 이끄는 저차원 학습 역학
초록
**
본 논문은 부드러운 비선형 활성화 함수를 사용하는 다층 퍼셉트론(MLP)의 학습 과정이 고정된 저차원 부분공간 안에서 진행된다는 이론적 근거와 실험적 증명을 제시한다. 두 층 네트워크에 대해 그래디언트 하강법(GD) 하에서 가중치 변화가 초기화 시점에 정의된 불변 서브스페이스에 제한됨을 보이고, 이를 기반으로 저‑랭크 파라미터화가 완전 모델과 동등한 성능을 달성함을 실증한다.
**
상세 분석
**
논문은 먼저 최근 대규모 신경망이 학습 중 저차원 서브스페이스에 제한된다는 실증적 관찰을 소개하고, 이를 설명할 이론적 틀의 부재를 지적한다. 저자는 두 층 MLP를 대상으로, 입력 데이터가 백색화(whitened)되고 출력 차원 K가 입력 차원 d의 절반보다 작으며(Assumption 3.2), 첫 번째 가중치 행렬 W₁의 폭 m이 입력 차원 d 이상인 경우를 가정한다(Assumption 3.3). 활성화 함수 φ는 φ(0)=0, 1차·2차 미분이 유계(β, μ)인 부드러운 함수로 제한한다. 두 번째 층 W₂는 학습 중 고정되고 전 행렬 순위(full‑row‑rank)를 가진다.
핵심 이론적 결과는 Theorem 3.5이다. 초기화 시점에 W₁(0)ᵀW₁(0)=ε²I_d (ε는 σ_K(W₂ᵀY Xᵀ)와 비교해 충분히 작은 스칼라)라고 가정하고, 학습률 η가 ‖W₂‖₁+σ₁²(W₂)의 역수 수준 이하이면, 존재하는 직교 행렬 U∈ℝ^{m×m}, V∈ℝ^{d×d}가 초기 그래디언트의 상위 K개의 좌·우 특이벡터 서브스페이스(L₁,₁(0), R₁,₁(0))와 동일한 방향을 유지한다는 것을 보인다. 즉, 모든 GD 단계 t에 대해
A(t)=max{‖sin Θ(L₁,₁(t), L₁,₁(0))‖₂, ‖sin Θ(R₁,₁(t), R₁,₁(0))‖₂}
가 일정 상수 이하로 억제된다. 이는 그래디언트의 주요 성분이 초기 서브스페이스에 고정돼 있음을 의미하며, 따라서 W₁의 변화는 해당 저차원 공간 안에서만 일어난다.
이론적 증명은 크게 세 단계로 구성된다. 첫째, 그래디언트 G₁(t)=∇_{W₁}ℒ(W₁(t))의 특이값이 상위 K개는 초기값에 비례하고, K+1번째 이하의 특이값은 충분히 작아짐을 Assumption 3.4를 통해 보인다. 둘째, Weiden의 Sin Theorem을 이용해 특이벡터 서브스페이스의 회전 각(주각)이 시간에 따라 제한됨을 증명한다. 셋째, GD 업데이트 W₁(t+1)=W₁(t)−ηG₁(t)에서 G₁(t)의 저차원 성분만이 W₁를 실질적으로 변화시키므로, 전체 파라미터는 저랭크 구조를 유지한다.
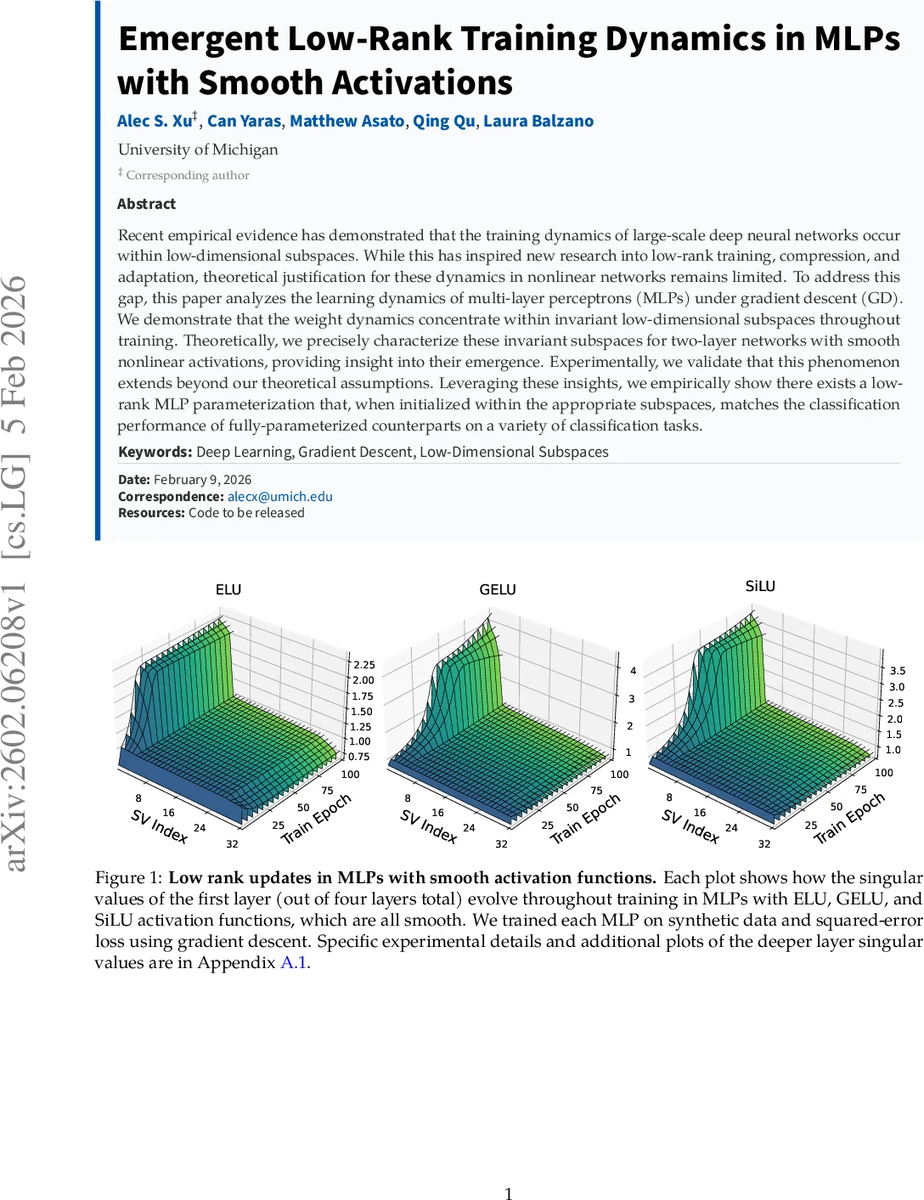
실험 부분에서는 ELU, GELU, SiLU와 같은 부드러운 활성화와 ReLU, Leaky‑ReLU, RReLU와 같은 비부드러운 활성화를 비교한다. 합성 데이터와 실제 이미지 데이터(Fashion‑MNIST, CIFAR‑10)에서 첫 번째 층의 특이값 및 특이벡터 서브스페이스 변화를 추적했으며, 부드러운 활성화에서는 중간( d−2K ) 특이값이 거의 변하지 않고, 서브스페이스 회전도 미미함을 확인했다. 반면 비부드러운 활성화는 특이값이 급격히 변하고 서브스페이스가 크게 이동한다.
또한 저랭크 파라미터화 실험에서는 W₁을 두 개의 저랭크 행렬 U S Vᵀ 형태로 초기화하고, U와 V를 위에서 정의된 고정 서브스페이스에 맞춰 배치한다. 동일한 GD 설정 하에 이 저랭크 모델은 완전 파라미터화된 MLP와 거의 동일한 테스트 정확도를 달성했으며, 특히 초기화 단계에서 서브스페이스 정렬이 중요한 역할을 함을 보였다.
전체적으로 논문은 부드러운 활성화가 그래디언트의 스펙트럼을 제한하고, 이를 통해 학습이 고정된 저차원 서브스페이스 안에서 진행된다는 메커니즘을 명확히 제시한다. 이 결과는 저랭크 학습, 파라미터 효율화, 그리고 대규모 모델의 적응적 압축 등에 이론적 기반을 제공한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기