긴 컨텍스트를 강제하는 일관된 자동회귀 비디오 생성
초록
본 논문은 짧은 윈도우만 보는 교사 모델과 긴 롤아웃을 수행하는 학생 모델 사이의 불일치를 해소하기 위해, 전체 생성 이력을 볼 수 있는 장기 컨텍스트 교사를 도입한다. 교사‑학생 구조를 ‘컨텍스트 포싱(Context Forcing)’이라 명명하고, 시각적 중복을 줄이는 슬로우‑패스트 메모리 아키텍처를 설계해 20초 이상(최대 2분) 지속되는 비디오에서도 일관성을 유지한다. 실험 결과, 기존 LongLive·Infinite‑RoPE 대비 2‑10배 긴 컨텍스트를 활용해 장기 일관성 지표와 정성적 품질 모두에서 우수함을 입증한다.
상세 분석
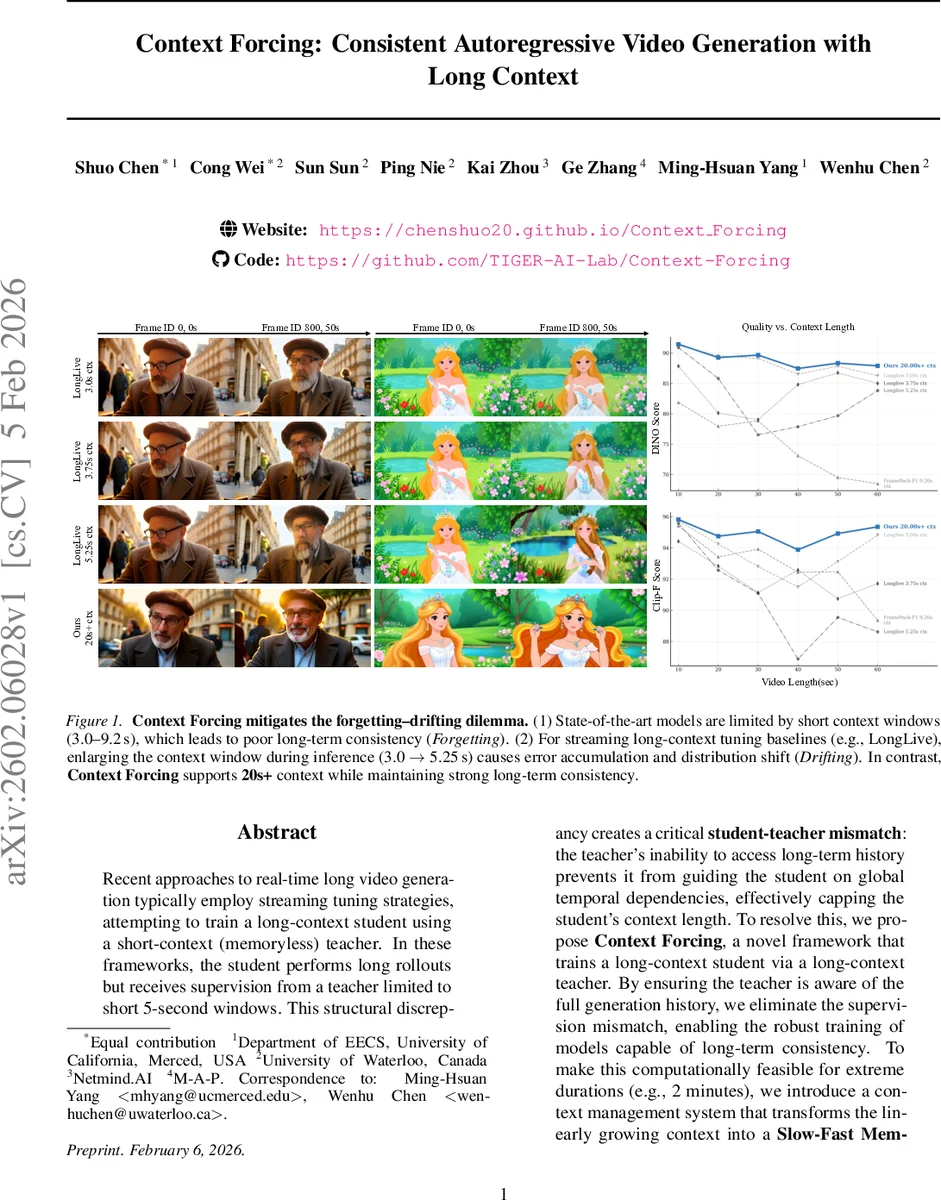
이 논문은 현재 실시간 장기 비디오 생성에서 흔히 나타나는 ‘학생‑교사 불일치(student‑teacher mismatch)’ 문제를 정확히 짚어낸다. 기존 스트리밍 튜닝 방식은 5초 정도의 짧은 윈도우만을 보는 메모리리스 교사를 사용해, 학생이 수십 초에 걸친 롤아웃을 수행하더라도 교사는 장기 의존성을 파악하지 못한다. 결과적으로 학생은 ‘포기(forgetting)’와 ‘드리프팅(drifting)’ 사이의 딜레마에 빠지게 된다. 논문은 이를 해결하기 위해 Context Forcing이라는 프레임워크를 제안한다. 핵심 아이디어는 교사 자체를 장기 컨텍스트를 인식하도록 사전 학습된 ‘컨텍스트 교사’를 사용하고, 이 교사가 학생에게 Contextual Distribution Matching Distillation (CDMD) 형태로 지도한다는 점이다.
CDMD는 기존 DMD(Distribution Matching Distillation)의 확장으로, 학생이 자체 생성한 컨텍스트 (X_{1:k}) 위에서 교사의 연속 분포 (p_T(X_{k+1:N}\mid X_{1:k}))와 학생의 연속 분포 (p_\theta(X_{k+1:N}\mid X_{1:k})) 사이의 KL 다이버전스를 최소화한다. 여기서 기대값은 학생의 실제 롤아웃에 대해 취해지므로, 노출 편향(exposure bias)이 크게 감소한다. 또한, 훈련 초기에 짧은 윈도우(k≈k_{min})를 사용하고, 점진적으로 최대 길이 (N(t)_{max})를 늘리는 동적 호라이즌 스케줄링을 적용해 안정적인 커리큘럼을 제공한다.
효율성 측면에서, 논문은 KV‑Cache 기반의 Slow‑Fast Memory 구조를 설계한다. 전체 캐시는 세 부분(Attention Sink, Slow Memory, Fast Memory)으로 나뉘며, Slow Memory는 고엔트로피 키프레임을 장기 저장하고, Fast Memory는 최근 프레임을 FIFO 방식으로 관리한다. 이렇게 하면 컨텍스트 길이가 선형적으로 증가하더라도 메모리 사용량과 연산량을 크게 억제할 수 있다. 특히, ‘Surprisal‑Based Consolidation’ 메커니즘을 통해 새로운 프레임이 기존 컨텍스트와 크게 차이나는 경우에만 Slow Memory에 기록함으로써 시각적 중복을 최소화한다.
실험에서는 20초 이상, 최장 2분까지의 컨텍스트를 지원하는 모델을 구축하고, DINO Score, CLIP‑F Score 등 장기 일관성 지표에서 기존 LongLive(3‑5 s)와 Infinite‑RoPE(1.5 s) 대비 2‑10배 향상을 보였다. 정성적으로도 배경·피사체 정합성이 유지되는 1분 길이 비디오를 생성하며, 다른 베이스라인은 드리프팅이나 피사체 변형이 눈에 띄게 나타난다.
요약하면, 이 논문은 (1) 장기 컨텍스트 교사를 통한 학생‑교사 불일치 해소, (2) CDMD 기반의 컨텍스트‑조건부 분포 매칭, (3) 슬로우‑패스트 메모리 설계라는 세 가지 핵심 기여를 통해 실시간 장기 비디오 생성의 핵심 병목을 효과적으로 극복한다는 점에서 큰 의의를 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기