OOD 탐지 파라미터 튜닝, OOD 데이터 없이
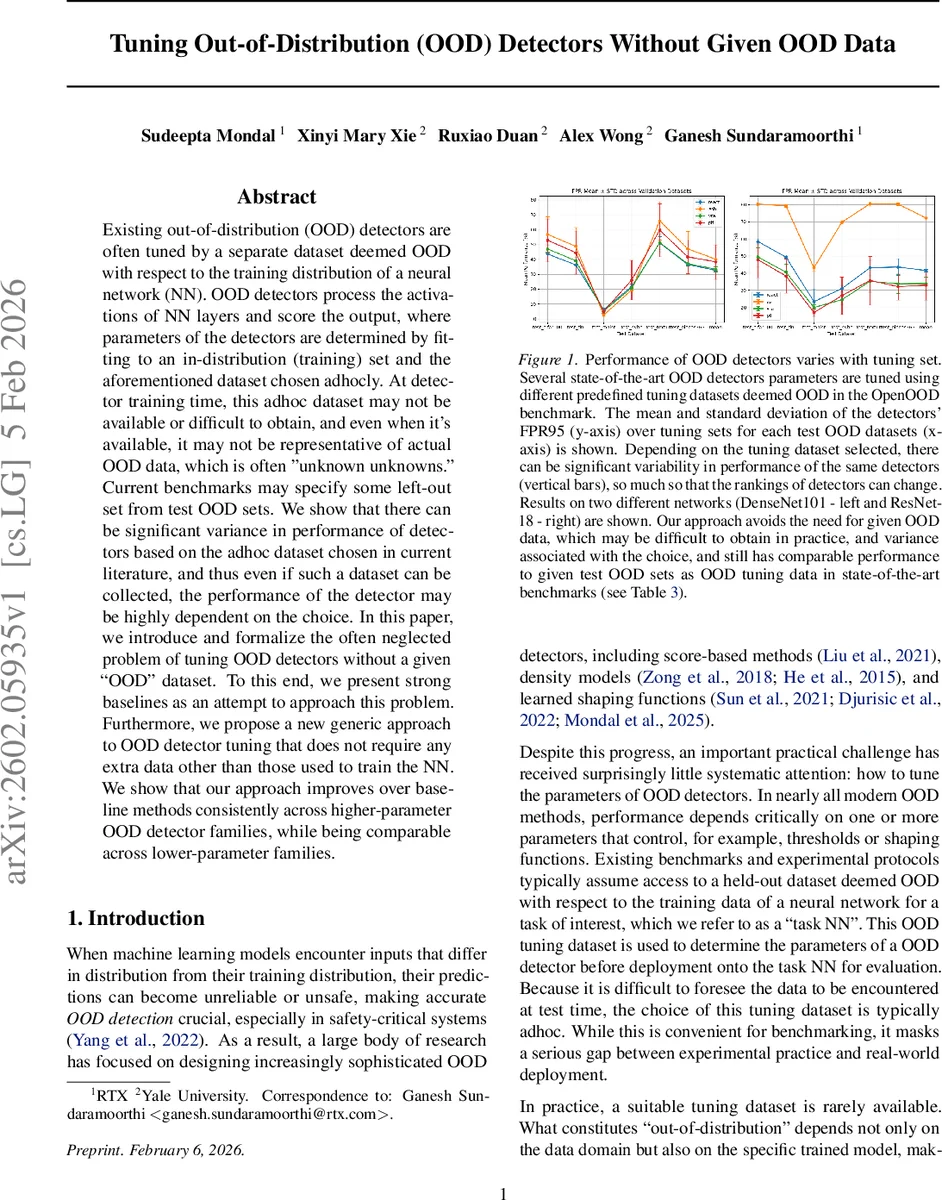
초록
본 논문은 기존 OOD 탐지기들이 별도의 OOD 튜닝 데이터를 필요로 하는 문제점을 지적하고, 전혀 추가 데이터를 사용하지 않고도 파라미터를 최적화할 수 있는 새로운 프레임워크를 제안한다. 훈련 데이터 자체에서 일부 클래스를 의도적으로 제외해 “시뮬레이션 OOD”를 만들고, 다수의 네트워크 변형을 학습시켜 평균 손실을 최소화하는 베이지안 최적화를 적용한다. 실험 결과, 제안 방법은 고파라미터 탐지기군에서 기존 Gaussian‑noise·adversarial 기반 베이스라인을 지속적으로 능가하며, 저파라미터 탐지기에서는 경쟁 수준의 성능을 유지한다.
상세 분석
이 논문은 OOD 탐지기의 파라미터 튜닝이 실제 서비스 환경에서 크게 제한된다는 사실을 체계적으로 조명한다. 기존 벤치마크는 사전에 정의된 OOD 튜닝 세트를 사용해 탐지기의 임계값이나 형태 변환 파라미터를 조정하지만, 이러한 세트는 수집 비용이 높고 실제 배포 시 마주할 “알 수 없는 OOD”와 일치하지 않을 가능성이 크다. 저자들은 먼저 Gaussian 노이즈 이미지와 적대적 교란(Adversarial perturbation)이라는 두 가지 전통적인 합성 OOD 데이터를 베이스라인으로 실험한다. 그러나 이들 방법은 데이터셋마다 성능 편차가 크고, 특히 고차원 피처를 활용하는 복잡한 탐지기(예: ReAct, ASH, VRA)에서는 일관된 개선을 보이지 않는다.
핵심 제안은 훈련 데이터 자체에서 “시뮬레이션 OOD”를 생성하는 것이다. 전체 클래스 집합에서 M개의 클래스를 무작위로 제외하고, 남은 클래스로만 네트워크를 재학습한다. 이렇게 얻어진 N개의 변형 모델은 각각 제외된 클래스를 OOD로 인식하게 되며, 이때의 입력과 출력은 실제 OOD와 유사한 특성을 가진다. 저자는 이러한 시뮬레이션 OOD와 남은 ID 데이터를 이용해 탐지기 파라미터 ϕ를 학습한다. 손실 함수 ℓ(ϕ|M)은 N개의 모델과 S개의 튜닝 샘플에 대해 평균을 취해, 특정 클래스 선택에 대한 편향을 최소화한다. 파라미터 최적화는 베이지안 옵티마이제이션을 사용해 효율적으로 수행되며, M(제외 클래스 수) 자체도 별도의 검증 절차를 통해 최적값 M*를 선정한다.
실험에서는 CIFAR‑10/100, ImageNet‑1K 등 다양한 데이터셋과 DenseNet, ResNet 등 여러 백본을 사용했다. 평가 지표는 FPR95와 AUROC이며, 제안 방법은 특히 파라미터 수가 많은 탐지기(예: VRA, ReAct)에서 베이스라인 대비 평균 3~5%p의 FPR95 감소를 기록한다. 저파라미터 탐지기(예: MSP, ODIN)에서는 성능 차이가 미미하지만, 튜닝 데이터 의존성을 완전히 없앰으로써 실용적 가치를 제공한다. 또한, 제안 방법은 기존 OpenOOD 벤치마크에서 사용된 여러 튜닝 세트에 비해 변동성을 크게 줄이며, 동일한 탐지기가 다양한 OOD 상황에서 안정적인 동작을 보인다.
이러한 접근은 OOD 탐지기의 배포 비용을 크게 낮추고, 데이터 프라이버시나 보안이 중요한 도메인에서도 안전하게 적용할 수 있는 가능성을 열어준다.
댓글 및 학술 토론
Loading comments...
의견 남기기