분포 흐름 기반 가치 모델링으로 LLM 사후 학습의 견고함과 일반화 향상
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
DFPO는 기존 양자점 기반 분포 강화학습의 한계를 넘어, 시간 흐름을 따라 연속적인 가치 흐름장을 학습한다. 조건부 위험 제어와 일관성 제약을 결합해 노이즈가 심한 피드백에서도 안정적인 가치 추정과 어드밴티지 계산을 가능하게 하며, 대화, 수학 추론, 과학 QA 등 다양한 LLM 후학습 태스크에서 PPO·FlowRL 등 기존 베이스라인을 크게 앞선 성능을 보인다.
상세 분석
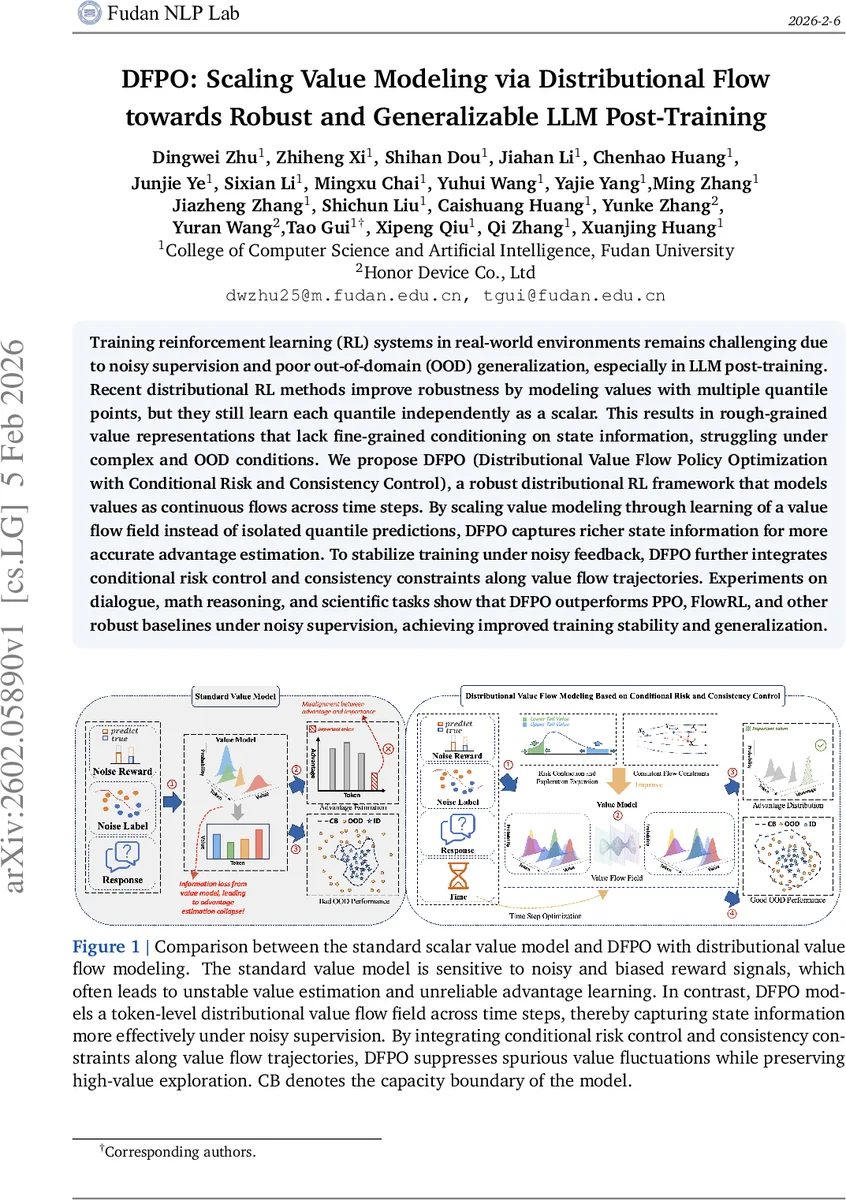
본 논문은 대규모 언어 모델(LLM) 사후 학습에서 강화학습(RL) 적용 시 마주치는 두 가지 핵심 문제, 즉 ‘노이즈가 섞인 보상 신호’와 ‘도메인 외 일반화(Out‑of‑Domain, OOD)’의 어려움을 정확히 짚어낸다. 기존의 분포 강화학습(Distributional RL) 접근법은 여러 양자점(quantile)들을 독립적인 스칼라값으로 학습함으로써 상태(state) 정보를 충분히 반영하지 못하고, 복잡하고 변동성이 큰 환경에서 거친 가치 추정으로 이어진다. DFPO는 이러한 한계를 극복하기 위해 ‘가치 흐름(value flow)’이라는 새로운 개념을 도입한다. 구체적으로, 각 상태에 대한 가치 분포를 가상의 시간 구간
댓글 및 학술 토론
Loading comments...
의견 남기기