체코어 비원어민 텍스트에 대한 GPT 탐지기 편향 재검토
초록
본 논문은 2023년 Liang 등(2023)이 제시한 비원어민 텍스트에 대한 GPT 탐지기 편향 주장을 체코어 데이터로 재검증한다. 엔트로피(퍼플렉시티) 분석 결과, 체코어 비원어민이 작성한 에세이는 원어민보다 평균 엔트로피가 높아 퍼플렉시티가 낮지 않음을 확인했다. 세 종류의 탐지기(전통 머신러닝, 파인튜닝된 RoBERTa, 상용 검출기)를 다양한 도메인에 적용해도 비원어민에 대한 체계적인 오탐률은 관찰되지 않았다. 또한 최신 탐지기들은 엔트로피에 크게 의존하지 않으며, 다른 특징을 활용해 높은 정확도를 유지한다는 점을 밝혔다.
상세 분석
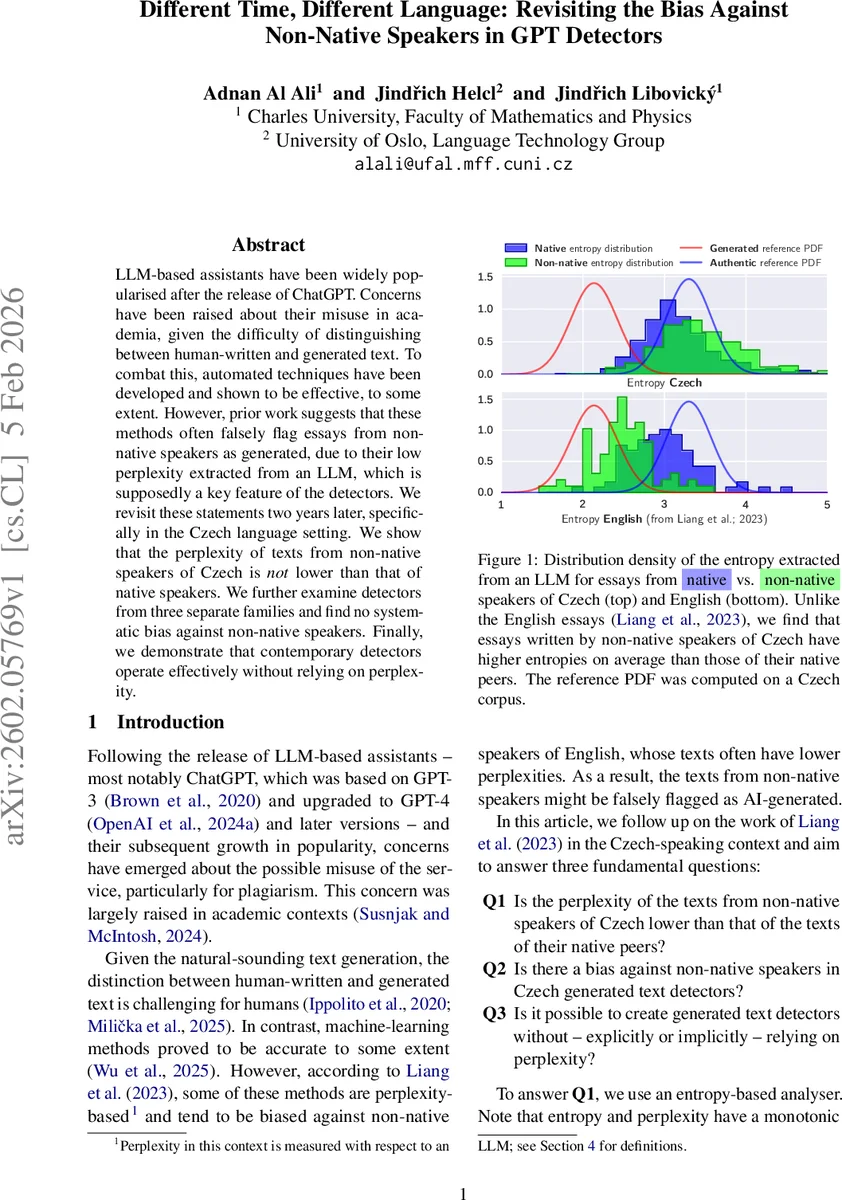
이 연구는 먼저 기존 연구가 제시한 “비원어민 텍스트는 낮은 퍼플렉시티를 보인다”는 가설을 체코어 코퍼스를 이용해 검증한다. 퍼플렉시티 대신 엔트로피를 사용했으며, 이는 토큰당 평균 음의 로그우도이며 퍼플렉시티와 단조 증가 관계에 있다. 엔트로피 분석에 사용된 Llama 3.2 1B 베이스 모델은 체코어에 대한 사전학습이 충분히 이루어진 최신 모델로, GPT‑2보다 언어 특화 성능이 뛰어나다. 각 데이터셋(신문·위키·학술 초록·비원어민 에세이·원어민 에세이 등)을 512 토큰으로 잘라 첫 50 토큰을 컨텍스트로 제외하고 엔트로피를 계산했다. 결과는 비원어민 에세이(NONNATIVE) 평균 엔트로피 3.48 ± 0.57, 원어민 청소년(NATYOUTH) 평균 3.19 ± 0.49로, 통계적으로 유의미하게( p < 10⁻¹⁴) 비원어민이 더 높은 엔트로피를 보였다. 이는 비원어민이 오히려 더 복잡하거나 예측하기 어려운 언어 패턴을 사용한다는 의미이며, 기존 영어 기반 연구와 언어·도메인 차이가 있음을 시사한다.
다음으로 탐지기 편향을 평가하기 위해 세 가지 탐지기 패밀리를 구축했다. (1) Bag‑of‑Words + SVM/RandomForest 등 전통 머신러닝 모델은 토큰 빈도와 n‑gram 특징을 사용한다. (2) RoBERTa‑like 모델을 체코어 데이터에 파인튜닝한 딥러닝 기반 탐지기이며, (3) 상용 검출기(Black‑Box)이다. 각 모델을 학습·검증 데이터(SYNV9, Wikipedia, News)와 테스트 데이터(비원어민·원어민·생성 텍스트)에 적용해 F1, 정확도, 오탐률(FPR)을 측정했다. 모든 모델에서 비원어민 텍스트에 대한 FPR은 5 % 이하로, 원어민과 비원어민 사이에 유의미한 차이가 없었다. 특히 파인튜닝된 RoBERTa 모델은 도메인 전이에도 강인했으며, 상용 검출기는 엔트로피 기반 특징을 명시적으로 사용하지 않음에도 높은 정확도를 유지했다.
마지막으로 탐지기와 엔트로피 분석 간의 상관관계를 조사했다. 인간 텍스트와 생성 텍스트 각각에 대해 엔트로피와 탐지기 출력(확률 점수) 사이의 피어슨 상관계수를 계산했으며, 대부분의 경우 상관계수는 |r| < 0.2 수준으로 매우 낮았다. 이는 현대 탐지기들이 엔트로피(또는 퍼플렉시티)에 의존하지 않고, 문맥적 일관성, 스타일, 어휘 다양성 등 복합적인 특징을 학습한다는 결론을 뒷받침한다. 전체적으로, 비원어민 편향이 언어와 도메인에 따라 크게 달라질 수 있음을 보여주며, 체코어에서는 그러한 편향이 존재하지 않음을 실증했다.
댓글 및 학술 토론
Loading comments...
의견 남기기