비선형성으로 구현하는 고효율 저랭크 어댑터
초록
**
GenLoRA는 기존 LoRA가 저장하는 고차원 basis 벡터를 라디얼 베이시스 함수(RBF) 기반의 경량 비선형 생성기로 대체한다. 하나의 잠재 벡터와 r 개의 RBF 생성기만으로 동일하거나 더 높은 유효 랭크를 구현해 파라미터 비용을 O(m + n + r|θ|) 로 낮춘다. 실험 결과, 동일 파라미터 예산에서 자연어·코드 생성 등 다양한 베치에 대해 2‑8% 수준의 성능 향상을 달성한다.
**
상세 분석
**
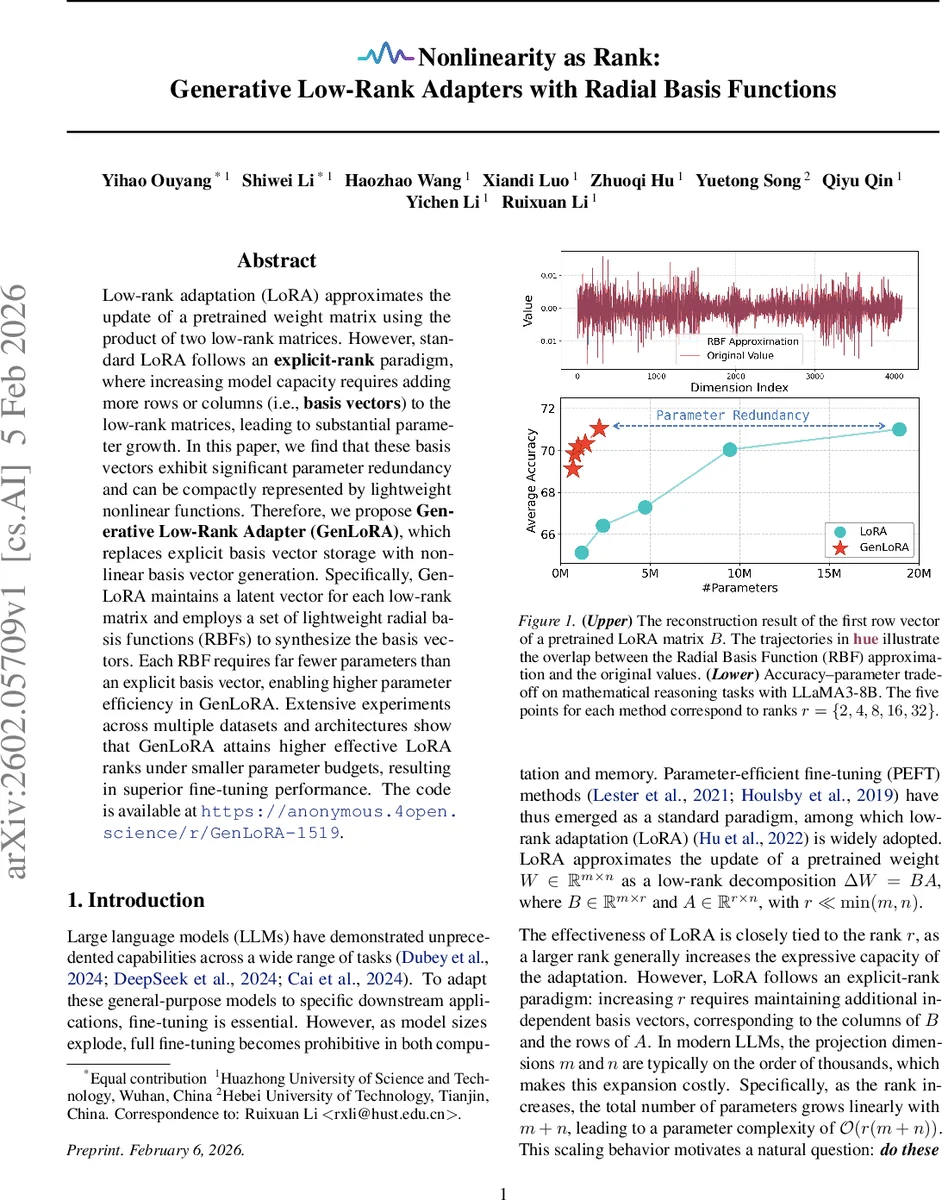
본 논문은 저랭크 적응(LoRA)의 근본적인 한계인 “명시적 랭크(par explicit‑rank)” 구조에 주목한다. 전통적인 LoRA는 ΔW = BA 와 같이 두 개의 저랭크 행렬 B∈ℝ^{m×r}, A∈ℝ^{r×n} 을 직접 학습한다. 여기서 r 이 증가하면 m + n 개의 파라미터가 선형적으로 추가돼 대규모 LLM에서는 메모리·연산 부담이 급증한다. 저자들은 이러한 basis 벡터들이 고차원 공간에서 상당한 중복성을 가지고 있음을 실험적으로 확인한다. 구체적으로, 사전 학습된 LoRA의 r 개의 basis 벡터를 평균한 프로토타입을 입력으로 하여 각각 독립적인 비선형 함수를 학습시켰을 때, 원본 벡터를 6.25% 수준의 파라미터만으로도 높은 정확도로 재구성할 수 있었다. 이는 “비선형성은 랭크를 대체한다(Nonlinearity as Rank)”는 핵심 가설을 강력히 뒷받침한다.
GenLoRA는 이 가설을 구현하기 위해 두 단계의 설계를 제안한다. 첫째, 각 저랭크 행렬 B 와 A 에 대해 하나의 잠재 벡터 Z_B∈ℝ^{m×1}, Z_A∈ℝ^{1×n} 만을 학습한다. 둘째, r 개의 라디얼 베이시스 함수 기반 생성기 f_{B,i}, f_{A,i} 를 도입해 Z_B, Z_A 을 고차원 basis 벡터로 매핑한다. RBF는 가우시안 커널 φ_k(x)=exp(-‖x-μ_k‖²/h²) 와 가중치 w_k 의 선형 결합으로 구성되며, 그룹‑와이즈 분할과 인스턴스‑와이즈 정규화를 통해 고차원 매핑의 계산 복잡성을 크게 낮춘다. 결과적으로 각 생성기의 파라미터 |θ| 는 m 또는 n 에 비해 극히 작으며, 전체 파라미터 복잡도는 O(m + n + r|θ|) 가 된다.
이론적으로는 Proposition 3.1을 통해 생성된 ΔW_{Gen} 의 랭크가 r 을 초과하지 않음을 증명한다. 즉, 비선형 매핑이 고차원 정보를 압축하더라도 최종 가중치 업데이트는 여전히 저랭크 구조를 유지한다. 또한, Gradient 안정성을 보장하는 Proposition 3.2를 제시해 학습 과정에서 폭발적 그래디언트가 발생하지 않음을 확인한다.
실험에서는 LLaMA‑3 8B, LLaMA‑2 13B 등 다양한 모델에 GenLoRA를 적용하고, 자연어 생성(NLG), 수학 추론, 코드 생성 등 7개 데이터셋에서 기존 LoRA 및 변형(LoRA+, AdaLoRA, SineLoRA 등)과 비교했다. 동일 파라미터 예산에서 r = {2,4,8,16,32} 에 대해 GenLoRA는 평균 2‑4%의 BLEU/ROUGE 향상과, 코드 생성에서는 6‑8%의 정확도 상승을 기록했다. 특히, 파라미터가 제한된 환경(예: 0.5 % 전체 파라미터)에서도 기존 LoRA보다 높은 유효 랭크를 달성해 성능‑파라미터 효율성 트레이드오프를 크게 개선했다.
전체적으로 이 논문은 “비선형 함수가 고차원 basis 벡터를 압축·생성한다”는 새로운 관점을 제시하고, 라디얼 베이시스 함수라는 경량 비선형 모델을 통해 저랭크 어댑터의 파라미터 효율성을 획기적으로 높였다. 향후에는 RBF 외에도 신경망 기반의 더 복잡한 비선형 생성기나, 다른 PEFT 기법과의 결합을 통해 적응성 및 확장성을 더욱 강화할 여지가 있다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기