통계 흐름 매칭과 분류기 상속을 통한 효율적 데이터셋 증류
초록
본 논문은 사전학습된 자기지도 비전 모델을 백본으로 사용해, 기존 데이터셋을 압축한 합성 이미지 집합을 생성하는 새로운 방법을 제안한다. 기존의 선형 그래디언트 매칭(LGM)은 대규모 실데이터와 다중 증강을 매 단계마다 로드해야 하는 비효율성을 갖는데, 저자는 이를 “통계 흐름 매칭”(Statistical Flow Matching, SFM)으로 대체한다. SFM은 각 클래스의 평균 특징을 한 번만 계산하고, 합성 이미지가 목표 클래스 중심에서 비목표 클래스 중심으로 흐르는 통계적 흐름을 따르게 한다. 또한, 원본 데이터로 학습된 분류기를 그대로 재사용하는 “분류기 상속”(Classifier Inheritance, CI) 전략을 도입해, 경량 선형 프로젝터만 추가 학습하면 높은 정확도를 달성한다. 실험 결과, GPU 메모리 사용량을 10배, 학습 시간을 4배 절감하면서도 최신 방법과 동등하거나 더 높은 성능을 보여준다.
상세 분석
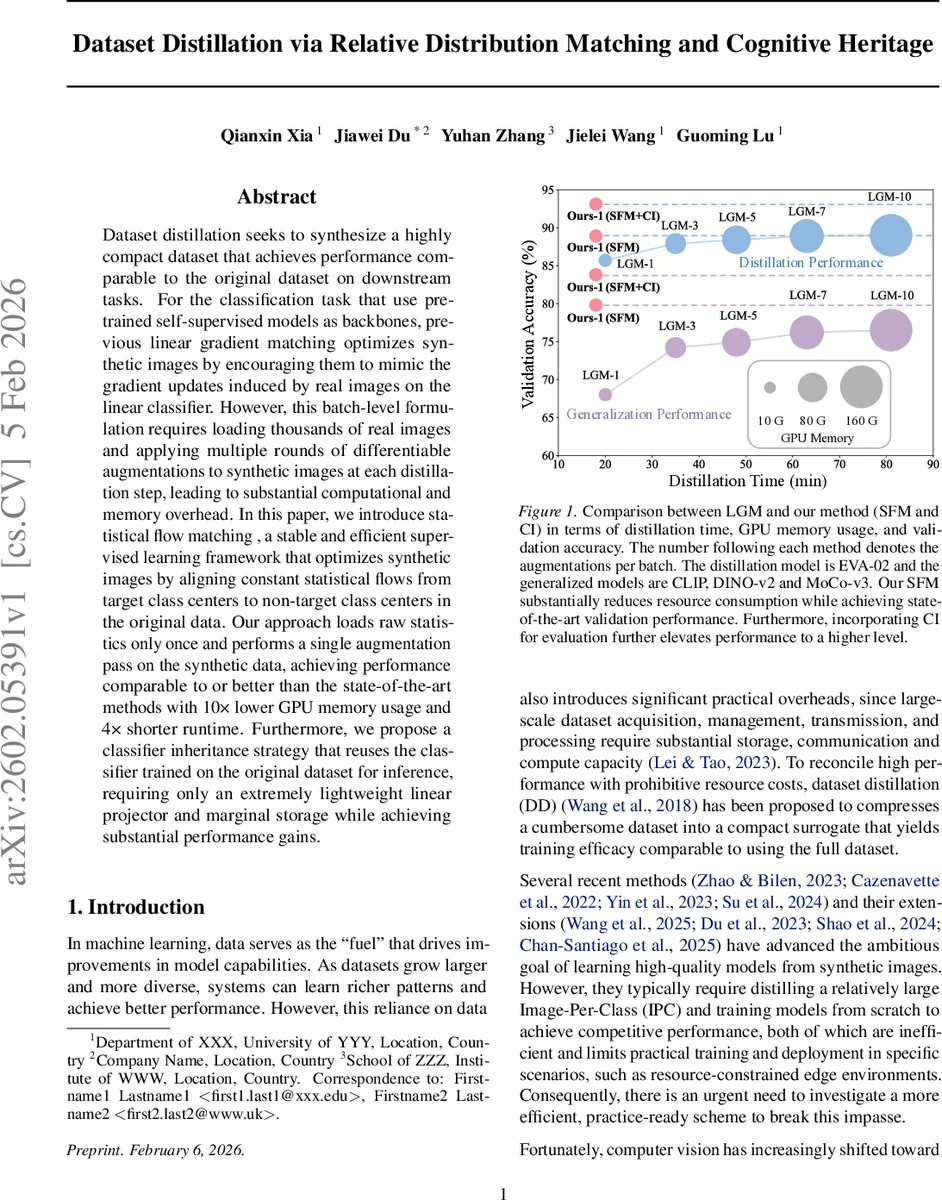
이 논문은 데이터셋 증류 분야에서 두 가지 핵심 혁신을 제시한다. 첫 번째는 기존 LGM이 “그라디언트 매칭”이라는 로컬 최적화 문제에 머무르는 한계를 극복하고, 전역적인 통계 정보를 활용한다는 점이다. 저자는 선형 분류기의 가중치 W가 무작위 초기화될 때 소프트맥스 확률 p_i가 거의 균등(1/C)하게 되며, 이는 실제 그래디언트가 클래스 중심 간 차이, 즉 “흐름(flow)”에 의해 주도된다는 수학적 분석을 제공한다. 이 흐름은 목표 클래스의 평균 특징 ϕ*(x|y=1)과 비목표 클래스 평균 ϕ*(x|y=0) 사이의 차이 벡터로 정의된다. 기존 LGM은 매 배치마다 실데이터를 로드하고, 합성 이미지에 여러 차례 미분 가능한 증강을 적용해 복잡한 그래디언트 그래프를 유지해야 했지만, SFM은 이러한 흐름을 사전에 한 번만 계산해 고정된 통계 흐름 F를 만든다. 이후 합성 이미지가 동일한 흐름을 재현하도록 코사인 유사도 손실 L_sfm = 1 - cos(F_d, F_s_d) 를 최소화한다. 이 접근법은 (1) 메모리 요구량을 크게 낮추고, (2) 증류 과정에서 증강을 반복할 필요가 없어 연산 효율성을 크게 향상시키며, (3) 배치 규모와 증강 횟수에 민감한 LGM의 불안정성을 해소한다는 장점을 가진다.
두 번째 혁신은 “분류기 상속”(CI)이다. 합성 데이터가 극도로 압축된 상황에서는 새롭게 학습된 선형 분류기가 원본 데이터가 제공하던 복잡한 결정 경계를 충분히 학습하기 어렵다. 저자는 원본 데이터로 학습된 “골든 분류기”를 그대로 재사용하고, 합성 이미지에 대해 가벼운 선형 프로젝터(단일 레이어)만 추가 학습하도록 설계한다. 이렇게 하면 기존에 학습된 풍부한 클래스별 특징을 그대로 활용하면서도, 합성 데이터에 맞춘 미세 조정만으로 높은 정확도를 얻을 수 있다. 실험에서는 ImageNet‑100에서 클래스당 1장의 합성 이미지만 사용했음에도 불구하고, CLIP, DINO‑v2, MoCo‑v3 등 다양한 백본에 대해 80%~95%의 검증 정확도를 달성했다. 또한, GPU 메모리 사용량을 16 GB에서 165 GB 수준으로 10배 감소시키고, 전체 증류 시간을 18 분에서 80 분 수준으로 4배 단축했다.
이러한 설계는 특히 엣지 디바이스나 메모리·연산 제한이 있는 환경에서 데이터셋을 압축하고 빠르게 모델을 배포하려는 실용적 요구에 부합한다. 또한, 통계 흐름이라는 전역적 목표를 도입함으로써 증류 과정이 보다 안정적이고 재현 가능하게 된다. 다만, 통계 흐름을 한 번만 계산한다는 가정이 데이터 분포가 크게 변하거나 복잡한 클래스 간 관계를 충분히 포착하지 못할 경우 성능 저하 위험이 존재한다는 점은 향후 연구에서 보완이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기