고해상도 비전용 경량 하이브리드 네트워크 ReGLA
초록
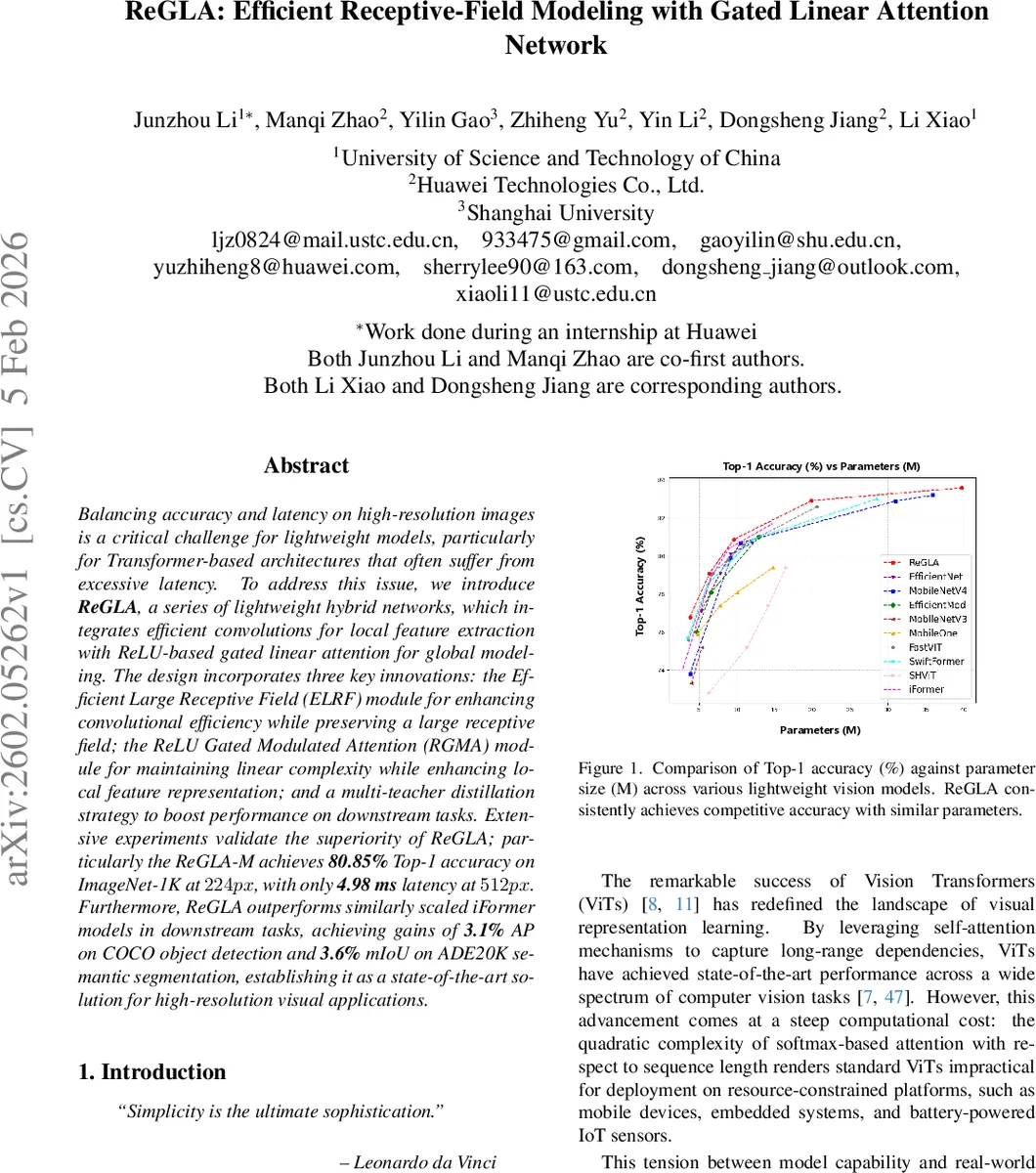
ReGLA는 효율적인 깊이별 컨볼루션(ELRF)과 ReLU 기반 게이트 선형 어텐션(RGMA)을 결합한 경량 CNN‑Transformer 하이브리드 구조이다. 4단계 계층 설계와 다중 교사 지식 증류를 통해 ImageNet‑1K에서 80.85% Top‑1 정확도(224 px)와 512 px에서 4.98 ms의 저지연을 달성했으며, COCO 객체 탐지와 ADE20K 세그멘테이션에서도 기존 iFormer 대비 각각 3.1% AP, 3.6% mIoU 향상을 보였다.
상세 분석
ReGLA는 고해상도 이미지 처리 시 발생하는 계산량 폭증 문제를 두 가지 핵심 모듈로 해결한다. 첫 번째인 Efficient Large Receptive Field(ELRF) 모듈은 기존 7×7 깊이별 컨볼루션을 3×3와 5×5 깊이별 컨볼루션을 FFN과 교차 배치함으로써 동일한 수용 영역을 유지하면서 연산량과 메모리 접근을 크게 감소시킨다. 이 설계는 초기 단계에서 넓은 공간적 컨텍스트를 확보하고, 이후 단계에서의 Transformer‑like 전역 모델링 비용을 최소화한다. 두 번째인 ReLU Gated Modulated Attention(RGMA) 모듈은 소프트맥스 기반 어텐션을 ReLU 기반 선형 어텐션으로 대체하고, 별도의 컨볼루션 게이트(시그모이드 활성화)를 통해 지역 정보를 강조한다. 수식적으로 RGMA는 Xₒ = G(x) ⊙ C(x) 형태이며, G(x)는 공간적 가중치를 생성하는 경량 게이트, C(x)는 ReLU(Q)·ReLU(K)ᵀ·V 형태의 선형 어텐션이다. 이 구조는 토큰 간 상호작용을 O(N·d)로 낮추면서도, 게이트가 지역 패턴을 보강해 순수 선형 어텐션이 갖는 로컬 표현력 부족을 보완한다.
네트워크 전체는 Stem → Stage1~4 로 구성되며, Stage1·2에 ELRF, Stage3·4에 RGMA를 배치한다. 모델 파라미터와 블록 수를 스케일링해 T, S, M, L, X 다섯 가지 변형을 제공한다. 예를 들어 ReGLA‑M은 9.6 M 파라미터, 1.24 GFLOPs, 4.98 ms(512 px) 지연을 기록한다.
다중 교사(distillation) 전략은 DINOv2, SAM2, DeiT‑III 등 7개의 사전 학습 모델을 활용한다. 각 교사는 서로 다른 비전 태스크에 특화된 지식을 제공하고, 학생 모델은 단계별 피처를 1/16 스케일로 정규화해 정합성을 확보한다. 증류 과정에서 사용된 Ladder Encoder와 가변 프로젝터는 추론 시 제거돼 오버헤드가 없다.
실험 결과는 세 가지 측면에서 강점이 드러난다. 1) ImageNet‑1K에서 동일 파라미터 범위의 iFormer 대비 Top‑1 정확도가 0.45~0.8% 상승한다. 2) COCO 객체 탐지에서 3.1% AP, ADE20K 세그멘테이션에서 3.6% mIoU 향상을 보이며, 특히 고해상도(512 px) 입력 시 4.98 ms라는 모바일 CPU 수준의 지연을 달성한다. 3) FLOPs 대비 정확도 효율이 높아, 모바일 환경(iPhone16 Pro, iOS 18.5)에서 실시간 추론이 가능하다.
한계점으로는 ReLU 기반 선형 어텐션이 소프트맥스의 정규화 효과를 완전히 대체하지 못해 특정 복잡한 장면에서 표현력이 떨어질 가능성이 있다. 또한 다중 교사 증류 과정이 학습 비용을 크게 증가시키며, 교사 선택 및 가중치 조정이 경험적이다. 향후 연구에서는 동적 게이트 설계, 하드웨어 친화적 커스텀 연산자 구현, 그리고 교사 자동 선택 메커니즘을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기