RFM‑Pose: 강화학습으로 가속화한 흐름 매칭 기반 카테고리 레벨 6D 포즈 추정
초록
RFM‑Pose는 흐름 매칭(Flow Matching)으로 빠르게 6D 포즈 후보를 생성하고, 이를 마코프 결정 과정(MDP)으로 재구성해 PPO 기반 강화학습으로 정책을 미세조정한다. 회전·이동을 별도 평가하는 다중 비평가(value) 네트워크가 후보를 점수화·선별하며, REAL275와 Omni6DPose에서 기존 확산 기반 방법보다 샘플링 단계는 10배 이하로 줄이면서 실시간(30 FPS 이상) 수준의 정확도를 달성한다. 또한 동일 구조를 이용해 연속적인 포즈 트래킹에도 적용 가능하다.
상세 분석
본 논문은 카테고리 레벨 6D 포즈 추정에서 최근 각광받는 확산 기반 점성 모델이 안고 있던 “고비용 샘플링” 문제를 근본적으로 해결하고자 흐름 매칭(Flow Matching, FM)과 강화학습을 융합한 새로운 프레임워크 RFM‑Pose를 제안한다. FM은 확산 모델과 달리 확률적 미분 방정식이 아니라 결정론적 ODE 형태로 목표 분포를 단순 가우시안 prior와 연결한다. 이 특성 덕분에 적은 수의 Euler 단계만으로도 고품질 샘플을 생성할 수 있어 실시간 응용에 적합하지만, FM 자체는 “샘플 품질을 평가하는 내재적 스코어링 메커니즘”이 없고, 특히 대칭 객체에 대해 회전 분포가 과도하게 퍼지는 경향이 있다.
논문은 이러한 두 가지 한계를 다음과 같이 보완한다. 첫째, FM 샘플링 과정을 마코프 결정 과정(MDP)으로 재정의한다. 상태 s_h는 현재 관측점군 O, 지금까지 생성된 흐름 벡터들의 히스토리 u_h, 그리고 현재 단계 비율 h/H 로 구성된다. 사전 학습된 흐름 네트워크 Γ_θ는 초기 정책 π_θ′ 로 사용되며, 각 흐름 벡터 u는 정책이 선택하는 액션에 해당한다. 둘째, 정책을 강화학습으로 미세조정한다. PPO(Proximal Policy Optimization)를 적용해 액션(흐름) 선택을 회전·이동 오류 기반 보상 r_h를 최대화하도록 학습한다. 보상은 회전 오류 ΔR와 이동 오류 ΔT를 각각 지수적으로 감소시키는 형태이며, 두 모달리티의 스케일 차이를 고려해 별도의 비평가(V_rot, V_trans)로 구성된 다중-크리틱 가치 네트워크 V_ϕ를 도입한다. 이렇게 하면 정책이 “정확한 포즈 쪽으로 흐름을 끌어당기”는 방향성을 학습하게 되고, 결과적으로 SO(3) 상의 분포가 크게 수축한다.
학습된 정책은 테스트 시 K개의 후보 포즈를 빠르게 생성하고, 가치 네트워크가 각 후보에 대한 점수를 부여한다. 높은 점수를 받은 후보들을 QUEST 알고리즘으로 회전을, 가중 평균으로 이동을 집계해 최종 포즈를 산출한다. 이 과정에서 별도의 likelihood 계산이 필요 없으며, 후보 선택이 가치 네트워크에 의해 직접 지도된다.
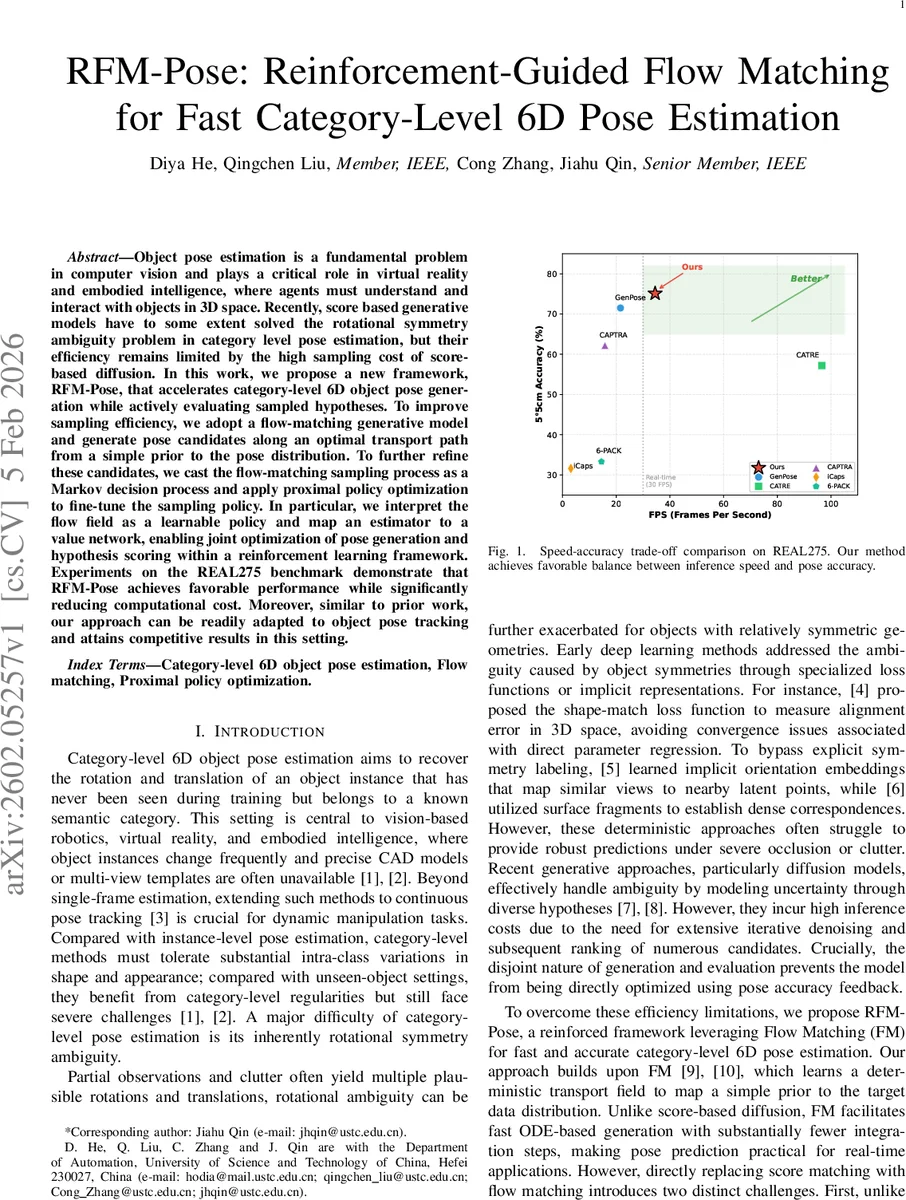
실험에서는 REAL275와 Omni6DPose 두 벤치마크에서 기존 확산 기반 방법(GenPose, 6D‑Diff 등) 대비 샘플링 단계가 10배 이하로 감소했음에도 불구하고, 5°/5 cm 기준 정확도에서 동등하거나 약간 상회하는 성능을 보였다. 특히 30 FPS 이상의 실시간 처리 속도를 유지하면서도 대칭 객체에 대한 회전 오류가 크게 감소했다. 또한 동일 모델을 연속 프레임에 적용해 포즈 트래킹을 수행했을 때, 기존 트래킹 전용 방법과 경쟁 가능한 결과를 얻었다.
핵심 기여는 (1) 흐름 매칭을 이용해 고속 샘플링 기반 포즈 생성기를 구축, (2) 이를 MDP와 PPO로 정형화해 보상 기반 정책 미세조정을 수행, (3) 회전·이동을 별도 평가하는 다중-크리틱 가치 네트워크로 후보를 효율적으로 선별·집계함으로써 “생성 + 평가”를 하나의 학습 가능한 파이프라인으로 통합한 점이다. 이러한 설계는 향후 다른 3D 변환 문제(예: 물체 재구성, 로봇 궤적 계획)에도 확장 가능성을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기