GPU를 벗어난 대규모 언어 모델 학습, 메모리 중심 HorizonLM
초록
HorizonLM은 GPU를 단순 연산 엔진으로 전락시키고, 호스트 메모리를 파라미터 저장소로 활용하는 RAM‑중심 학습 시스템이다. CPU가 파라미터와 옵티마이저 상태를 관리하고, GPU는 레이어 템플릿만을 일시적으로 로드해 연산 후 즉시 해제한다. 명시적 재계산과 수동 그래디언트 전파, 이중 버퍼 파이프라인을 통해 GPU 메모리 사용을 레이어당 최대 크기로 제한하면서도 120B 파라미터 모델을 단일 H200 GPU에서 학습한다. A100 기반 단일 노드에서도 DeepSpeed ZeRO‑3 대비 12배 이상의 처리량을 달성한다.
상세 분석
본 논문은 현재 대형 언어 모델(LLM) 훈련이 GPU 메모리 용량에 의해 병목이 되는 상황을 지적하고, 기존의 GPU‑중심 설계가 근본적인 한계를 갖는 이유를 세 가지로 정리한다. 첫째, 파라미터와 전체 autograd 그래프가 GPU에 상주해야 하므로 모델 규모가 커질수록 다수의 GPU와 복잡한 분산 런타임이 필수적이다. 둘째, CPU 메모리는 파라미터 저장소가 아니라 런타임 힙으로 전락해, 모델 크기와 무관하게 메모리 사용량이 예측 불가능해진다. 셋째, 메모리 관리와 연산이 얽혀 있어 호스트 메모리를 충분히 확보하더라도 대규모 모델을 단일 GPU에서 실행하기 어렵다.
HorizonLM은 이러한 구조적 제약을 해소하기 위해 “CPU‑master, GPU‑template” 실행 모델을 제안한다. 모든 파라미터와 옵티마이저 상태는 호스트 RAM에 BF16(파라미터·그래디언트)와 FP32(Adam 모멘트) 형태로 저장되며, GPU는 레이어 템플릿만을 재사용한다. 학습 시 각 레이어의 파라미터를 필요 시점에 스트리밍으로 GPU에 로드하고, 연산이 끝나면 즉시 해제한다. 이 과정에서 전체 autograd 그래프를 구축하지 않고, 레이어 단위 재계산과 수동 그래디언트 전파를 수행함으로써 메모리 사용을 레이어당 파라미터 크기(P_max)와 체크포인트 크기로 엄격히 제한한다.
또한, 이중 버퍼링 파이프라인을 도입해 파라미터 프리패치, 연산, 그래디언트 오프로드를 서로 겹치게 스케줄링한다. 이를 통해 PCIe 5.0 혹은 NVLink‑C2C와 같은 CPU‑GPU 인터커넥트 대역폭이 충분히 활용되며, 전송량 V_H2D≈P, V_D2H≈P(전체 파라미터 크기)임에도 연산 시간 T_comp에 맞춰 전송이 숨겨진다. 결과적으로 GPU 메모리 사용량은 c_p·P_max + c_a·K·A_max + W_GPU 형태의 상수에 머물고, 호스트 메모리 사용량은 12·P 바이트(파라미터·그래디언트·옵티마이저)와 고정된 슬랩 풀만을 추가한 선형 규모가 된다.
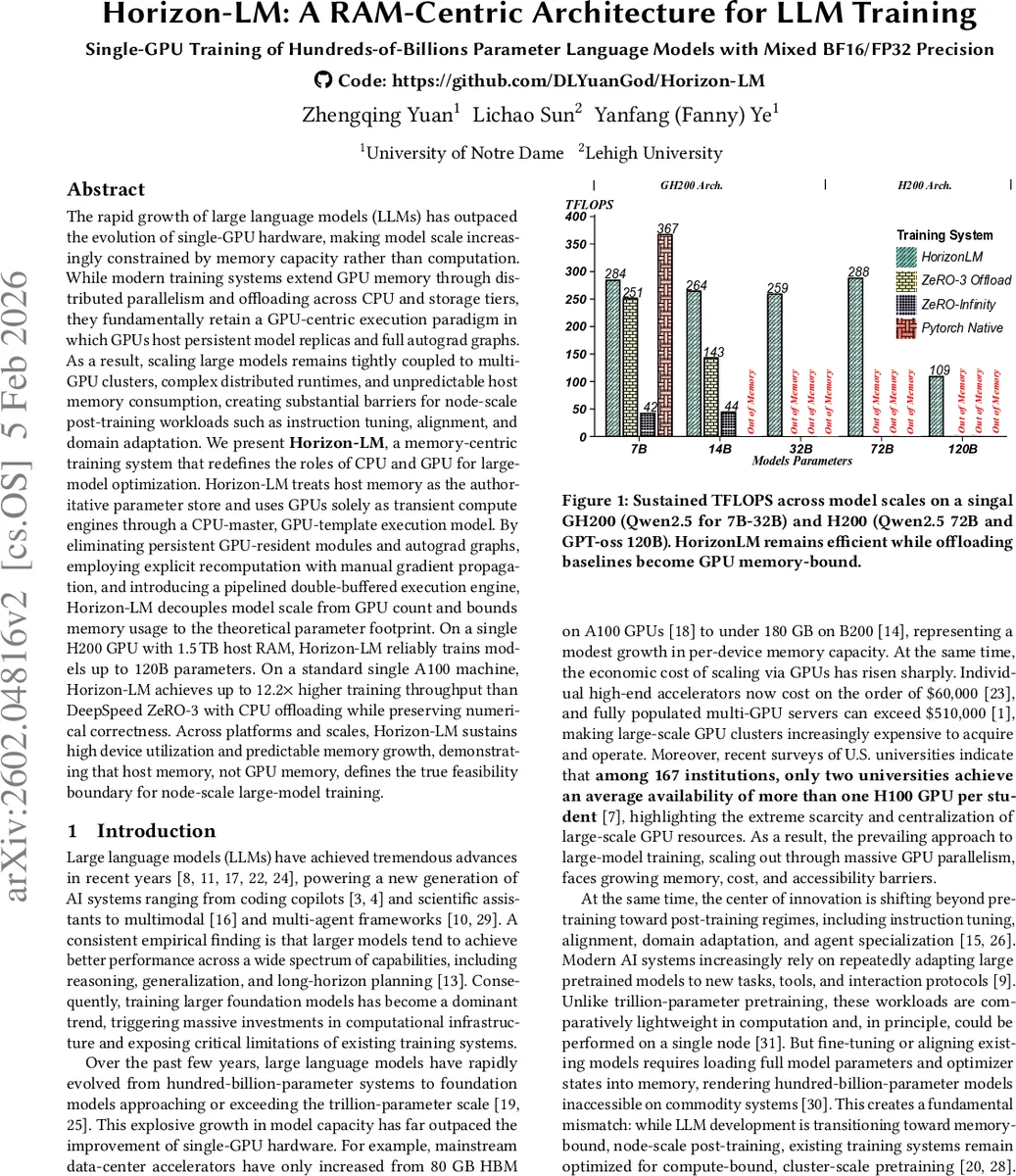
실험에서는 H200 GPU(1.5 TB RAM)에서 120 B 파라미터 모델을 안정적으로 학습했으며, A100 단일 노드에서는 DeepSpeed ZeRO‑3 대비 최대 12.2배 높은 처리량을 기록했다. 모델 규모가 커질수록 GPU 활용률과 메모리 예측 가능성이 유지되는 점이 강조된다. 논문은 메모리 중심 설계가 향후 노드‑스케일 LLM 포스트‑트레이닝(인스트럭션 튜닝, 정렬 등)에 필수적이며, GPU 비용과 클러스터 복잡성을 크게 낮출 수 있음을 주장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기