바이브 AIGC: 에이전트 오케스트레이션으로 여는 창작 혁신
초록
본 논문은 기존의 모델‑중심 생성 방식이 겪는 ‘Intent‑Execution Gap’(의도‑실행 격차)를 해소하기 위해, 사용자가 고수준의 “바이브”(Vibe)를 제시하고 메타‑플래너가 이를 계층적 다중‑에이전트 워크플로우로 자동 분해·실행하는 ‘바이브 AIGC’ 패러다임을 제안한다. 이를 통해 창작자는 프롬프트 엔지니어가 아닌 ‘커맨더’ 역할을 수행하며, AI는 논리적 오케스트레이션을 통해 장기·복합 디지털 자산을 안정적으로 생산한다.
상세 분석
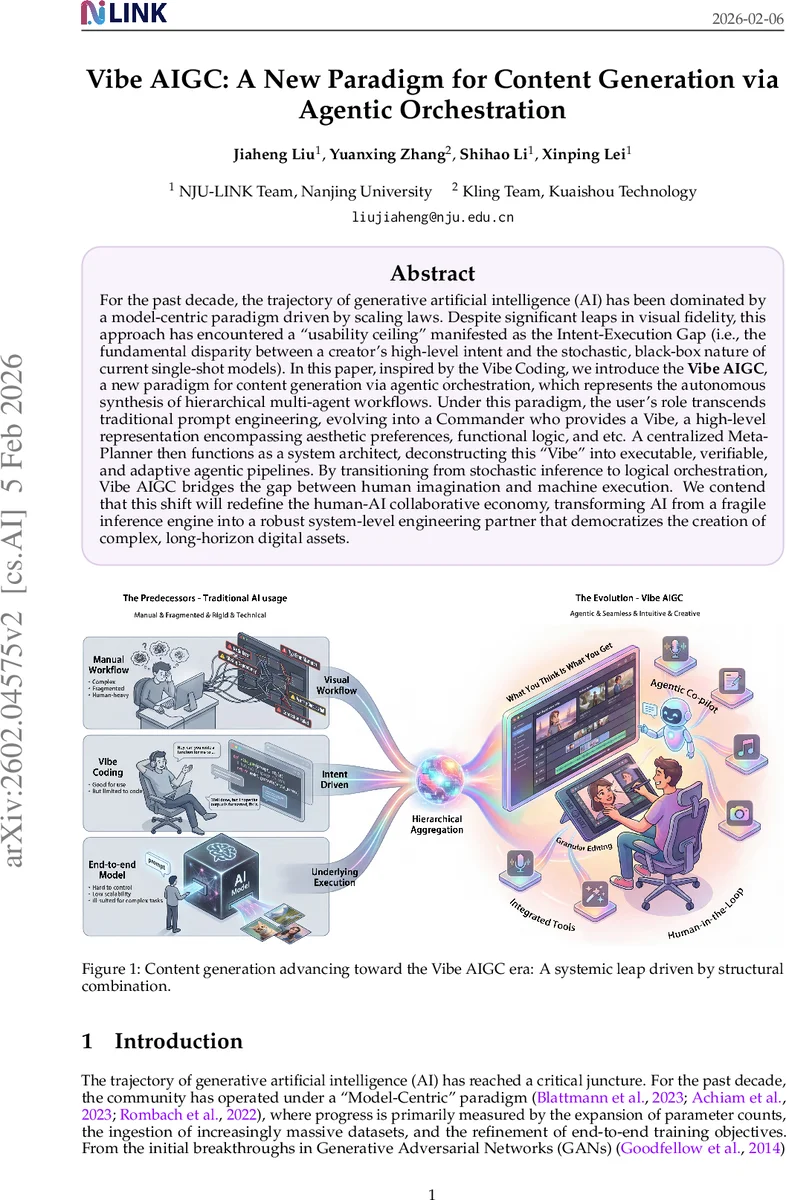
논문은 먼저 지난 10년간 생성 AI가 파라미터 규모와 데이터 양에 의존한 모델‑중심 패러다임을 고수해 왔으며, 이는 시각적 품질 향상에는 성공했지만 인간의 다차원적 창작 의도를 직접 반영하기엔 ‘Intent‑Execution Gap’이라는 근본적인 한계에 봉착했다고 지적한다. 기존의 텍스트‑투‑이미지·텍스트‑투‑비디오 모델은 단일 샷 추론에 의존해 확률적 결과를 도출하므로, 사용자는 원하는 결과를 얻기 위해 수많은 프롬프트 실험과 재시도를 반복해야 한다. 이러한 반복은 비용·시간을 낭비할 뿐 아니라, 장기 일관성(예: 캐릭터 아이덴티티 유지)이나 복합 논리(스토리 전개, 음악·영상 동기화)와 같은 고차원 작업에서는 실효성을 잃는다.
‘바이브 코딩(Vibe Coding)’ 개념을 차용해, 저자는 ‘바이브’를 “미학·기능·제약을 포함한 고수준 의도 표현”으로 정의하고, 사용자를 ‘커맨더’로 재위치한다. 커맨더는 구체적인 구현 방법이 아닌 목표와 분위기만을 제시하고, 중앙 메타‑플래너가 이를 해석해 계층적 에이전트 파이프라인으로 변환한다. 각 에이전트는 특화된 모델(예: 스크립트 작성, 음악 템포 분석, 캐릭터 시트 생성, 영상 편집)으로 구성되며, 메타‑플래너는 작업 흐름을 검증·피드백 루프를 통해 동적으로 조정한다. 이 구조는 (1) 논리적 오케스트레이션을 통해 확률적 추론을 보완하고, (2) 재사용 가능한 모듈을 통해 복합 작업을 효율적으로 분해·조합하며, (3) 피드백 기반 적응을 통해 사용자의 고수준 피드백(예: “더 어두운 분위기로”)을 하위 작업에 반영한다는 장점을 제공한다.
기술적 비판에서는 현재 비디오 생성 모델이 ‘스페이스‑타임 디퓨전’과 같은 패치 기반 접근을 사용해 고해상도와 긴 시퀀스를 처리하려 하지만, 데이터 규모·다양성 부족과 연산 비용 문제로 여전히 제한적이다. 또한, 레퍼런스 기반 생성·편집은 훈련 데이터 부족으로 ‘콘텐츠 누수’와 같은 아티팩트를 초래한다. 논문은 이러한 한계를 에이전트 오케스트레이션이 해결할 수 있다고 주장한다.
마지막으로, 저자는 에이전트 오케스트레이션 레이어의 연구가 앞으로의 핵심 과제가 될 것이며, 이를 위해 ‘바이브 AIGC’ 생태계 구축, 표준 메타‑플래너 설계, 에이전트 간 인터페이스 정의, 그리고 인간‑AI 상호작용 프로토콜 개발이 필요하다고 강조한다. 전체적으로, 모델‑중심에서 시스템‑중심으로의 전환은 생성 AI의 상용화와 전문 창작 워크플로우의 효율성을 크게 향상시킬 잠재력을 지닌다.
댓글 및 학술 토론
Loading comments...
의견 남기기