멀티모달 프로세스 보상 모델의 데이터 효율성 향상을 위한 균형 정보 점수(BIS)
초록
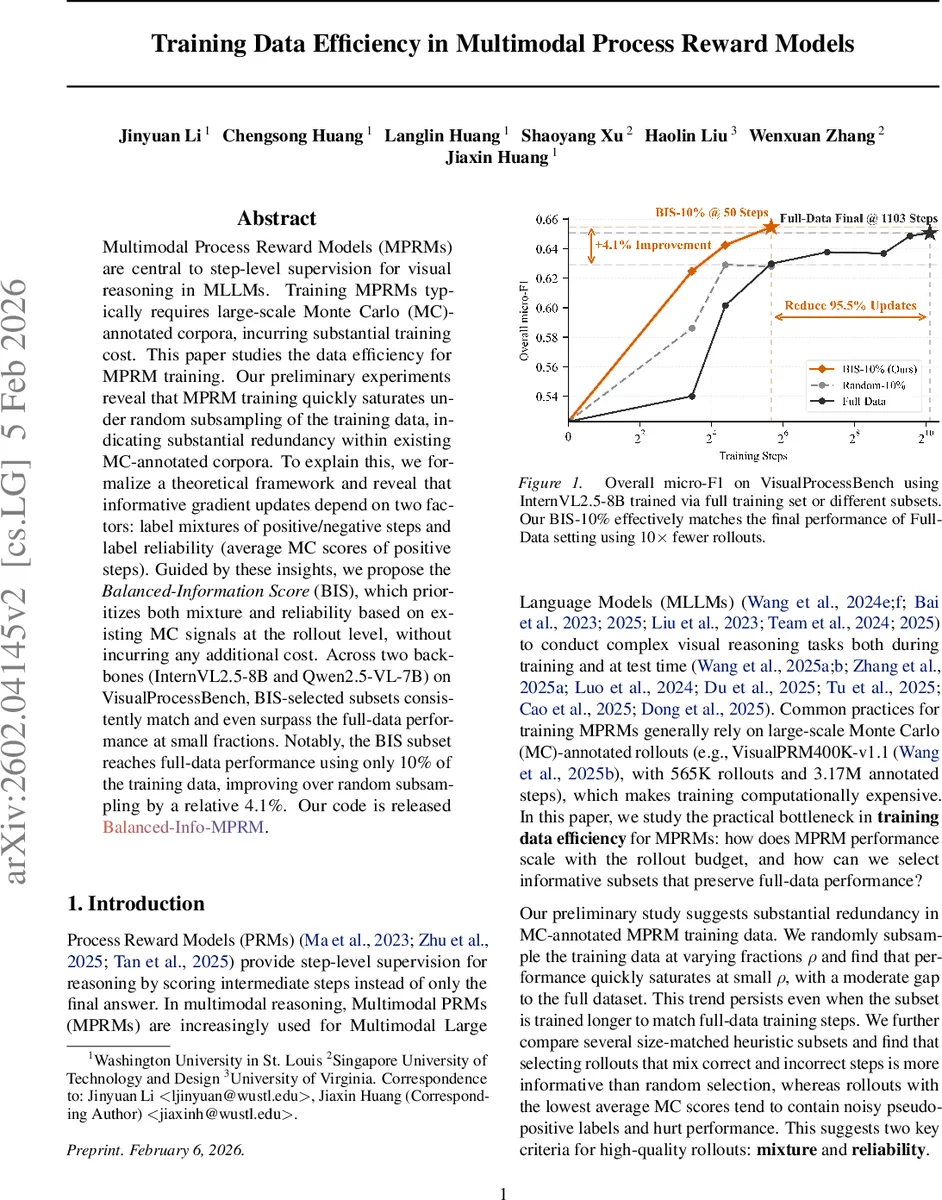
본 논문은 멀티모달 프로세스 보상 모델(MPRM) 학습에 필요한 대규모 Monte‑Carlo 라벨이 실제로는 높은 중복성을 가지고 있음을 실험적으로 확인한다. 이론적 분석을 통해 라벨 혼합도와 신뢰도(양성 단계의 평균 MC 점수)가 그래디언트 정보를 결정한다는 사실을 밝혀내고, 두 요소를 동시에 고려하는 Balanced‑Information Score(BIS)를 제안한다. BIS로 선택된 10% 서브셋은 전체 데이터와 동등하거나 더 나은 성능을 달성하며, 무작위 서브샘플링 대비 4.1% 상대 향상을 보인다.
상세 분석
본 연구는 먼저 VisualPRM400K‑v1.1과 같은 대규모 MC‑annotated 롤아웃 데이터셋을 무작위로 25%, 10% 등으로 축소했을 때, 모델 성능이 급격히 포화되는 현상을 관찰한다. 이는 라벨이 노이즈를 포함하고 있어 데이터 양을 늘려도 최적화 단계에서 발생하는 그래디언트 노이즈가 지배적인 한계가 됨을 시사한다. 이를 정량화하기 위해 저자들은 teacher‑student 프레임워크를 도입한다. 교사는 실제 단계 정답 확률 q∗(ϕ)=σ(⟨w∗,ϕ⟩)를, 학생은 noisy MC 라벨 Y_mc를 사용해 로지스틱 손실을 최소한다. SGD 수렴 분석에 따르면 기대 손실 차이는 데이터 복잡도 항 C_data·N_eff^‑½와 최적화 항 C_opt·T^‑½의 합으로 표현된다. 대규모 데이터셋에서는 C_data·N_eff^‑½가 이미 작아 최적화 항이 전체 오차를 좌우한다. 따라서 무작위 서브샘플링은 데이터 복잡도 항만 γ^‑½ 배만큼 증가시키므로 성능 차이가 미미하다.
다음 단계에서는 “혼합하지만 신뢰성 있는” 롤아웃이 왜 더 유익한지를 이론적으로 설명한다. 교사의 불확실성 q∗(ϕ)(1‑q∗(ϕ))는 단계별 그래디언트 제곱의 기대값에 비례하므로, q∗≈0.5인 즉, 양성·음성 라벨이 고르게 섞인 단계가 가장 큰 학습 신호를 제공한다. 반면 MC 점수가 매우 낮은 단계는 양성 라벨이 실제로는 거의 불가능한 경우에도 이진 라벨링 규칙에 의해 양성으로 표기돼 라벨 노이즈를 크게 증가시킨다. 따라서 라벨 혼합도(양성·음성 비율)와 라벨 신뢰도(양성 단계 평균 MC 점수)를 동시에 고려하는 것이 그래디언트 품질을 최적화한다는 결론에 도달한다.
이 두 인사이트를 바탕으로 Balanced‑Information Score(BIS)를 정의한다. BIS는 롤아웃 수준에서 (1) 각 단계의 양성·음성 비율을 측정해 혼합도를 평가하고, (2) 양성 단계들의 평균 MC 점수를 이용해 신뢰도를 측정한다. 두 값은 곱셈적으로 결합되어 “혼합·신뢰” 점수를 산출한다. BIS는 기존 MC 라벨만을 사용하므로 추가 연산 비용이 전혀 들지 않는다. 실험에서는 InternVL2.5‑8B와 Qwen2.5‑VL‑7B 두 백본 모델에 BIS‑선택 서브셋을 적용했으며, 10% 서브셋이 전체 데이터와 동등한 micro‑F1을 달성하고, 무작위 10% 대비 4.1%의 상대적 개선을 보였다. 특히 BIS‑10% 서브셋을 50 스텝만 학습해도 Full‑Data 수준에 도달해 연산 비용을 95.5% 절감했다. 이러한 결과는 데이터 선택이 모델 성능에 미치는 영향을 정량화하고, 실제 연구·산업 현장에서 대규모 MC 라벨링 비용을 크게 낮출 수 있는 실용적인 방안을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기