듀얼 오디오 인코더로 보는 영상 하이라이트 탐지 혁신
초록
본 논문은 영상 하이라이트 탐지를 위해 음성 신호를 ‘의미’와 ‘동적’ 두 축으로 분리해 처리하는 듀얼‑패스오디오 인코더(DAViHD)를 제안한다. 의미 경로는 사전학습된 PANNs로 고수준 음성 의미를 추출하고, 동적 경로는 주파수‑동적 컨볼루션과 시간·주파수 주의 메커니즘으로 스펙트로‑템포럴 변화를 포착한다. 두 경로의 특징을 조기 자기‑주의와 요소별 곱으로 융합한 뒤 시각 특징과 교차‑주의를 적용해 최종 하이라이트 점수를 예측한다. Mr.HiSum과 TVSum 벤치마크에서 기존 최첨단 모델들을 크게 앞서며, 특히 오디오 동적 정보가 하이라이트 정확도 향상에 핵심임을 실험적으로 입증한다.
상세 분석
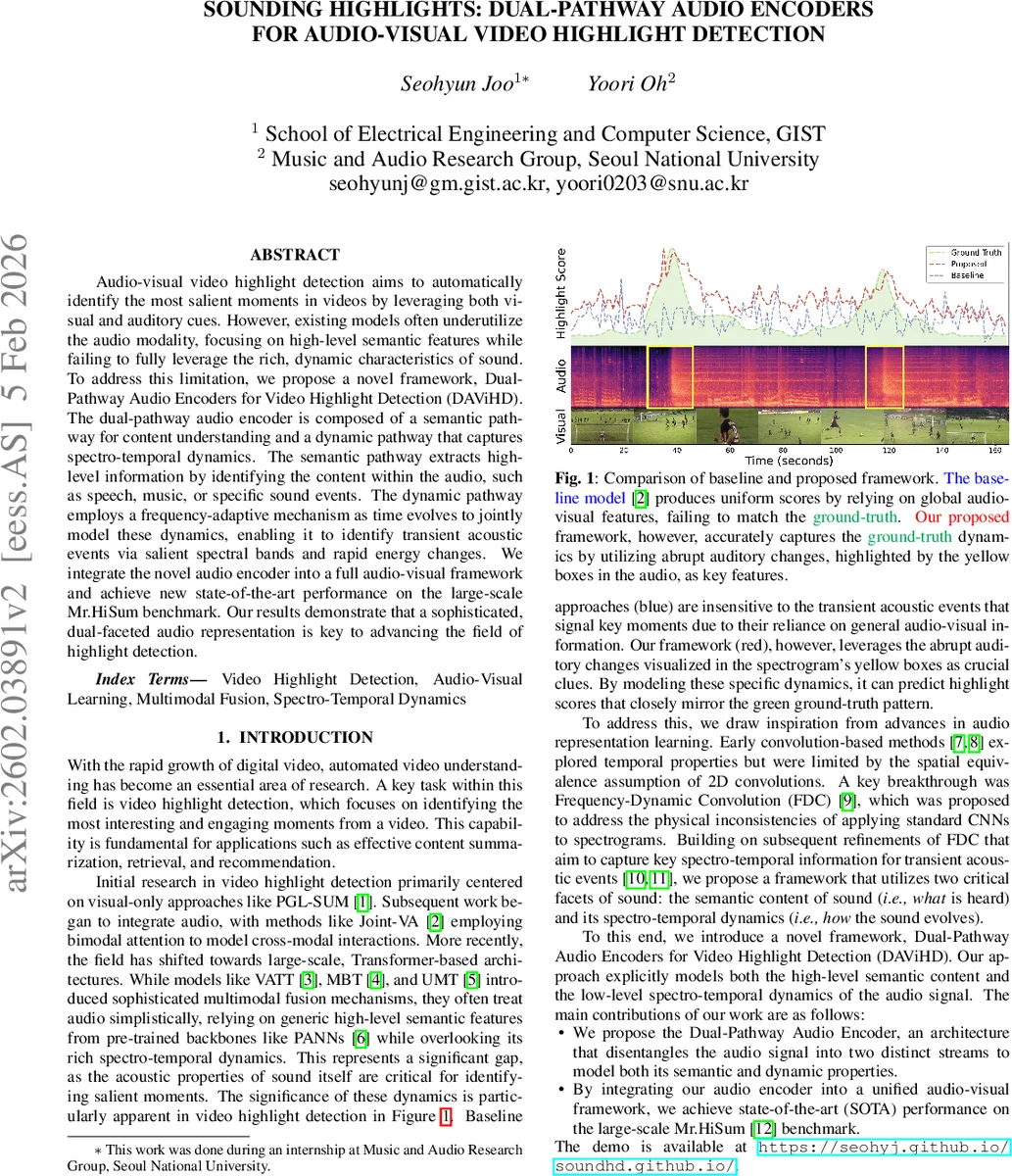
DAViHD는 기존 멀티모달 하이라이트 탐지 모델이 오디오를 고수준 의미 특징에만 의존하는 한계를 극복하기 위해 두 개의 독립적인 오디오 인코더를 설계한다. 첫 번째인 ‘오디오 의미 인코더(Esa)’는 PANNs(Pan‑Audio Neural Networks)를 활용해 1초 단위 원시 파형을 처리하고, AudioSet 사전학습 가중치를 그대로 이용해 2048 차원의 의미 임베딩을 생성한다. 이는 “무엇을 듣고 있는가”를 파악하는 역할을 수행한다. 두 번째인 ‘오디오 동적 인코더(Eda)’는 로그‑멜 스펙트로그램을 입력으로 받아, 2D Conv 블록을 통한 시간‑주의(α)와 급격한 에너지 변화를 포착하는 속도‑주의(β)를 각각 생성한다. 또한 차이 모듈을 통해 프레임 간 차이(ΔS)를 계산해 급격한 주파수 변화를 강조한다. 이렇게 얻어진 주의 맵과 시각적 게이트(xs)를 결합해 시간‑인식 특징(f_TA)과 속도‑인식 특징(f_VA)을 도출하고, 전역 평균 풀링으로 얻은 컨텍스트와 합산해 최종 결합 벡터(f_combined)를 만든다. 이 벡터는 Frequency‑Dynamic 2D Conv 레이어의 가중치 γ_k를 동적으로 조절하는 데 사용되어, 고정된 커널 대신 입력 스펙트로그램에 맞춤형 필터링을 수행한다. 결과적으로 동적 인코더는 주파수‑시간 축을 독립적으로 처리하면서도, 전통적인 2D Conv가 갖는 공간 등가성 가정을 벗어나 실제 음향 신호의 물리적 특성을 반영한다.
두 경로에서 추출된 Z_sa와 Z_da는 각각 자체적인 자기‑주의(Self‑Attention) 레이어를 거쳐 시계열 의존성을 강화한다(‘Early‑SA’). 이후 요소별 곱(⊗)을 통해 의미 특징을 동적 특징이 게이트처럼 조절하도록 융합함으로써, 의미 정보가 동적 변화에 의해 강조되거나 억제되는 메커니즘을 구현한다. 이렇게 만든 통합 오디오 특징 Z’_a는 시각 특징 Z’_v와 양방향 교차‑주의(Cross‑Attention)를 통해 상호 보완적인 정보를 교환한다. 교차‑주의 후에는 잔차 연결을 적용해 원본 모달리티의 정보를 보존하고, 최종적으로 Z’_v, Z’_a, 교차‑주의 결과 S_v, S_a를 모두 concatenate한 뒤 3‑layer MLP에 입력해 프레임 단위 하이라이트 점수를 회귀한다. 손실 함수는 MSE이며, 학습은 Adam 옵티마이저와 적절한 학습률·가중치 감쇠로 진행된다.
실험에서는 대규모 Mr.HiSum(≈31k 영상)과 소규모 TVSum(50 영상) 두 데이터셋을 사용해 F1, mAP@50%, mAP@15%, Spearman ρ, Kendall τ 등 5가지 지표를 평가하였다. DAViHD는 모든 지표에서 기존 최고 성능 모델(UMT, Joint‑VA 등)을 앞서며, 특히 오디오 동적 경로를 포함했을 때 F1 점수가 2~3%p 상승하는 등 눈에 띄는 개선을 보였다. Ablation 연구에서는 (1) 시각만, 의미만, 동적만 사용했을 때 성능 저하를 확인했으며, (2) Early‑SA와 요소별 곱(Multiply) 결합이 Late‑SA와 Concat보다 일관적으로 우수함을 입증했다. 이러한 결과는 오디오의 저수준 동적 정보가 하이라이트 순간을 정확히 포착하는 데 핵심 역할을 함을 실증한다.
전체적으로 DAViHD는 오디오를 의미와 동적 두 축으로 분리·전문화함으로써, 기존 멀티모달 모델이 놓치기 쉬운 급격한 음향 변화를 효과적으로 활용한다. 이는 영상 요약, 하이라이트 자동 생성, 콘텐츠 추천 등 실시간 미디어 처리 응용에 바로 적용 가능하며, 향후 더 복잡한 음향 이벤트(예: 다중 스피커 대화, 환경 소음)와의 통합 연구에 기반이 될 수 있다. 다만 현재는 1초 단위 고정 프레임과 사전학습된 PANNs에 의존하므로, 초저지연 스트리밍 상황이나 도메인‑특화 음향(예: 스포츠 경기 관중 소리)에서는 추가적인 적응이 필요할 것으로 보인다.
댓글 및 학술 토론
Loading comments...
의견 남기기