압축된 언어 모델의 지식 탐색: DecompressionLM으로 무작위 개념 그래프 추출
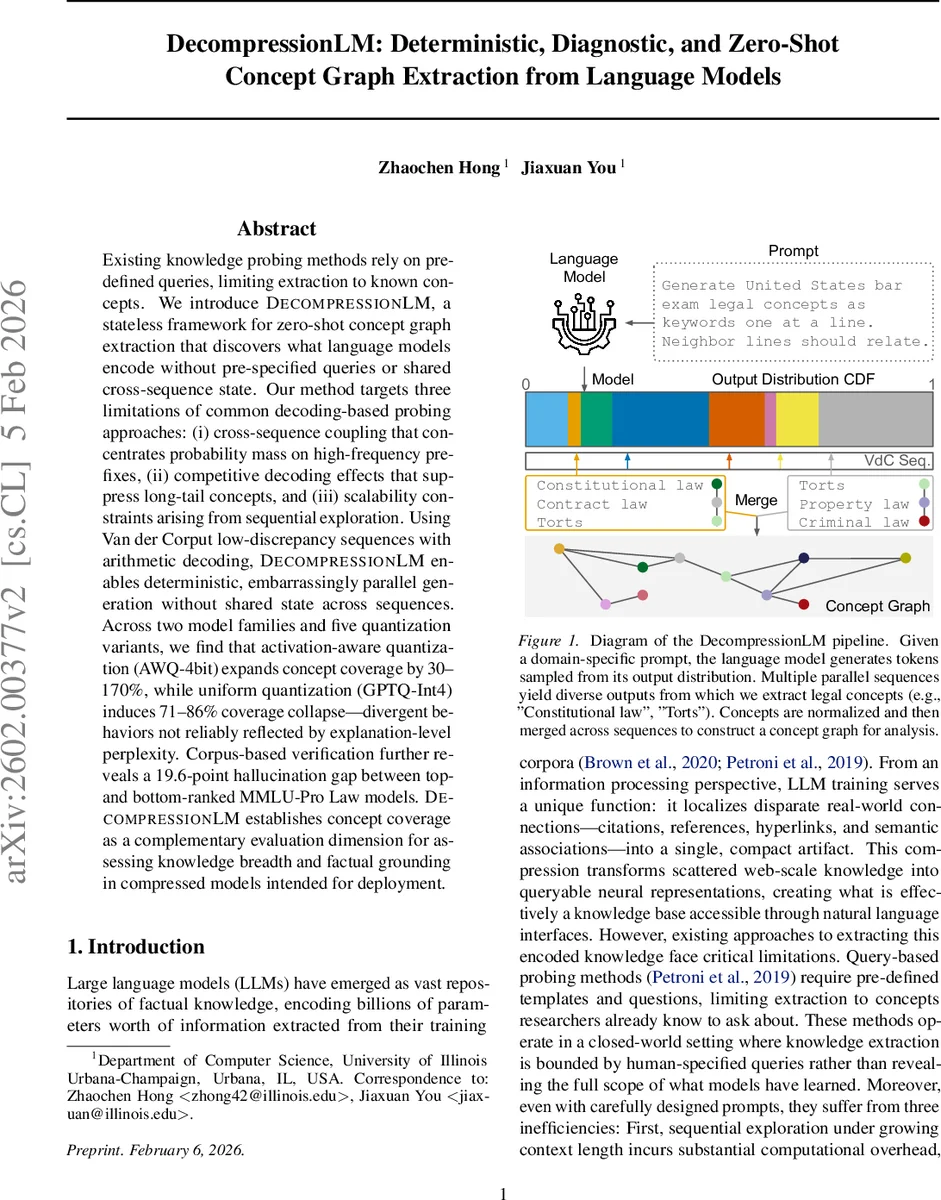
초록
DecompressionLM은 사전 정의된 질문 없이 대규모 언어 모델(LM)에서 개념 그래프를 자동으로 추출하는 무상태(stateless) 프레임워크이다. Van der Corput 저불일치(low‑discrepancy) 시퀀스와 산술 디코딩을 결합해 각 시퀀스를 독립적으로, 결정론적으로 생성함으로써 빔 서치와 같은 교차‑시퀀스 결합을 제거하고, 긴 꼬리 개념까지 균등하게 탐색한다. 실험에서는 두 모델 패밀리와 다섯 가지 양자화 방식을 비교했으며, 활성‑인식 양자화(AWQ‑4bit)가 개념 커버리지를 30‑170 % 확대하는 반면, 균일 양자화(GPTQ‑Int4)는 71‑86 % 급감함을 확인했다. 또한, 법률 도메인에서 상위·하위 모델 간에 19.6 점 차이의 허위 생성 격차가 존재함을 보여, 개념 커버리지가 압축 모델의 지식 폭과 사실성 평가에 유용한 보조 지표가 됨을 입증한다.
상세 분석
DecompressionLM은 기존 지식 탐색 방법이 갖는 “쿼리 의존성”과 “디코딩 편향”이라는 두 축의 한계를 동시에 해결한다. 첫 번째 한계는 사전 정의된 템플릿에 의존해 모델이 이미 알려진 개념만을 검증한다는 점이다. 두 번째는 빔 서치·그리디 서치와 같은 디코딩 전략이 높은 확률 프리픽스에 확률 질량을 집중시켜, 긴 꼬리(long‑tail) 개념이 억제되는 현상이다. 특히, 빔 서치에서는 여러 가설이 경쟁하면서 고빈도 토큰이 우선되고, 자동 회귀 샘플링에서는 초기 고확률 선택이 이후 토큰 선택을 지배하는 “rich‑get‑richer” 효과가 발생한다. 이러한 편향은 모델이 실제로 보유한 지식의 다양성을 과소평가하게 만든다.
DecompressionLM은 이를 해결하기 위해 (1) Van der Corput 저불일치 시퀀스를 이용해 코드 공간을 균등하게 샘플링하고, (2) 산술 코딩(arithmetic coding)과 결합해 각 코드가 모델의 출력 분포를 직접 탐색하도록 설계했다. VdC 시퀀스는
댓글 및 학술 토론
Loading comments...
의견 남기기