시각적 근거를 강화하는 양방향 인식 형성
초록
BiPS는 질문에 따라 마스크된 원본 이미지를 증거 보존 뷰와 증거 제거 뷰로 변환하고, KL‑일관성 및 KL‑분리 손실을 통해 모델이 시각적 근거에 의존하도록 학습한다. 차트 코드 기반 데이터 파이프라인으로 정밀한 증거 쌍을 자동 생성하고, Qwen2.5‑VL‑7B에 적용해 8개 벤치마크에서 평균 8.2% 정확도 향상을 달성했다.
상세 분석
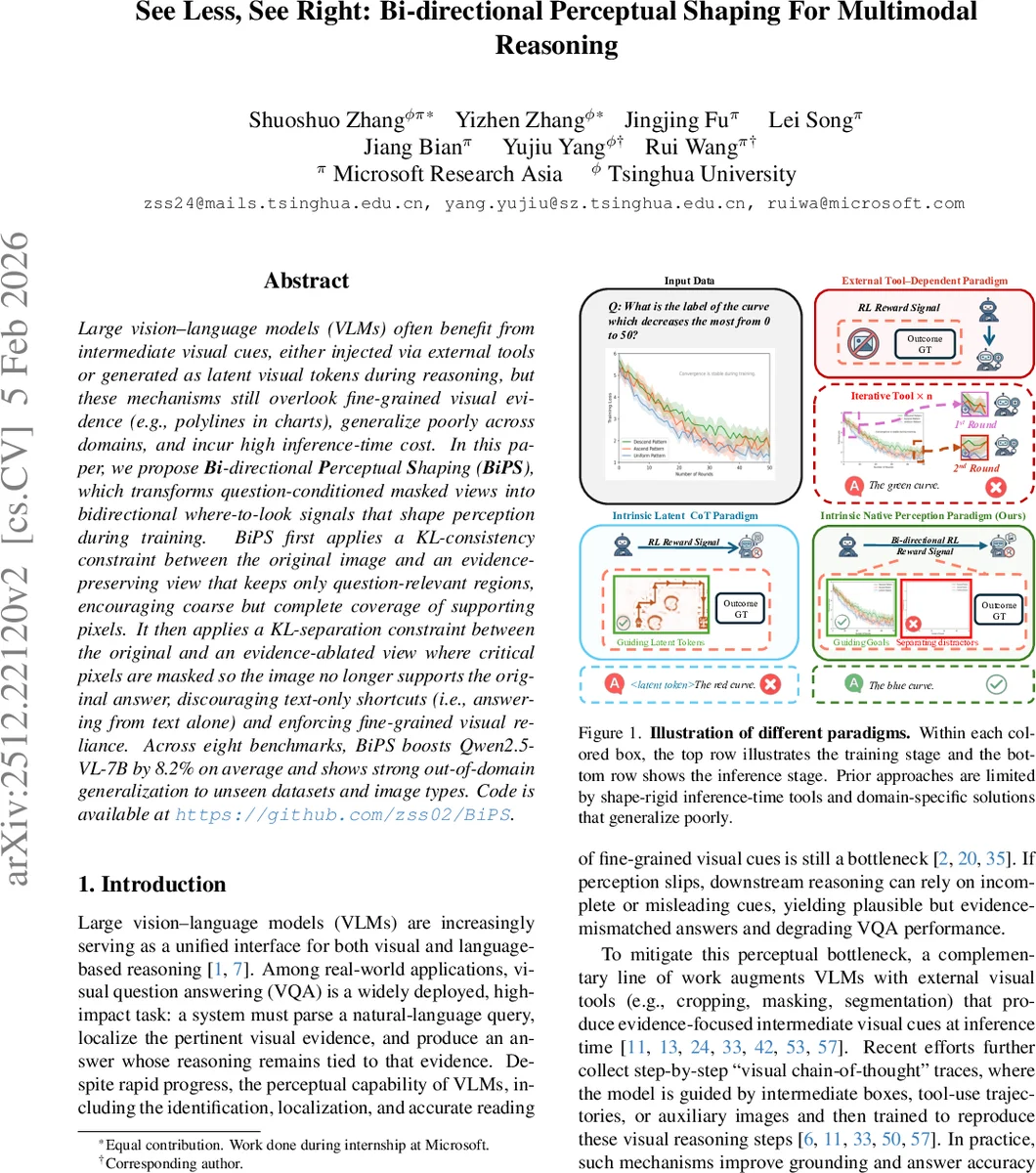
본 논문은 대형 비전‑언어 모델(VLM)이 질문에 대한 답변을 도출할 때 시각적 근거를 충분히 활용하지 못하는 문제를 지적한다. 기존 접근법은 외부 도구를 이용해 사각형 크롭이나 거친 마스크를 생성해 추론 단계에서 시각적 힌트를 제공하지만, (1) 얇은 폴리라인·곡선·병변 경계와 같은 미세 구조를 포착하지 못하고, (2) 특정 도메인에 특화돼 일반화가 어려우며, (3) 추론 시 추가 연산 비용이 발생한다는 한계가 있다.
BiPS는 이러한 한계를 극복하기 위해 훈련 단계에서만 시각적 증거를 활용한다는 새로운 패러다임을 제시한다. 핵심 아이디어는 질문‑조건부 마스크를 두 종류의 뷰로 변환하는데,
- 증거 보존 뷰(I_pres) – 질문에 답하기 위해 반드시 필요한 영역만 남기고 나머지를 마스크한다.
- 증거 제거 뷰(I_abl) – 핵심 증거 픽셀을 제거해 원본 이미지가 더 이상 정답을 지원하지 못하도록 만든다.
두 뷰는 차트의 렌더링 코드를 직접 편집함으로써 픽셀 수준이 아닌 의미론적 수준에서 정확히 생성된다. 차트는 각 마크·축·범례가 코드에 명시돼 있어, 자동화된 LLM(예: GPT‑5‑mini) 프롬프트를 통해 필요한 요소만 남기거나 삭제할 수 있다. 이렇게 만든 13 K개의 고품질 쌍은 별도 라벨링 없이도 “어디를 봐야 하는가”와 “어디를 무시해야 하는가”라는 강력한 감독 신호를 제공한다.
학습 목표는 양방향 KL 제약이다.
- 일관성 단계(Consistency Stage) – 원본 이미지 I와 증거 보존 뷰 I_pres 사이의 출력 분포 πθ와 ˜πθ를 KL‑다이버전스로 최소화한다. 이는 모델이 I_pres에서 얻은 정답 확률을 I에서도 유지하도록 강제해, 질문에 관련된 영역을 놓치지 않게 만든다.
- 분리 단계(Separation Stage) – 원본 이미지 I와 증거 제거 뷰 I_abl 사이의 KL을 최대화한다. 즉, 핵심 증거가 사라진 I_abl에서는 기존 정답 확률이 크게 변하도록 하여, 텍스트‑전용 추론(문맥만으로 답을 맞추는 현상)을 억제하고 시각적 근거에 대한 의존도를 높인다.
두 단계는 Group‑Relative Policy Optimization(GRPO) 프레임워크 안에서 순차적으로 적용되며, KL‑손실에 클리핑·스톱‑그래디언트 등을 도입해 학습 안정성을 확보한다.
실험에서는 Qwen2.5‑VL‑7B를 베이스 모델로 삼아, 차트 데이터만으로 사전 학습한 뒤 8개의 VQA·차트·수학 데이터셋에 평가했다. 기본 모델 대비 평균 정확도가 7.3% 상승했으며, 추가로 39 K개의 수학‑전용 샘플을 GRPO와 함께 학습하면 전체 평균 향상이 8.2%에 달한다. 특히, 차트‑전용 모델보다 적은 데이터로도 일반 VQA(예: MathVista, MMStar)에서 경쟁력 있는 성능을 보이며, 도메인 간 일반화 능력이 뛰어나다는 점이 주목된다.
요약하면, BiPS는 증거‑보존/제거 뷰를 통한 양방향 KL 정규화라는 간단하지만 효과적인 메커니즘으로, 추론 시 추가 비용 없이 모델 내부 정책을 시각적 근거에 맞게 재조정한다. 코드 기반 데이터 파이프라인은 라벨링 비용을 크게 절감하고, 미세 구조까지 포괄하는 정밀 마스크를 제공함으로써 기존 도구‑의존형 접근법의 한계를 근본적으로 해결한다.
댓글 및 학술 토론
Loading comments...
의견 남기기