가우시안 VAE 기반 벡터 양자화 기법 GQ
초록
본 논문은 가우시안 VAE를 먼저 학습한 뒤, 무작위 가우시안 노이즈로 구성된 코드북을 이용해 posterior 평균을 가장 가까운 코드워드에 매핑함으로써 VQ‑VAE를 추가 학습 없이 구축하는 방법인 Gaussian Quant(GQ)를 제안한다. 코드북 크기의 로그가 가우시안 VAE의 bits‑back 코딩 비트레이트와 일치하면 양자화 오차가 지수적으로 감소한다는 이론적 근거를 제시하고, 각 차원의 KL 다이버전스를 목표값에 맞추는 Target Divergence Constraint(TDC)이라는 훈련 규칙을 도입한다. 실험에서는 UNet·ViT 두 아키텍처 모두에서 기존 VQ‑GAN, FSQ, LFQ, BSQ 등을 능가하는 재구성·생성 성능을 기록했으며, TDC가 기존 TokenBridge 방법도 향상시킴을 보였다.
상세 분석
이 논문은 VQ‑VAE가 갖는 비분화적(비‑미분) 인코딩 과정과 코드북 붕괴 문제를 회피하기 위해 “학습‑전환” 전략을 채택한다. 먼저, 표준 가우시안 VAE를 훈련하되, 각 잠재 차원 i 에 대해 KL 다이버전스 R_i = D_KL(q(Z_i|X)||N(0,1))가 목표 비트레이트 log K와 가깝도록 제약한다. 이를 구현하기 위해 제안된 Target Divergence Constraint(TDC)은 R_i 가 목표보다 작을 때는 작은 패널티, 클 때는 큰 패널티를 부여하는 가변 λ_i 를 동적으로 업데이트한다. 이렇게 훈련된 VAE는 잠재 평균 μ_i 와 표준편차 σ_i 가 목표 비트레이트에 맞춰 조정되므로, 코드북 크기 K 가 log K ≈ R_i 일 때 양자화 오차가 최소화된다.
전환 단계에서는 1‑차원 표준 가우시안(N(0,1)) 샘플을 K 개 뽑아 고정 코드북 c₁:K 를 만든다. 각 차원 i 에 대해 posterior 평균 μ_i 와 가장 가까운 코드워드 c_j 를 선택해 양자화된 잠재값 \hat{z}_i 를 얻는다(식 3). 이 과정은 전혀 추가 학습이 필요 없으며, 양자화 연산 자체가 단순 거리 최소화이므로 효율적이다.
이론적 분석에서는 코드북 비트레이트가 bits‑back 코딩 비트레이트 R_i 보다 t nats 초과할 때, 큰 양자화 오차(|\hat{z}_i‑μ_i| ≥ σ_i) 발생 확률이 exp(‑exp(t·c)) 형태로 이중 지수적으로 감소함을 정리 3.1 과 3.2 를 통해 증명한다. 반대로 비트레이트가 부족하면 오차 확률이 지수적으로 증가한다. 따라서 log K ≈ R_i (또는 ⌈R_i⌉) 를 선택하면 충분히 작은 재구성 손실을 보장한다.
다차원 코드북(m>1) 확장도 제시한다. m개의 연속 잠재 차원을 하나의 토큰으로 묶어 m‑차원 가우시안 코드북을 사용하고, σ‑가중 거리와 코드워드의 원점 거리(정규화된 ω 항)를 동시에 최소화한다. 저비트레이트 상황에서 코드북 붕괴를 방지하기 위한 정규화 항이 핵심이다.
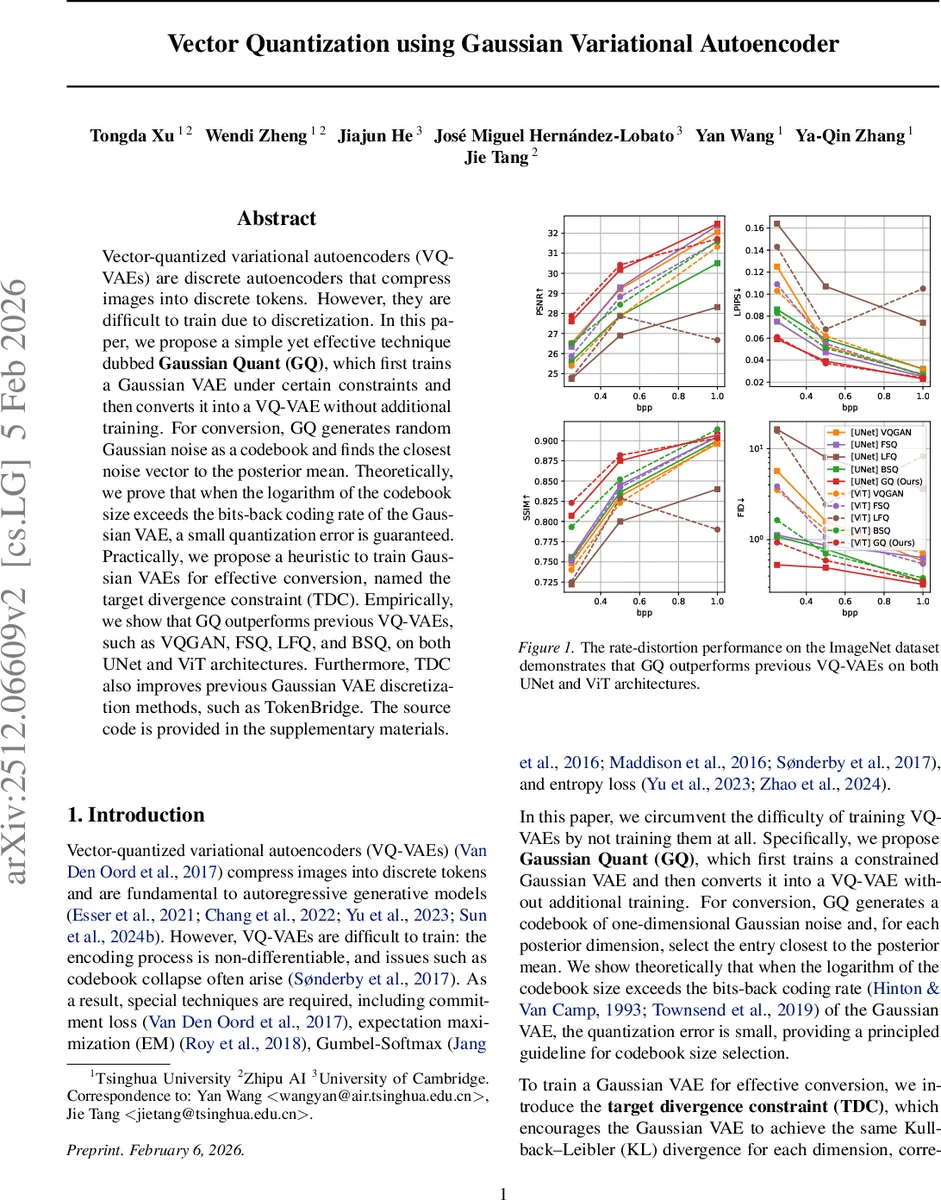
실험에서는 ImageNet을 대상으로 UNet(Stable Diffusion 3)과 ViT(BSQ) 두 백본에 동일한 비트레이트(K·N) 설정을 적용했다. 재구성 지표(PSNR, LPIPS, SSIM, rFID)에서 GQ가 모든 설정에서 기존 VQ‑GAN, FSQ, LFQ, BSQ를 앞섰으며, 특히 0.25 bpp1.00 bpp 구간에서 PSNR이 12 dB, LPIPS가 0.02~0.04 개선되었다. 또한, TDC를 적용한 기존 TokenBridge도 KL 정렬이 개선돼 성능이 상승함을 표 3에서 확인한다. 이미지 생성 실험에서도 Llama‑Transformer 기반 디코더와 결합해 gFID와 IS에서도 경쟁력 있는 결과를 얻었다.
전체적으로 이 논문은 (1) VQ‑VAE 학습의 복잡성을 가우시안 VAE 학습으로 대체하고, (2) 코드북 크기와 bits‑back 비트레이트 사이의 정량적 관계를 이론적으로 정립했으며, (3) 간단한 TDC 규칙을 통해 실용적인 훈련 방법을 제공한다는 점에서 의미가 크다. 특히, 추가 학습 없이 바로 양자화가 가능한 점은 대규모 사전학습 모델에 손쉽게 적용할 수 있는 장점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기