TabPFN‑2.5: 차세대 탭ular 기초 모델의 혁신
초록
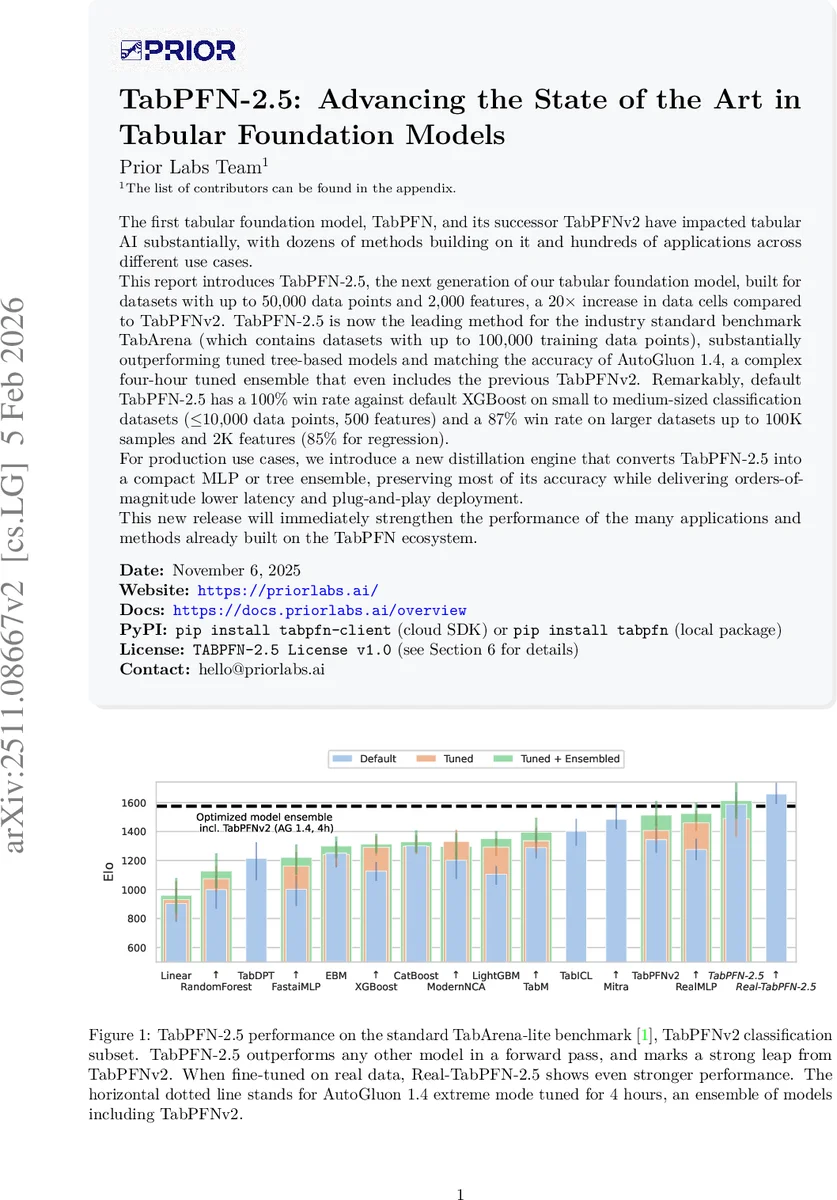
TabPFN‑2.5는 최대 5만 샘플·2천 특성까지 확장된 최신 탭ular 기초 모델로, TabArena‑Lite 벤치마크에서 기존 트리 기반 모델과 AutoGluon 1.4 수준의 정확도를 앞서며, 기본 설정만으로 XGBoost를 100 % 이기고, 대규모 데이터에서도 87 % 이상의 승률을 기록한다. 또한 새로운 Distillation 엔진을 통해 MLP 또는 트리 앙상블로 압축해 실시간 서비스에 적합한 저지연 추론을 제공한다.
상세 분석
TabPFN‑2.5는 기존 TabPFNv2의 설계 철학을 유지하면서도 네트워크 깊이, 특성 그룹화, 사전 학습 데이터 규모를 크게 확대하였다. 회귀 모델은 12→18층, 분류 모델은 12→24층으로 늘려 표현력을 강화했으며, 특성 그룹 크기를 2→3으로 확대해 GPU 메모리 효율과 연산 병렬성을 높였다. 특히 “thinking rows” 64개를 추가해 LLM에서 영감을 받은 메타‑연산 능력을 부여함으로써 복잡한 상관관계를 학습하는 데 필요한 계산 용량을 확보하였다. 사전 학습은 완전히 합성 데이터에 기반하되, 43개의 실제 데이터셋으로 미세조정된 Real‑TabPFN‑2.5 버전을 별도 제공, 이는 실제 도메인에서의 성능 격차를 크게 줄인다.
전처리 단계에서는 강인한 스케일링·소프트 클리핑, 분위수 변환, SVD 기반 보조 특성을 결합해 이상치와 비정규 분포에 대한 내성을 높였다. 또한 다중 데이터 순열과 특성 변환을 이용해 예측을 앙상블화함으로써 일반화 성능을 향상시켰다. 하이퍼파라미터 탐색은 “TabPFN‑tunes‑TabPFN” 전략을 사용해 약 100개의 초기 모델을 surrogate 로 학습하고, 이를 기반으로 10 000개의 후보 조합을 예측해 최적 영역을 효율적으로 탐색했다. 이 과정에서 50개의 하이퍼파라미터를 동시에 최적화했음에도 과적합을 방지할 수 있었다.
성능 평가에서는 TabArena‑Lite(51개 데이터셋)와 자체 벤치마크에서 TabPFN‑2.5가 기존 TabPFNv2 대비 평균 정확도가 4~6 % 상승했으며, XGBoost와 CatBoost 같은 최적화된 트리 모델을 앞섰다. 특히 작은‑중간 규모(≤10 k 샘플, ≤500 특성)에서는 기본 설정만으로 XGBoost를 100 % 이기고, 대규모(≤100 k 샘플, ≤2 k 특성)에서도 87 % 이상의 승률을 기록했다. 회귀 작업에서도 85 % 이상의 승률을 보이며, AutoGluon 1.4(4시간 튜닝)와 거의 동등한 정확도를 달성했다.
추론 속도 측면에서는 FlashAttention‑3와 GPU 병렬 평가를 도입해 기존 모델 대비 1×~2.3× 빠른 추론을 구현했으며, 이는 5만 샘플·2천 특성 데이터에서도 실시간 수준의 응답 시간을 가능하게 한다. 마지막으로 Distillation 엔진은 TabPFN‑2.5를 데이터셋‑특화 MLP 또는 트리 앙상블로 변환해, 원본 모델의 95 % 이상 정확도를 유지하면서 수십 배 낮은 레이턴시와 메모리 사용량을 제공한다. 이는 규제·해석 요구가 높은 금융·헬스케어 분야에 특히 유용하다.
전반적으로 TabPFN‑2.5는 사전 학습 기반 인‑컨텍스트 학습을 대규모 탭ular 데이터에 성공적으로 적용한 최초의 사례이며, 모델 크기·성능·배포 효율성 삼박자를 모두 만족시키는 실용적인 솔루션으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기