실시간 장문 생성 허위 엔터티 탐지
초록
본 논문은 대형 언어 모델이 생성하는 장문 텍스트에서 실시간으로 허위 엔터티(인물, 날짜, 인용 등)를 식별하는 저비용 방법을 제안한다. 웹 검색을 활용한 자동 라벨링 파이프라인으로 구축한 토큰‑레벨 데이터셋을 기반으로, 단순 선형 프로브와 LoRA 어댑터를 학습시켜 스트리밍 형태로 토큰별 허위 여부를 예측한다. 70B 규모 모델까지 확장 가능하며, 기존의 불확실성 기반 지표나 외부 검증 파이프라인보다 높은 AUC를 달성한다.
상세 분석
이 연구는 장문 생성 상황에서 “엔터티 수준”의 허위 정보를 탐지한다는 새로운 관점을 제시한다. 기존 연구가 문장·패시지 수준의 정확성을 평가하거나, 외부 검색·증거 회수에 의존하는 반면, 저자는 엔터티를 토큰 경계와 일치시키는 라벨링을 통해 스트리밍 검출이 가능하도록 설계했다. 핵심은 두 단계의 자동 라벨링 파이프라인이다. 첫 번째 단계에서는 LongFact++라는 확장 프롬프트 컬렉션을 이용해 다양한 도메인(법률, 바이오, 인용 등)에서 사실‑추구 질문에 대해 LLM이 장문 응답을 생성하도록 한다. 두 번째 단계에서는 Claude 4 Sonnet과 웹 검색을 결합해 생성 텍스트 내 모든 엔터티를 추출하고, 외부 자료와 교차 검증해 “Supported”, “Not Supported”, “Insufficient” 라벨을 부여한다. 이렇게 얻어진 토큰‑레벨 라벨은 선형 프로브와 LoRA 어댑터 학습에 사용된다.
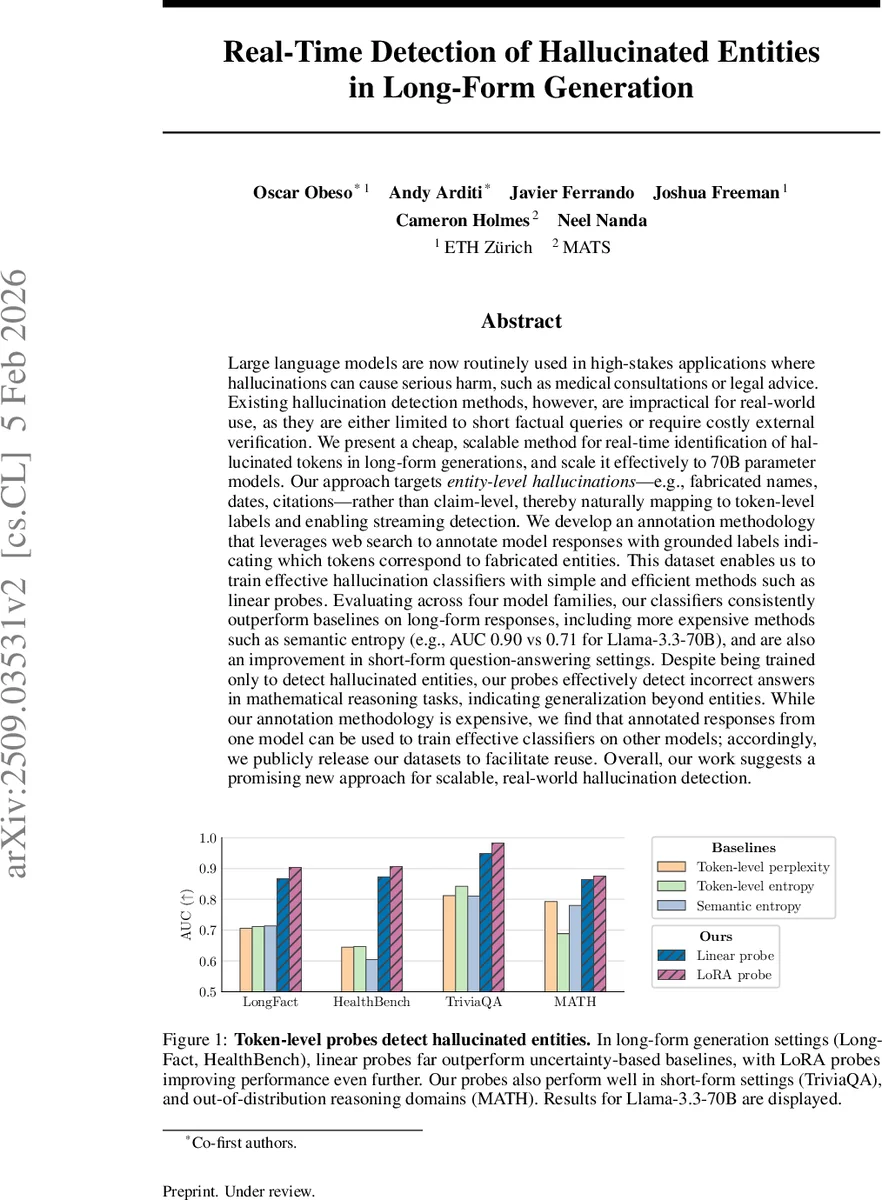
선형 프로브는 각 토큰의 은닉 상태에 단순 선형 변환을 적용해 허위 확률을 출력한다. 이는 모델의 순전파와 동시에 수행되므로 지연시간이 거의 없으며, LoRA 어댑터를 추가하면 성능이 0.87→0.90 AUC로 상승한다. 흥미롭게도, 엔터티 라벨만으로 학습된 프로브가 수학적 추론 과제에서도 오류를 탐지하는 등, 엔터티 외의 “사실적 부정확성”까지 일반화한다는 점을 확인했다.
실험은 Llama‑3.3‑70B, Llama‑2‑70B, Falcon‑180B 등 네 가지 모델군에 걸쳐 수행되었으며, 모든 경우에서 기존의 토큰‑레벨 퍼플렉시티, 토큰‑레벨 엔트로피, 그리고 샘플링 기반 semantic entropy 대비 현저히 높은 AUC를 기록했다. 특히 장문 데이터(Long‑Fact, HealthBench)에서는 선형 프로브가 0.87~0.90 AUC를 달성했으며, 단문 QA(TriVAQA)에서도 경쟁력을 유지했다.
한계점으로는 라벨링 파이프라인 자체가 비용이 많이 든다는 점과, 현재는 영어 위주의 웹 검색 엔진에 의존한다는 점을 들 수 있다. 또한, 엔터티가 명시적으로 드러나지 않는 복합적 사실 오류(예: 인과 관계 오류)에는 아직 민감도가 낮다. 향후 연구에서는 멀티모달 증거, 더 정교한 엔터티 추출기, 그리고 라벨링 비용을 절감하기 위한 약한 감독 학습을 탐색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기