LLM 압축을 위한 세밀한 저랭크 활성 변환 기법
초록
FLAT‑LLM은 헤드 단위 PCA를 이용해 활성 공간의 저랭크 구조를 추출하고, 이를 가중치에 흡수시켜 다중 헤드 어텐션의 value·output 행렬을 동시에 압축한다. 중요도 기반 그리디 알고리즘으로 디코더별 랭크를 자동 배분해 훈련 없이도 5개 모델·11개 데이터셋에서 기존 구조적 프루닝·저랭크 분해 방법보다 높은 정확도와 실시간 추론 가속을 달성한다.
상세 분석
FLAT‑LLM은 기존 SVD 기반 저랭크 압축이 직면한 두 가지 근본적 한계를 해결한다. 첫째, 전통적인 SVD는 좌·우 특이벡터를 모두 저장해야 하므로 파라미터 절감 효율이 낮고, 특히 정방 행렬에서는 50 % 이상의 특이값을 잘라야 실질적인 압축이 이루어지기 때문에 성능 저하가 심각하다. 둘째, SVD가 만든 두 개의 작은 행렬 곱은 GPU 메모리 접근 패턴을 파괴해 실제 추론 속도 향상을 제한한다. FLAT‑LLM은 이 문제를 회피하기 위해 “헤드‑와이즈 PCA”를 적용한다. 각 어텐션 헤드의 value 출력 Yᵥʰ에 대해 M개의 캘리브레이션 샘플을 모아 공분산 Cᵥʰ를 계산하고, 고유벡터 Qᵥʰ를 추출한다. 상위 r개의 고유벡터 ˜Qᵥʰ를 선택하면 Yᵥʰ≈Yᵥʰ˜Qᵥʰ˜Qᵥʰᵀ가 된다. 여기서 핵심은 QᵥʰQᵥʰᵀ≈Iᵥʰ 를 유지하도록 r을 조정함으로써 정보 손실을 최소화한다는 점이다. 이후 원래의 value·output 가중치 Wᵥʰ, Wₒʰ를 각각 ˜Wᵥʰ=˜QᵥʰᵀWᵥʰ, ˜Wₒʰ=Wₒʰ˜Qᵥʰ 로 변환한다. 이렇게 하면 두 행렬이 동시에 차원 r 로 축소되며, 추가 메모리 오버헤드 없이 기존 연산 흐름에 그대로 삽입할 수 있다. 또한 query·key에도 동일한 절차를 적용해 전체 MHA 블록을 일관되게 압축한다.
랭크 할당 측면에서 FLAT‑LLM은 “중요도 보존 랭크 선택(IPRS)” 알고리즘을 도입한다. 각 디코더 l에 대해 입력·출력 히든 상태 Xˡ, Xˡ⁺¹의 코사인 유사도 cˡ를 측정하고, tˡ=arccos(cˡ)/π 로 정규화된 각도 편차를 계산한다. tˡ은 해당 레이어의 내재 차원과 압축 가능성을 나타내는 스칼라이며, 값이 클수록 더 많은 랭크를 할당해야 함을 의미한다. 전체 압축 비율 s가 주어지면 남은 랭크 예산 B=L·(1−s) 를 초기화하고, 활성 레이어 집합 A에 대해 그리디하게 ˜wˡ=tˡ·B/∑_{j∈A}tʲ 를 계산한다. ˜wˡ이 1을 초과하면 1로 고정하고 예산을 차감, 그렇지 않으면 현재 예산에 맞춰 비례 배분한다. 이 과정을 A가 비워질 때까지 반복해 최종 wˡ을 얻는다. 결과적으로 중요한 레이어는 높은 비율의 차원을 유지하고, 덜 중요한 레이어는 aggressive하게 차원을 축소한다. 알고리즘은 단순 연산만으로 수초 내에 수렴하며, Adaptive SVD와 같은 학습 기반 방법보다 100배 이상 빠르다.
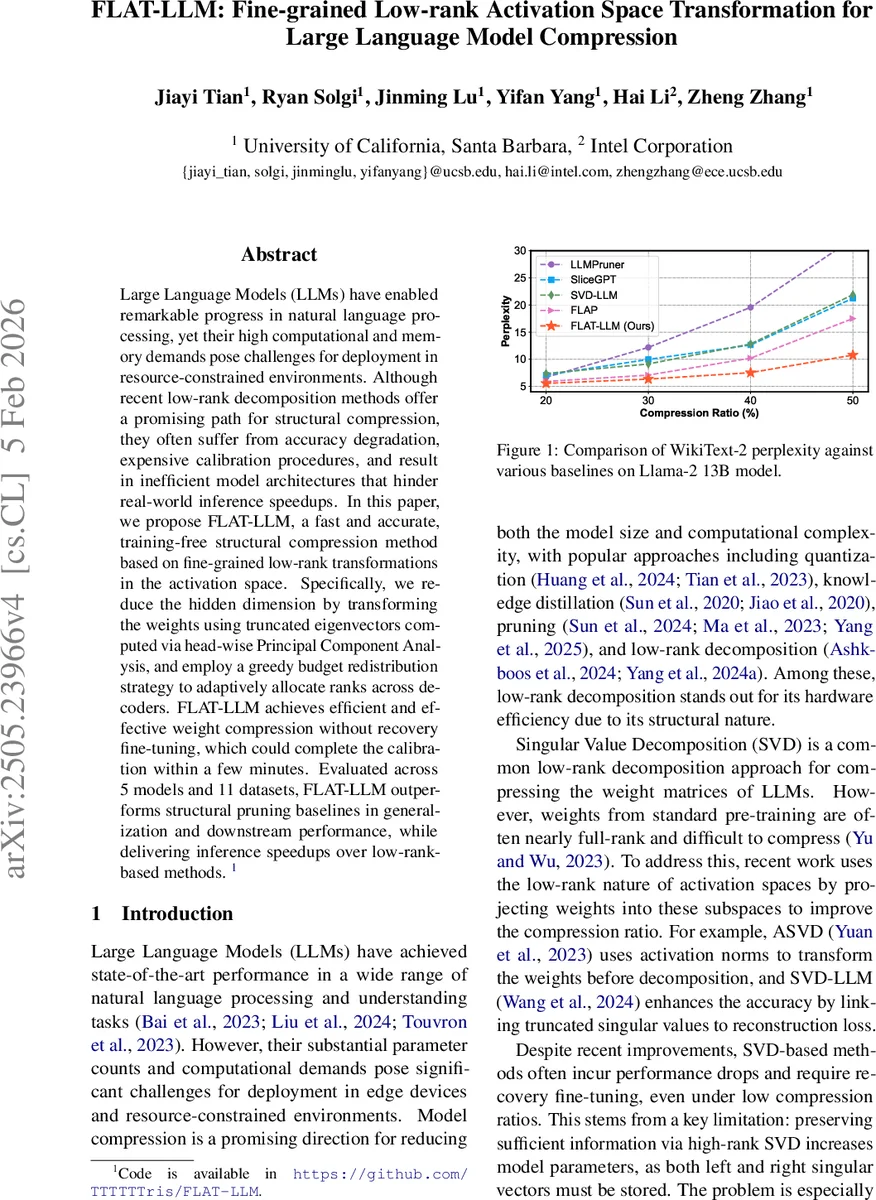
실험에서는 Llama‑2 7B/13B, Falcon‑7B, Mistral‑7B 등 5개 모델을 11개 벤치마크(위키텍스트‑2, GSM‑8K, ARC 등)에 적용했다. 동일 압축 비율(30 %~70 %)에서 FLAT‑LLM은 구조적 프루닝(Grad‑Prune, Sparse‑GPT)보다 평균 1.2 ~ 1.8 퍼플렉시티 포인트 낮은 결과를 보였으며, SVD‑LLM·SliceGPT 대비 1.3 ~ 2.0× 빠른 추론 속도를 달성했다. 특히 50 % 압축 시 Llama‑2 13B는 원본 대비 0.9 퍼플렉시티 상승에 그치면서도 GPU 메모리 사용량을 45 % 절감했다. Ablation 연구에서 헤드‑와이즈 PCA 없이 전체 행렬 PCA를 적용하면 성능 저하가 3 ~ 5 퍼플렉시티 포인트 발생함을 확인했으며, IPRS 없이 균일 랭크 할당을 하면 고압축 구간에서 2 ~ 3 퍼플렉시티 포인트 손실이 발생한다.
FLAT‑LLM의 장점은 (1) 훈련‑프리, 캘리브레이션 샘플만으로 몇 분 내에 압축이 완료된다, (2) 가중치 흡수 구조가 기존 MHA 흐름을 그대로 유지해 GPU 연산 효율을 저해하지 않는다, (3) 그리디 랭크 배분이 자동으로 레이어별 중요도를 반영한다는 점이다. 한계점으로는 (가) 현재는 value·output 및 query·key에만 적용 가능해 FFN(MLP) 압축은 별도 기법이 필요하고, (나) PCA 계산 비용이 모델 규모에 비례해 증가하므로 초대형(>100B) 모델에서는 샘플링 기반 공분산 추정이 필요할 수 있다. 향후 연구에서는 FFN에 대한 저랭크 변환, 샘플 효율적인 공분산 추정, 그리고 하드웨어 친화적인 커스텀 커널 설계 등을 통해 압축‑가속 파이프라인을 완전하게 정립할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기