시각 인코딩이 제어 성능을 예측한다
초록
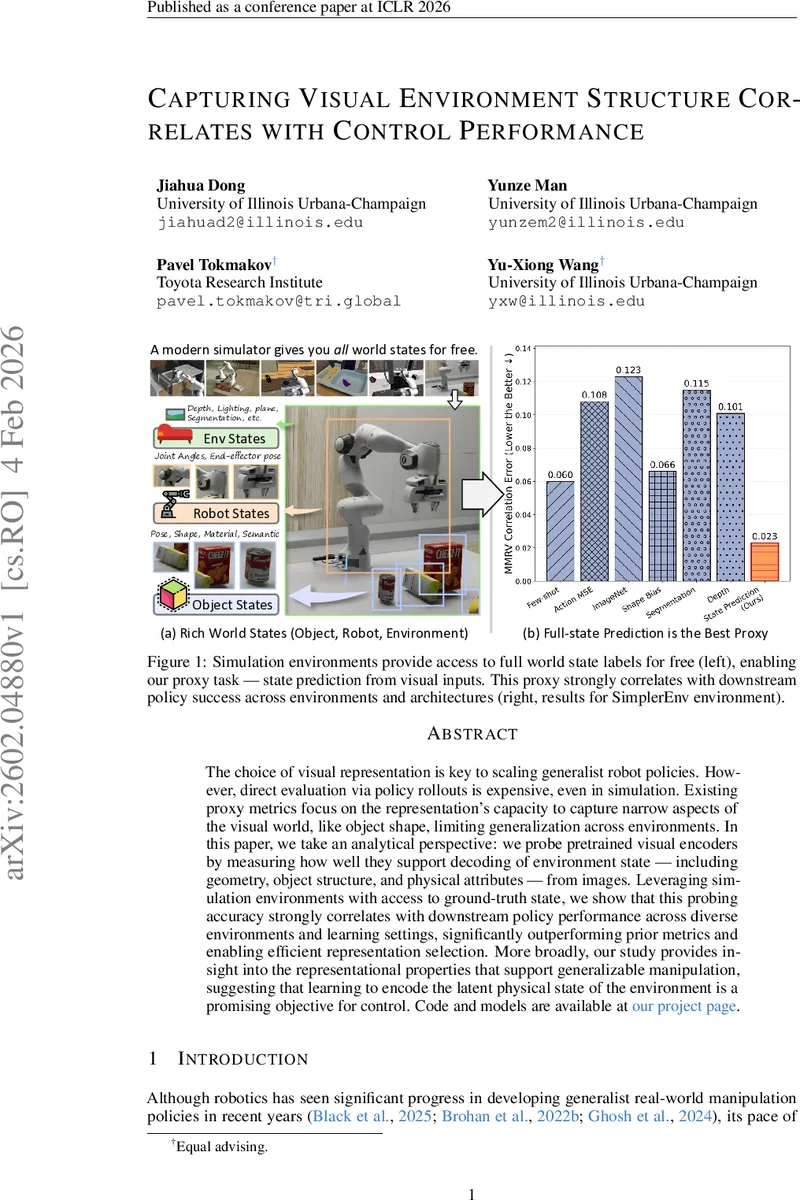
본 논문은 시뮬레이션 환경에서 제공되는 완전한 세계 상태 라벨을 활용해, 사전 학습된 시각 인코더가 이미지로부터 환경의 기하·물리·재질 정보를 얼마나 정확히 복원할 수 있는지를 측정한다. 이 ‘상태 예측’ 프록시 점수가 로봇 조작 정책의 성공률과 강한 상관관계를 보이며, 기존의 객체 분할·형태 기반 메트릭보다 일관적으로 우수함을 입증한다. 결과적으로, 물리적 상태를 인코딩하도록 설계된 시각 표현이 제어에 가장 적합함을 제시한다.
상세 분석
이 연구는 로봇 조작 정책의 성능을 직접 롤아웃으로 평가하는 비용이 prohibitive 하다는 점에 착안해, 시각 인코더의 품질을 간접적으로 측정할 수 있는 새로운 프록시 메트릭을 제안한다. 핵심 아이디어는 시뮬레이터가 제공하는 ‘전 세계 상태(Full World State)’ 라벨을 이용해, 이미지 하나만으로 물체의 6D 포즈, 바운딩 박스 형태, 재질 종류, 조명 조건, 로봇 관절 각도 및 엔드 이펙터 위치 등을 복원하도록 학습하는 것이다. 이를 위해 저자들은 (1) 모든 환경에 공통적으로 적용 가능한 저차원 상태 벡터를 정의하고, (2) RoI 풀링 기반의 시각 프롬프트를 사용해 객체별 특징을 추출하며, (3) 전역 평균 풀링을 통해 환경 전반의 정보를 추출한다. 연속형 변수는 정규화 후 L2 손실로, 범주형 변수는 소프트맥스와 교차 엔트로피 손실로 학습한다.
프록시 점수는 각 상태 항목별 정확도(범주형)와 음의 MSE(연속형)를 정규화한 뒤 평균을 취해 하나의 스칼라값으로 만든다. 이렇게 얻은 점수를 9개의 사전 학습된 비전 백본(ResNet, CLIP, DINOv2, MAE 등)과 3개의 시뮬레이션 환경(MetaWorld, RoboCasa, Real‑World‑Aligned Env)에서 측정한 정책 성공률과 Pearson/Spearman 상관분석을 수행하였다. 결과는 기존 메트릭(예: 객체 세그멘테이션 정확도)보다 훨씬 높은 상관계수(r≈0.78)를 보였으며, 특히 환경 간 분포 차이가 큰 RoboCasa에서도 일관된 예측력을 유지했다.
추가 실험으로는 (i) 프록시 점수를 기반으로 상위‑하위 모델을 선택해 정책 학습 비용을 70% 절감, (ii) 실제 로봇 실험에서 시뮬레이션에서 도출된 순위가 그대로 유지되는지를 검증하였다. 두 경우 모두 프록시 점수가 실제 성능을 정확히 예측함을 확인했다.
이 논문의 주요 기여는 다음과 같다. 첫째, ‘전체 세계 상태 복원’이라는 새로운 평가 기준을 제시함으로써 시각 인코더가 제어에 필요한 물리·기하 정보를 얼마나 내재하고 있는지를 정량화했다. 둘째, 다양한 백본과 환경에 걸쳐 프록시 점수가 정책 성공률과 강한 상관관계를 보이며, 기존 메트릭을 대체할 수 있음을 실증했다. 셋째, 시뮬레이션 기반 라벨링이 실제 로봇에까지 일반화될 수 있음을 보여, 비용 효율적인 모델 선택 파이프라인을 제공한다. 마지막으로, 환경 상태를 완전하게 인코딩하는 것이 로봇 제어에 가장 중요한 특성임을 강조하며, 향후 비전 프리트레인 목표를 ‘물리적 상태 복원’으로 재설정할 필요성을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기