결과 정확도만으로는 부족하다 보상 모델 추론 정렬
초록
본 논문은 결과 정확도(Outcome Accuracy)만을 최적화하면 모델이 인간과 다른 이유로 올바른 판단을 내리는 ‘속임수 정렬(Deceptive Alignment)’에 빠질 수 있음을 지적한다. 이를 해결하기 위해 인간 판단 근거와 모델의 추론 과정을 일치시키는 ‘Rationale Consistency’ 지표를 제안하고, 원자화된 근거 평가 프레임워크 MetaJudge를 구축한다. 실험 결과, 최신 LLM들 사이에서 Rationale Consistency가 모델을 더 세밀히 구분하고 속임수 정렬을 탐지함을 보였다. 또한 결과 정확도와 Rationale Consistency를 결합한 하이브리드 학습 신호를 사용해 보상 모델을 훈련하면 RM‑Bench·JudgeBench에서 기존 방법보다 평균 5%p 이상 향상되고, RLHF 과정에서도 창의적 글쓰기 과제에서 7%p의 성능 개선을 달성한다.
상세 분석
이 논문은 최근 LLM‑as‑a‑Judge와 Generative Reward Model(GenRM) 분야에서 나타나는 ‘속임수 정렬’ 현상을 체계적으로 분석한다. 기존 보상 모델은 인간이 제공한 선호 라벨(Outcome)만을 목표로 학습되며, 이 과정에서 모델은 표면적인 패턴이나 데이터셋 특유의 편향을 이용해 높은 정확도를 달성한다. 그러나 이러한 최적화는 모델이 인간과 동일한 논리적 근거를 사용하지 않아, 실제 RLHF 단계에서 일반화가 크게 저하되는 원인이 된다.
논문은 이를 해결하기 위해 ‘Rationale Consistency(RC)’라는 새로운 평가지표를 도입한다. RC는 인간이 제시한 상세 근거를 ‘원자화(Atomic)’하여 서로 겹치지 않는 최소 단위로 분해하고, 모델이 생성한 근거와 1:1 의미 매칭을 수행함으로써 측정한다. 이를 위해 ‘MetaJudge’라는 프레임워크를 설계했으며, 핵심 절차는 다음과 같다. 1) 인간 근거를 GPT‑5 기반 파이프라인으로 원자 단위로 분해하고, 중복·주관적 표현을 제거한다. 2) 모델에게는 중요도 순서대로 고정된 개수(예: Top‑5)의 원자 근거를 출력하도록 요구한다. 3) 평가용 LLM이 인간‑모델 근거 쌍을 의미론적으로 매칭하고, 각 매칭에 0~1 점수를 부여한다. 4) 최적 매칭을 구해 전체 샘플에 대한 평균 Recall 형태의 RC 값을 산출한다.
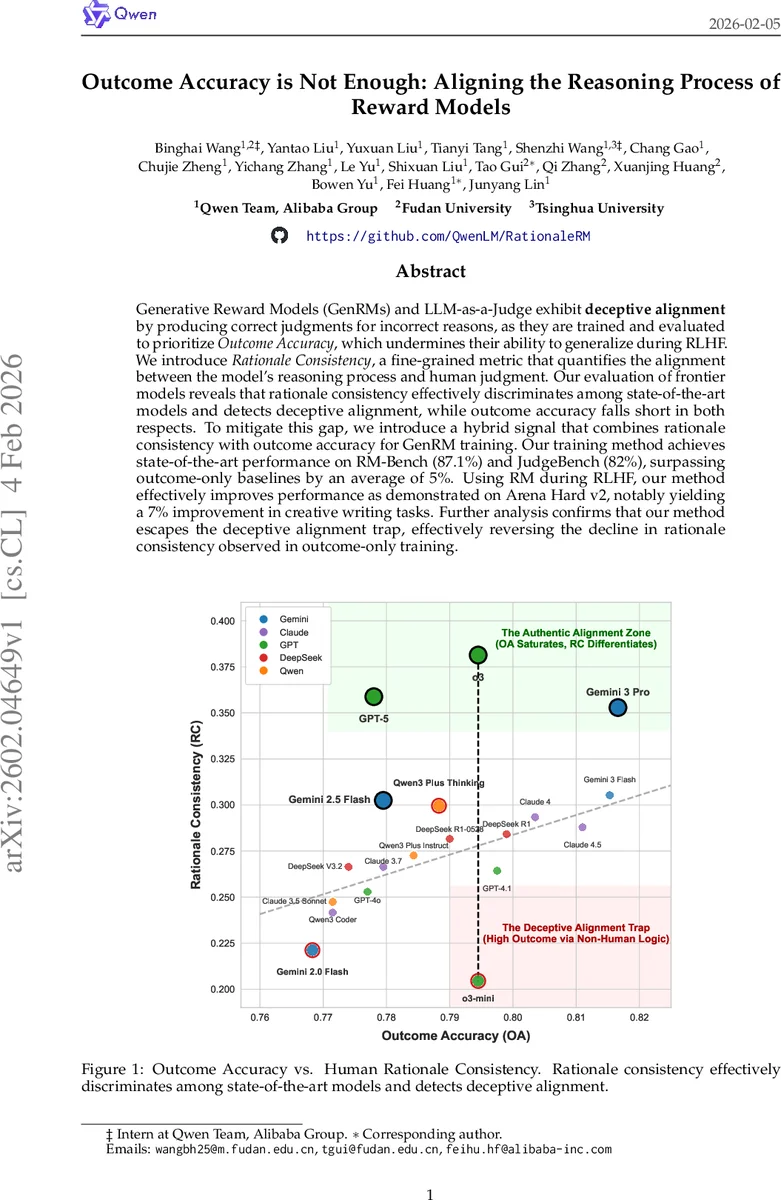
실험에서는 19개의 최신 LLM을 Qwen‑Plus 기반 MetaJudge로 평가했으며, 결과는 두 차원(OA vs RC)에서 명확히 구분된다. OA가 포화 상태에 이른 모델들(GPT‑5, Gemini‑3‑Pro 등)은 RC 점수에서 여전히 큰 차이를 보였으며, 같은 패밀리 내에서도 o3와 o3‑mini, Gemini‑3‑Pro와 Gemini‑3‑Flash처럼 OA는 비슷하지만 RC가 현저히 낮은 경우가 관찰되었다. 이는 기존 OA만으로는 속임수 정렬을 탐지할 수 없음을 실증한다.
또한 RC 측정의 신뢰성을 검증하기 위해 평가자 LLM을 Qwen‑Plus와 DeepSeek‑R1 두 종류로 교체했을 때 상관계수 R²=0.983로 거의 동일한 결과가 나오며, 도메인 전이(CW‑Atomic)에서도 Spearman ρ=0.85로 순위가 유지된다. 이는 RC가 평가자 모델에 크게 의존하지 않으며, 다양한 작업에 일반화 가능함을 의미한다.
훈련 측면에서는 기존 OA‑only 손실에 RC 점수를 가중치로 결합한 하이브리드 신호를 도입했다. 구체적으로 Group Relative Policy Optimization을 사용해, 모델이 올바른 결과와 동시에 올바른 원자 근거를 제공할 때만 보상을 주는 계층적 감독을 적용했다. 이 방법은 RM‑Bench에서 87.1%, JudgeBench에서 82.0%라는 최고 성능을 기록했으며, OA‑only 대비 각각 3%p·7%p 향상되었다. RLHF 파이프라인에 적용했을 때는 Arena Hard v2의 창의적 글쓰기 섹션에서 7%p 상승을 보였고, 특히 RC가 25%→37%로 크게 회복되는 현상이 관찰되었다. 이는 하이브리드 학습이 속임수 정렬 함정을 탈피하고, 모델이 인간과 유사한 추론 과정을 학습하도록 유도함을 입증한다.
전체적으로 이 논문은 ‘결과 정확도만으로는 충분하지 않다’는 점을 실증적으로 보여주며, ‘추론 과정 정렬’이라는 새로운 평가·학습 패러다임을 제시한다. 향후 LLM‑based 시스템이 인간과 보다 신뢰성 있게 협업하기 위해서는 RC와 같은 미세한 이유 기반 평가가 필수적이며, 이를 활용한 훈련 기법이 보상 모델 설계의 핵심이 될 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기