EMA 정책 경사: LLM 강화학습을 위한 EMA 앵커와 Top‑k KL 혁신
초록
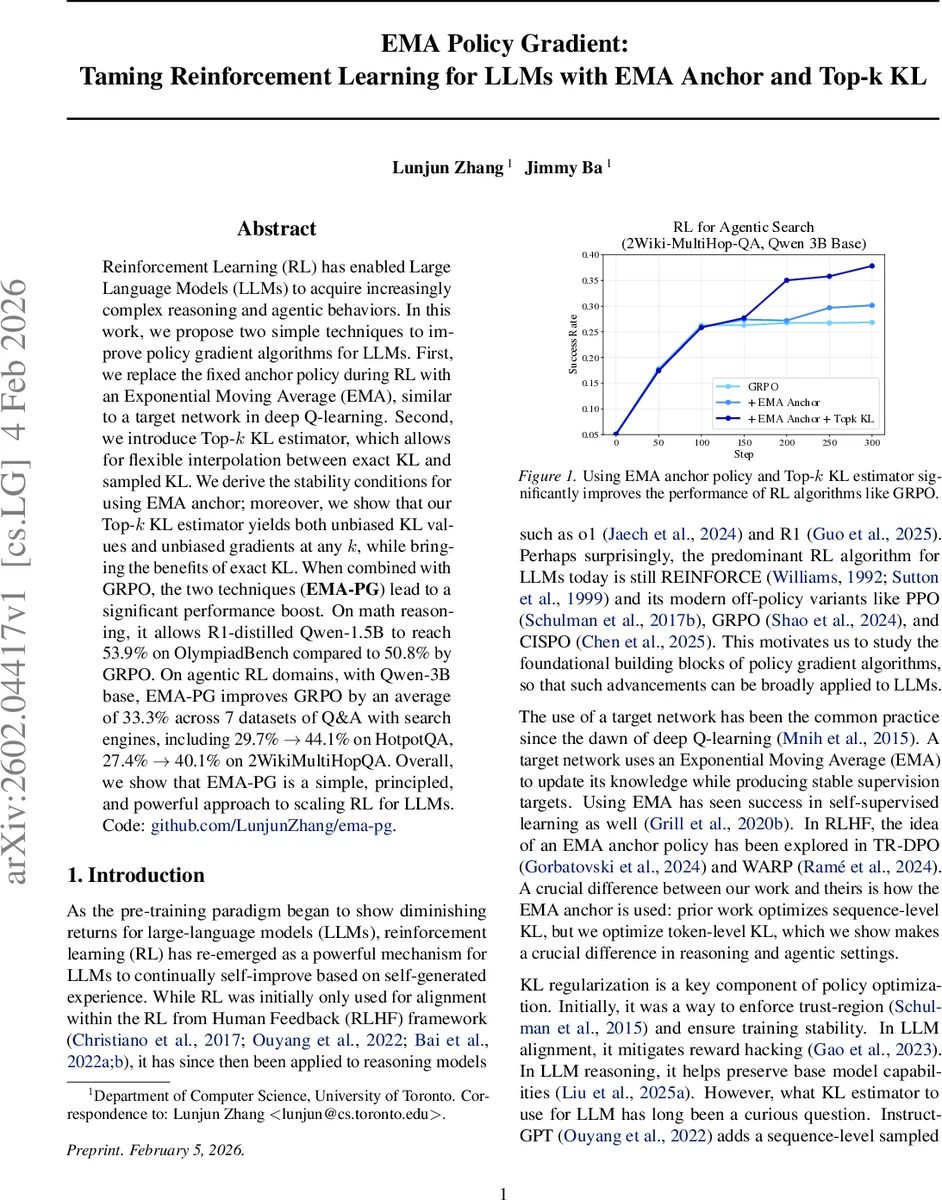
본 논문은 대형 언어 모델(LLM)의 정책 경사 학습에 두 가지 간단하지만 효과적인 기법을 제안한다. 첫째, 고정된 앵커 정책을 대신해 EMA(Exponential Moving Average) 기반의 타깃 네트워크를 사용해 학습 안정성을 확보한다. 둘째, 토큰‑레벨 KL을 정확히 계산하면서도 메모리와 계산 비용을 절감하는 Top‑k KL 추정기를 도입한다. 이론적으로 EMA 앵커의 안정성 조건을 유도하고, Top‑k KL이 모든 k에서 편향이 없고 그래디언트도 정확함을 증명한다. GRPO와 결합한 EMA‑PG는 수학 추론(OlympiadBench)과 검색 기반 QA(HotpotQA, 2WikiMultiHopQA 등)에서 기존 방법 대비 10‑30% 이상의 성능 향상을 달성한다.
상세 분석
이 연구는 LLM에 적용되는 정책 경사 강화학습에서 가장 핵심적인 두 요소, 즉 ‘앵커 정책’과 ‘KL 정규화’를 재검토한다. 기존 RLHF·GRPO 등에서는 고정된 사전학습 모델을 앵커로 삼아 KL 발산을 제한했지만, 파라미터가 급격히 변하면 KL 값이 급증해 학습이 불안정해진다. 논문은 이를 해결하기 위해 EMA(지수 이동 평균) 기반의 앵커를 도입한다. EMA는 매 업데이트마다 현재 파라미터와 이전 EMA 파라미터를 가중 평균해, 시간에 따라 부드러운 ‘타깃’ 정책을 제공한다. 저자는 파라미터 차이 δₜ=θₜ−θₑₘₐₜ에 대한 동역학을 Fisher 정보 행렬 F와 학습률 α, KL 계수 β, EMA 감쇠 η를 이용해 선형 근사하고, 고유값 λₘₐₓ에 대한 안정성 조건 αβλₘₐₓ < 1+η 를 도출한다. 이 식은 EMA 감쇠가 충분히 크면(η≈0.9) 큰 학습률·KL 계수 조합에서도 안정적으로 수렴함을 보인다.
두 번째 기여는 토큰‑레벨 KL 추정기의 메모리·편향 문제를 해결한 Top‑k KL이다. LLM의 어휘 크기가 수십만에 달하므로 전체 로그잇을 저장해 정확 KL을 계산하면 O(|V|) 메모리가 필요하다. 기존 샘플링 KL(K1‑K3)은 메모리는 적지만 편향된 그래디언트를 만든다. 저자는 상위 k개의 로그잇을 정확히 사용하고, 나머지는 샘플링 KL로 보정하는 방식으로, ‘c KL_trun’(상위 k에 대한 정확 KL)과 ‘c KL_sampled’(하위에 대한 샘플링 KL)를 결합한다. 수학적으로는 E
댓글 및 학술 토론
Loading comments...
의견 남기기