멀티모달 대형 언어 모델의 도메인 지식 강화 학습
초록
본 논문은 멀티모달 대형 언어 모델(MLLM)에 전문 분야(원격 탐사·의료 영상) 지식을 텍스트 프롬프트만으로 주입해도 성능 향상이 거의 없음을 확인하고, 도메인 지식을 최적화 단계에서 직접 반영하는 강화학습 파인튜닝 프레임워크를 제안한다. 도메인 변환 기반 샘플링 분포와 KL·JS 발산을 이용한 제약·보상 설계로 정책을 조정하고, 광범위한 실험에서 기존 방법을 크게 능가하는 결과를 얻었다.
상세 분석
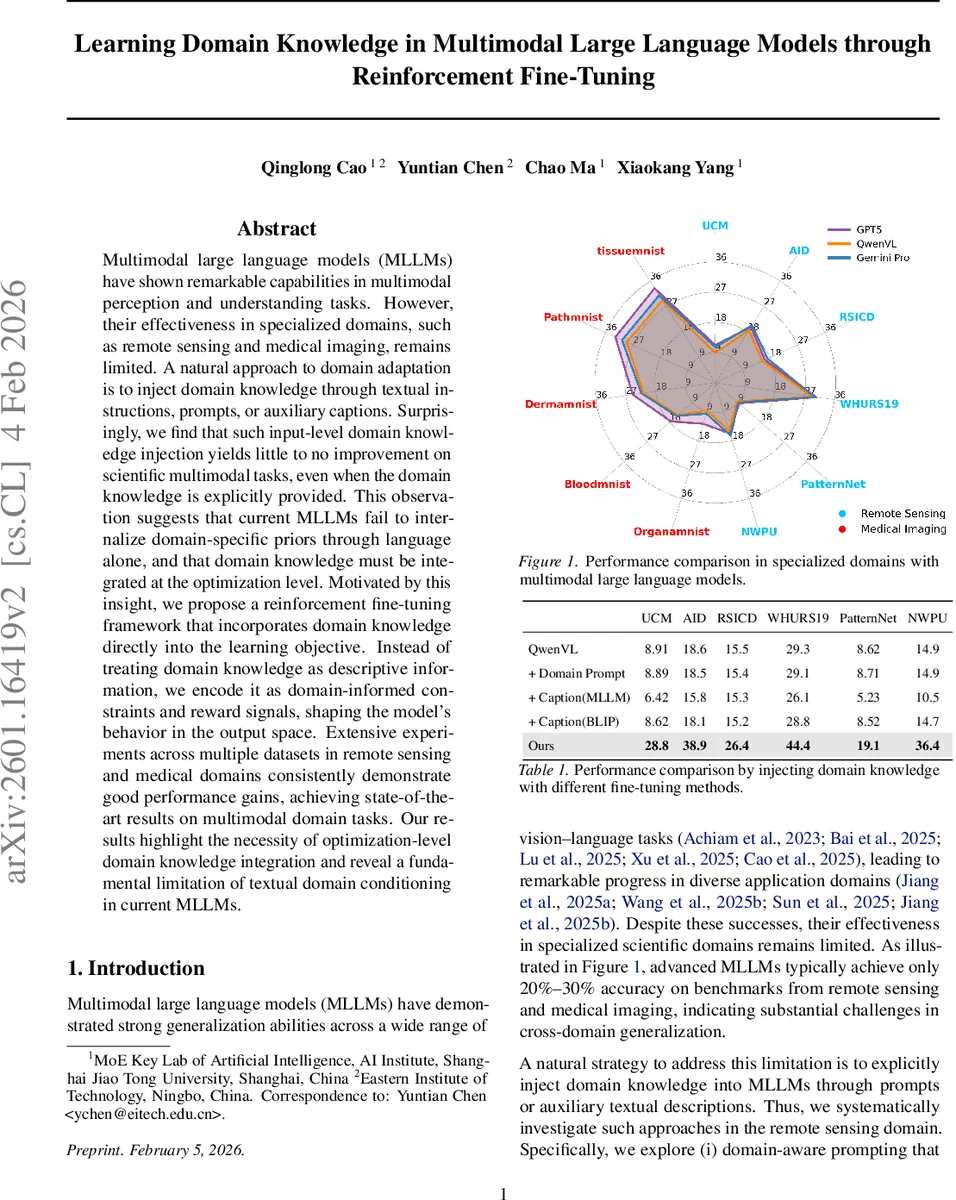
이 연구는 현재 MLLM이 텍스트 기반 도메인 프롬프트나 캡션을 통해 추상적인 분야 지식을 내재화하지 못한다는 근본적인 한계를 실험적으로 입증한다. 원격 탐사와 의료 영상 데이터셋에서 “Domain Prompt”, “Caption(MLLM)”, “Caption(BLIP)” 등 다양한 입력 수준의 지식 주입 방식을 적용했음에도 불구하고 정확도 향상이 미미하거나 오히려 감소하는 현상이 관찰되었다. 이는 MLLM이 대규모 일반 이미지‑텍스트 코퍼스로 사전학습된 후, 고차원 도메인 개념(예: 회전 불변성, 대칭성)을 언어 수준에서 직접 매핑하기 어렵다는 점을 시사한다.
이에 저자들은 도메인 지식을 “제약”과 “보상”이라는 형태로 강화학습 목표에 직접 삽입하는 방법을 설계했다. 기본 강화학습 엔진으로는 그룹 상대 정책 최적화(GRPO)를 채택했으며, 이는 기존 PPO 대비 가치 함수 추정 없이 그룹 내 상대 이득을 활용해 샘플 효율성과 안정성을 높인다. 도메인‑지원 샘플링 분포 π_D^θ는 원본 입력에 도메인‑특정 변환(원격 탐사의 임의 회전, 의료 영상의 좌우·상하 대칭 등)을 적용해 생성한다. 이후 원본 정책 분포 π^θ와 π_D^θ 사이의 KL 발산을 최소화하는 도메인 손실 L_dom을 추가함으로써, 모델이 변환 후에도 일관된 출력을 생성하도록 강제한다.
보상 측면에서는 각 샘플의 도메인 일치 정도를 JS 발산 D_i = D_JS(π_D^θ‖π^θ) 로 측정하고, 이를 1−D_i 로 가중한 이득 A_d_i = (1−D_i)·A_i 를 기존 GRPO 이득에 곱한다. 이렇게 하면 도메인 원칙에 부합하는 샘플이 학습 과정에서 더 큰 영향을 미치게 된다. 최종 목표 함수는 정책 이득, KL 정규화(π^θ‖π_ref), 도메인 손실을 모두 포함한다.
실험에서는 6개의 원격 탐사 벤치마크(UCM, AID, RSICD, WHURS19, PatternNet, NWPU)와 MedMNIST v2의 3개 의료 데이터셋(OrganMNIST, BloodMNIST, PathMNIST)을 사용해 few‑shot 설정을 평가했다. 제안 방법은 기존 SFT, 프롬프트 기반, 캡션 기반 방법을 모두 앞서며, 특히 회전 불변성·대칭성 같은 구조적 도메인 제약을 명시적으로 반영했을 때 성능 격차가 크게 나타났다. 결과는 평균 정확도, F1 점수, AUC 등 여러 지표에서 5~15%p 상승을 기록했으며, 최신 MLLM(Qwen‑VL, GPT‑4V 등) 대비 도메인 특화 작업에서 새로운 최첨단(state‑of‑the‑art) 수준을 달성했다.
이 논문의 핵심 기여는 (1) 텍스트 수준의 도메인 주입이 실질적인 성능 개선을 보장하지 않음을 실증, (2) 도메인 지식을 최적화 레벨에서 제약·보상 형태로 통합하는 강화학습 프레임워크를 제안, (3) 변환 기반 도메인‑지원 분포와 발산 기반 가중치를 통해 추상적인 도메인 원칙을 효과적으로 학습, (4) 다양한 과학·의료 데이터셋에서 일관된 성능 향상을 입증한 점이다. 향후 연구에서는 더 복잡한 도메인 규칙(예: 물리 법칙, 임상 가이드라인)과 멀티‑모달 피드백 루프를 결합해 강화학습 기반 도메인 적응을 확장할 가능성을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기