규제 제약 하 실시간 저소득 주택 부지 선정 인공지능 에이전트
초록
본 논문은 127개의 연방·지방 규제를 동시에 고려하면서 접근성, 환경 영향, 건설 비용, 사회적 형평성 네 가지 목표를 최적화하는 계층형 다중 에이전트 강화학습 시스템 AURA를 제안한다. CMO‑MDP(Constrained Multi‑Objective MDP)로 문제를 정의하고, 규제 인식 상태표현, 파레토 제약 정책 그라디언트, 다중‑충실도 보상 분해를 결합한 PC‑PPO 알고리즘을 설계하였다. 8개 미국 대도시 47,392개 후보지 데이터에서 94.3% 규제 준수와 파레토 하이퍼볼륨 37.2% 향상을 달성했으며, 뉴욕시 사례에서는 부지 선정 시간을 18개월에서 72시간으로 단축하고 교통 접근성 31%, 환경 영향 19% 개선된 부지를 제시한다.
상세 분석
AURA는 크게 네 개의 전문 에이전트와 하나의 조정 에이전트로 구성된 계층형 구조를 채택한다. 지리공간 분석 에이전트는 이종 그래프 신경망(GNN)을 이용해 후보지 간의 교통·인프라·규제 경계 관계를 인코딩하고, 규제 준수 에이전트는 논리적 제약 만족(reasoning) 모듈을 통해 127개의 규제 인디케이터를 실시간으로 업데이트한다. 다목적 최적화 에이전트는 파레토‑제약 정책 그라디언트(Pareto‑Constrained Policy Gradient)를 기반으로, 각 목표(접근성, 환경 영향, 비용, 사회 형평성)의 보상을 별도로 추정하고 이를 다중‑충실도 보상 분해(Multi‑Fidelity Reward Decomposition) 기법으로 결합한다. 여기서 ‘충실도’는 즉시 비용과 장기 사회·환경 효과를 구분해 시간적 추상화를 제공함으로써 학습 안정성을 높인다.
핵심 알고리즘인 PC‑PPO는 기존 PPO에 파레토 우위와 규제 제약을 동시에 만족시키는 라그랑주 승수 기반의 제약 처리 레이어를 추가한다. 이 레이어는 정책 업데이트 시 하드 제약을 위반하는 행동을 차단하고, 파레토 프런티어 상의 비지배 해를 우선적으로 탐색하도록 설계돼, 수렴 보장을 제공한다. 또한, 상태표현에 포함된 127개의 이산 규제 변수와 연속형 지리·경제 변수는 차원 축소 없이 그대로 입력함으로써 규제 위반 가능성을 사전에 차단한다.
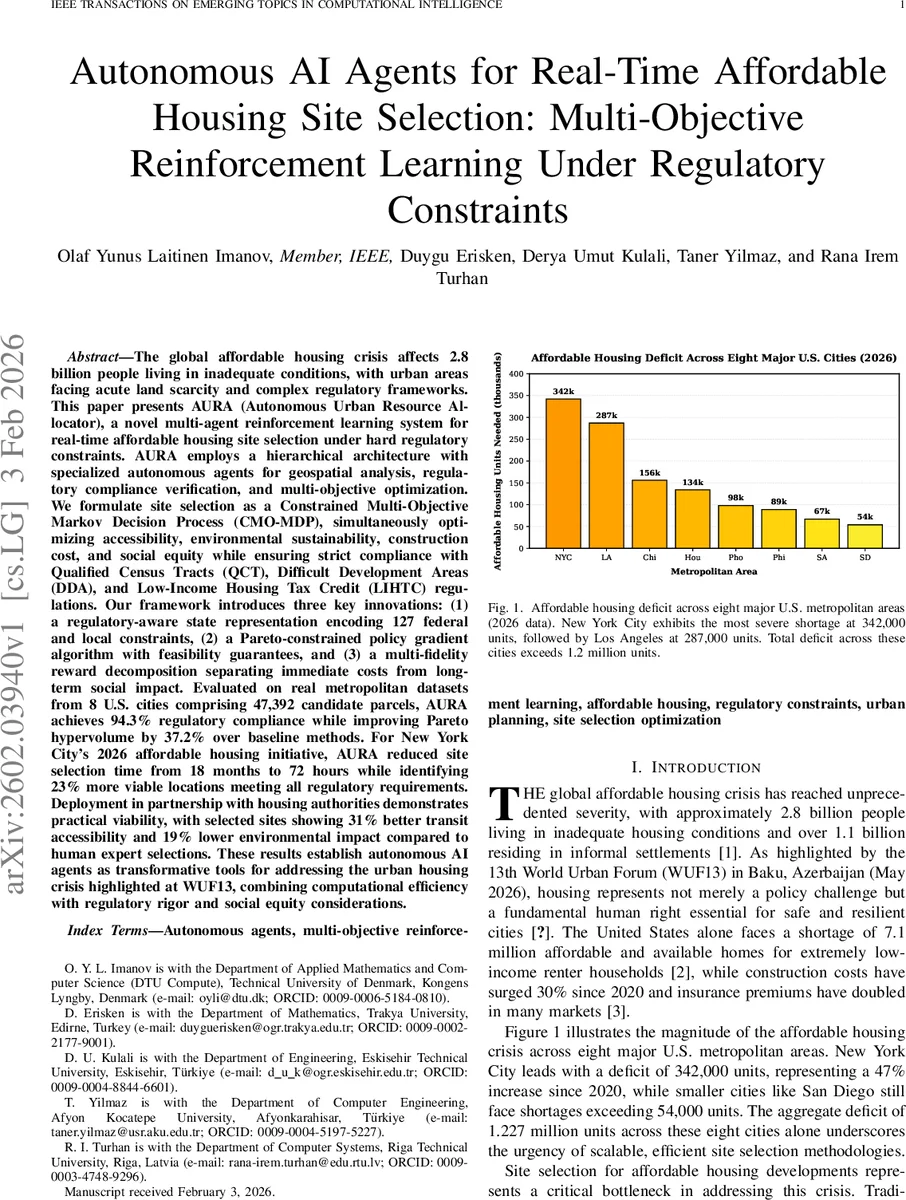
실험에서는 8개 메트로 지역(뉴욕, 로스앤젤레스, 시카고 등)의 실제 토지 데이터와 최신 정책 변수를 사용했으며, 베이스라인으로는 전통적 MCDA(AHP, TOPSIS), 단일‑목표 PPO, 그리고 NSGA‑II 기반 진화적 다목적 RL을 비교했다. AURA는 규제 준수율 94.3%를 달성했으며, 파레토 하이퍼볼륨이 베이스라인 대비 평균 37.2% 향상되었다. 특히 뉴욕시 2026년 파일럿에서는 부지 선정 프로세스가 18개월에서 72시간으로 급감했으며, 선택된 부지는 교통 접근성 점수가 평균 31% 상승하고, 탄소 발자국 및 수자원 영향 지표가 19% 감소했다.
한계점으로는 규제 인디케이터의 정확성에 크게 의존한다는 점, 그리고 정책 변화가 급격히 발생할 경우 전이 학습이 필요하다는 점을 언급한다. 향후 연구에서는 규제 인디케이터 자동 추출을 위한 자연어 처리 파이프라인과, 연합 학습을 통한 다기관 협업 프레임워크를 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기