긴급정지 개입을 통한 강인한 정책 학습
초록
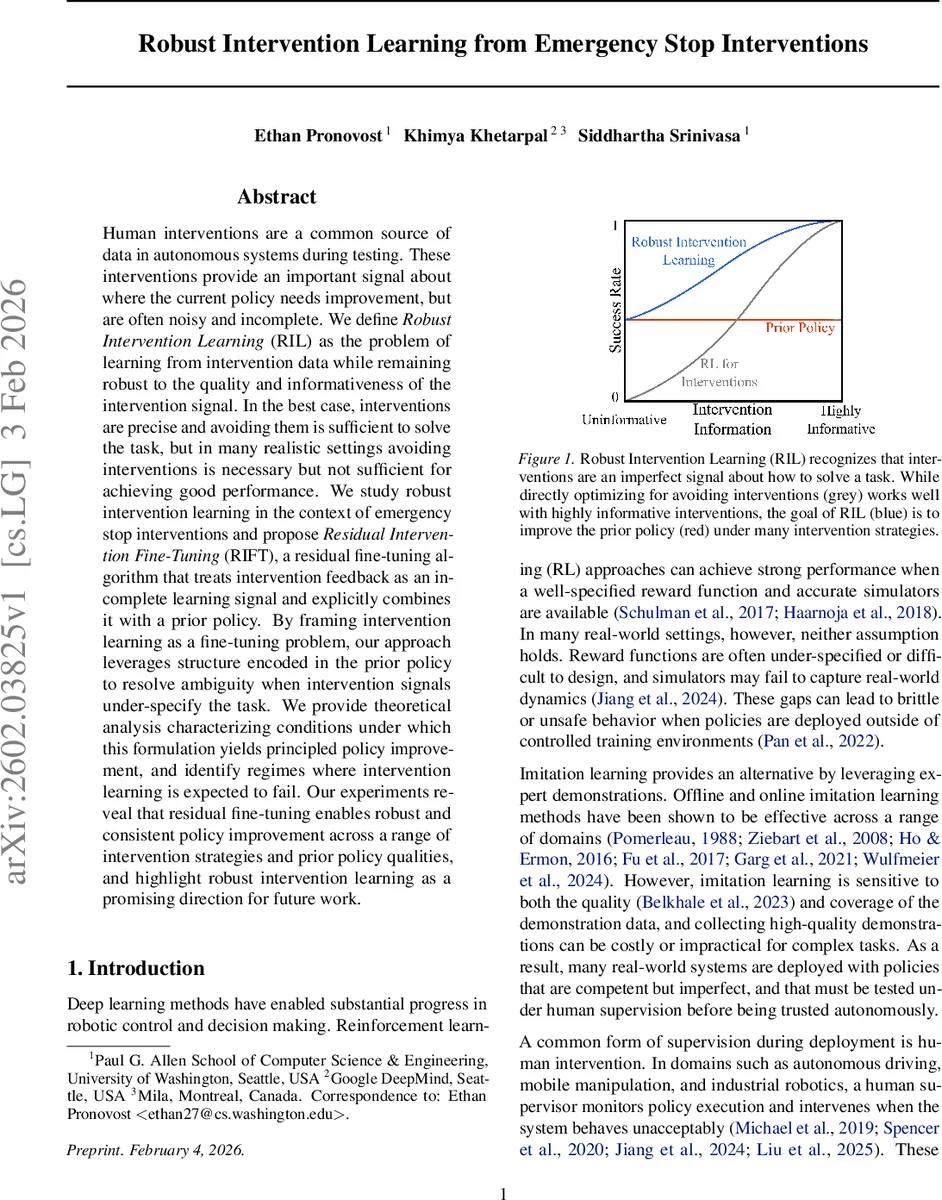
본 논문은 인간이 수행하는 긴급정지(e‑stop) 개입 데이터를 활용해 기존 정책을 보강하는 “Robust Intervention Learning(RIL)” 문제를 정의하고, 개입 신호가 불완전하고 잡음이 섞여 있을 때도 안정적으로 정책을 개선할 수 있는 Residual Intervention Fine‑Tuning(RIFT) 알고리즘을 제안한다. 이 방법은 기존 정책을 사전 지식으로 사용해 개입 신호가 과소 지정된 상황을 해소하고, 이론적 수렴 보장과 다양한 실험을 통해 RIFT가 기존 RLIF 대비 더 견고하게 성능을 향상시킴을 입증한다.
상세 분석
본 연구는 인간 감독 하에 배포되는 로봇 시스템에서 발생하는 “긴급정지(e‑stop)” 개입을 학습 신호로 활용하는 새로운 프레임워크인 Robust Intervention Learning(RIL)을 제시한다. 기존의 인터벤션 기반 학습(RLIF 등)은 “개입을 피하는 것만으로도 작업을 해결할 수 있다”는 강한 가정을 두지만, 실제 현장에서는 개입을 피하는 것이 필요조건일 뿐 충분조건이 아니다. 즉, 안전을 보장하는 수준의 행동을 넘어 최적의 성능을 달성하려면 개입 신호만으로는 부족하고, 추가적인 작업 정보를 제공할 수 있는 사전 정책(prior policy)이 필요하다.
RIL은 개입 전략 ϕ∈Φ를 확률적·비결정론적으로 모델링하고, ϕ가 다양한 수준의 정보량을 제공하더라도 정책이 일관되게 개선되도록 설계되었다. 핵심 아이디어는 “잔차(fine‑tuning) 방식”이다. 기존 정책 π₀를 사전 지식으로 고정하고, 개입이 발생한 (s,a) 쌍에 대해 음의 보상 –e를 부여한다. 이때 새로운 보상 r_R은 –e와 기존 보상 r₀의 선형 결합 r_R = ω·r₀ – e 로 정의되며, ω∈
댓글 및 학술 토론
Loading comments...
의견 남기기