데이터 혼합과 선택을 하나로: UniGeM의 기하학적 탐색과 채굴
초록
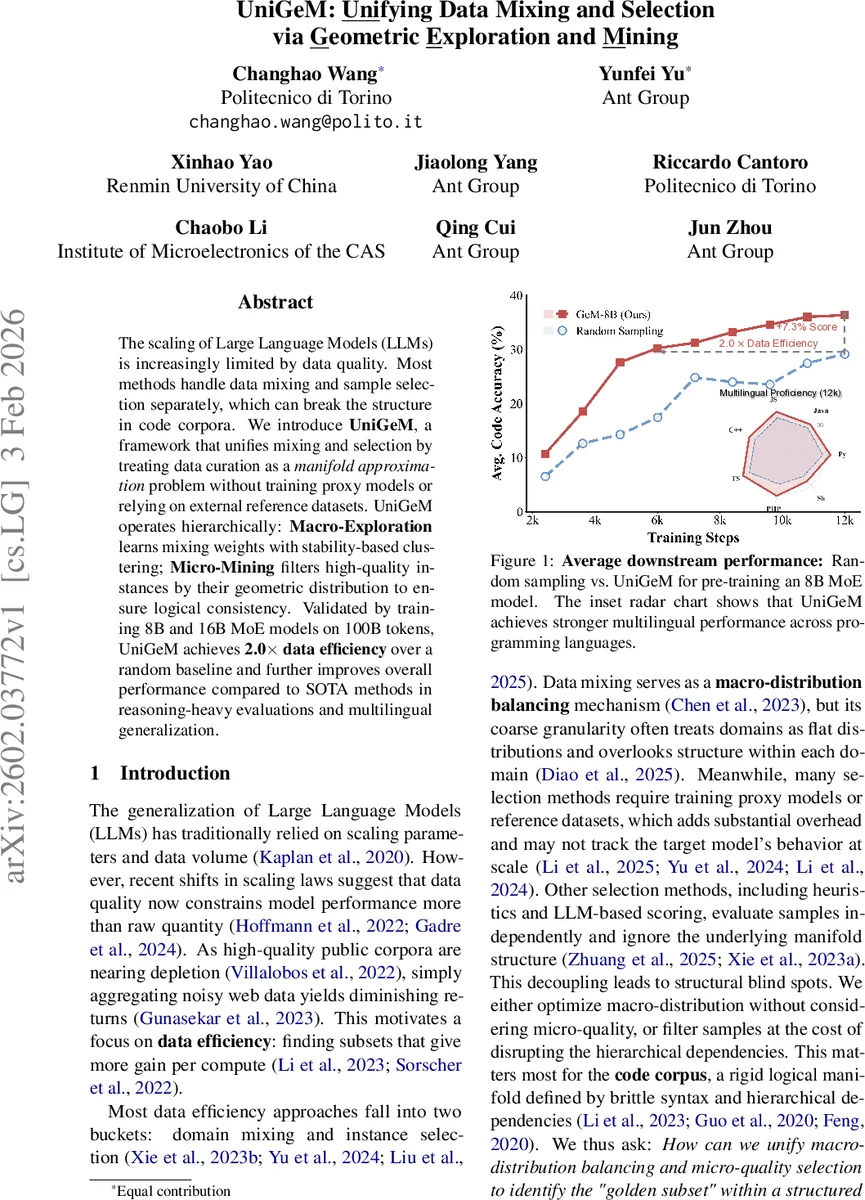
UniGeM은 데이터 혼합과 샘플 선택을 별도로 수행하던 기존 방식을 통합해, 데이터 커리케이션을 다양체 근사 문제로 정의한다. 매크로‑탐색 단계에서 안정성 기반 클러스터링으로 최적의 매크로 해상도와 가중치를 찾고, 마이크로‑채굴 단계에서 기하학적 분포와 구조적 일관성을 이용해 고품질 인스턴스를 선별한다. 100 B 토큰 규모의 코드‑텍스트 혼합 데이터를 8 B·16 B MoE 모델에 적용한 결과, 무작위 샘플링 대비 2배 데이터 효율을 달성했으며, 추론 성능과 다국어 일반화에서도 SOTA 방법들을 앞섰다.
상세 분석
UniGeM은 데이터 커리케이션을 두 단계의 계층적 최적화 문제로 전환한다. Stage‑I 매크로‑탐색에서는 전체 코퍼스를 임베딩 모델 fθ 로 고차원에서 정규화된 벡터 eᵢ 로 변환하고, 이를 잠재적 다양체 M 상에 투사한다. 각 클러스터 Cₖ 에 대해 ‘응집도’, ‘클러스터 크기’, ‘시퀀스 길이’, ‘엔트로피’ 등 네 가지 기하학적 특성을 zₖ 에 정량화하고, 스펙트럼 합의(weight w) 를 통해 정규화된 선형 결합 sₖ 를 산출한다. 이때 부정적 요인(길이·엔트로피·크기)은 가중치가 음수인 형태로 차감된다.
다음으로 크로스‑해상도 소프트 정렬을 이용해 다양한 K값에 대해 클러스터 중심 간 코사인 유사도를 기반으로 전이 행렬 πₖ→ₖ′ 을 만든 뒤, 재구성된 점수 ŝₖ 와 원점수 sₖ 의 켄달τ 상관계수 J_stab(K) 를 계산한다. 가장 높은 안정성을 보이는 K*가 최적 매크로 해상도로 선택되며, 소프트맥스 rₖ = exp(sₖ)/∑exp(sⱼ) 를 통해 각 클러스터에 할당될 샘플링 예산을 결정한다.
Stage‑II 마이크로‑채굴에서는 각 Cₖ를 다시 세부 서브클러스터 Sⱼ 로 분할한다. 서브클러스터마다 작은 프루프 집합을 추출해 LLM (knowledge probe) 으로 의미 점수 P_{Sⱼ} 를 얻고, 구조적 일관성을 보장하기 위해 정규화된 마할라노비스 거리 기반 L_struct 를 정의한다. 또한, 응집도 차이를 시그모이드 함수 β_{Sⱼ}=σ(z_{Sⱼ}^{coh}−z_{Cₖ}^{coh}) 로 변환해 기하학적 응집 게이트를 적용한다. 최종 샘플링 가중치 W(Sⱼ) 는 전역 예산 rₖ, 의미 점수, 구조적 페널티, 응집 게이트를 곱한 형태로 계산되어, 전역‑국부 토폴로지를 동시에 보존한다.
이론적 분석에서는 선택된 서브셋 S 의 와서스테인스톤‑2 거리 E(S) 를 상한으로 제시하고, Stage‑I의 양자화 오차와 Stage‑II의 프루닝 이득 Δ(k)_gain 을 분리해 E(S) ≤ 2C_d K^{−2/d}+2∑α_k(σ_k²−Δ(k)_gain) 이라는 경계식을 도출한다. 이는 클러스터 내 분산을 감소시키는 마이크로‑프루닝이 전체 근사 오차를 크게 줄일 수 있음을 수학적으로 뒷받침한다.
실험에서는 100 B 토큰 규모의 코드‑텍스트 혼합 코퍼스를 7:3 비율로 구성하고, Qwen‑3 임베딩을 이용해 20 % 샘플을 대표 집합으로 삼아 K* = 72 개의 매크로 클러스터를 찾았다. 이후 각 클러스터를 서브클러스터링하고, UniGeM‑8B·16B MoE 모델을 동일 학습 레시피로 1 epoch 훈련했다. 결과는 무작위 샘플링 대비 2.0× 데이터 효율을 달성했으며, HE, MBPP, LiveCode, CruxEval 등 다양한 코드·다국어 벤치마크에서 평균 +7.3 % 이상의 성능 향상을 기록했다.
비교 대상인 Meta‑rater와 CLIMB은 각각 인스턴스‑레벨 LLM 스코어링, 도메인‑레벨 가중치 최적화를 사용했지만, UniGeM은 매크로‑마이크로 구조를 동시에 고려함으로써 특히 코드와 같이 논리적 종속성이 강한 데이터에서 더 큰 이득을 보였다. Ablation 실험에서는 (1) 단일 평면 클러스터링, (2) 마이크로‑채굴만 적용, (3) 매크로 가중치를 균등하게 할당하는 경우 모두 성능이 크게 감소함을 확인했다. 이는 계층적 설계와 두 단계의 상호 보완성이 핵심임을 시사한다.
한계점으로는 임베딩 모델 fθ 의 품질에 크게 의존한다는 점, 그리고 대규모 클러스터링·프루닝 과정에서의 계산·메모리 비용이 여전히 존재한다는 점을 들 수 있다. 향후 연구에서는 경량화된 임베딩, 온라인 클러스터링, 그리고 멀티모달(텍스트·코드·이미지) 다양체 확장을 통해 UniGeM의 적용 범위를 넓히는 방향이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기