DiscoverLLM 의도 실행에서 의도 발견까지
초록
DiscoverLLM은 사용자가 아직 명확히 정의하지 못한 의도를 탐색·발견하도록 돕는 프레임워크이다. 계층형 의도 트리를 갖는 사용자 시뮬레이터를 구축하고, 모델이 제시한 옵션이 의도 구체화에 기여하면 보상을 부여한다. 이를 통해 LLM은 모호한 초기 요청에 대해 탐색적 대화를 진행하고, 의도가 구체화되면 수렴해 최종 결과물을 제공한다. 창의적 글쓰기·기술 문서·SVG 그림 등 3가지 베이스라인에서 기존 방법 대비 10% 이상 성능 향상과 대화 길이 30%‑40% 감소를 달성했으며, 75명의 인간 사용자 실험에서도 만족도와 효율성이 크게 개선되었다.
상세 분석
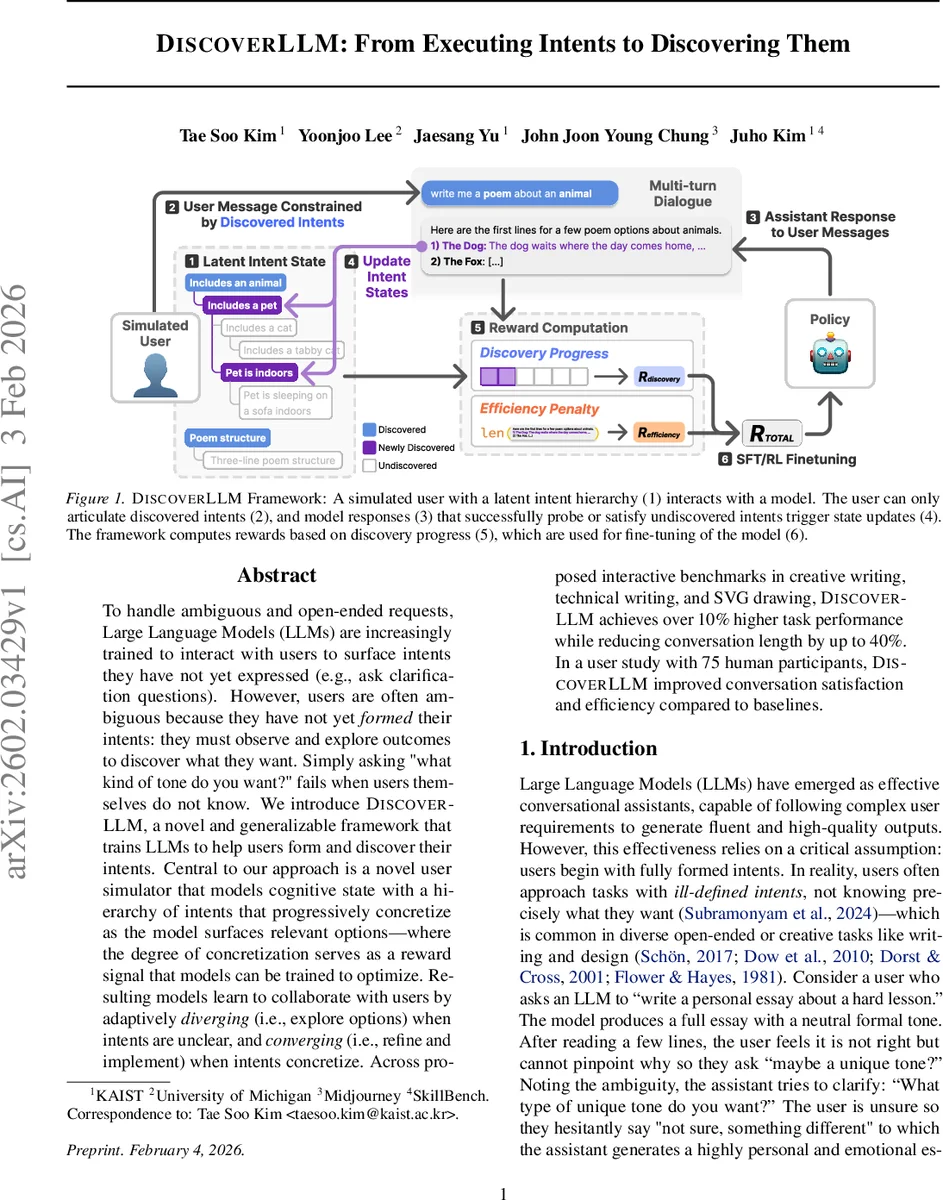
본 논문은 “의도 실행”을 전제로 하는 기존 LLM 인터랙션 연구와 달리, 사용자가 초기 단계에서 의도를 완전히 형성하지 못한다는 가정을 명시적으로 모델링한다. 이를 위해 저자들은 ‘잠재 의도 계층(Intents Hierarchy)’이라는 개념을 도입했으며, 각 노드는 추상적인 요구사항에서 점차 구체적인 세부 요구사항으로 전이한다. 시뮬레이터는 사용자가 현재까지 발견한 노드 집합 Iₜ와, 아직 발견되지 않은 자식 노드 집합 R(Iₜ)를 유지한다. 모델의 응답 rₜ가 R(Iₜ) 안의 어떤 노드와 직접(질문·제시) 혹은 간접(관련 옵션 제공)으로 연관될 경우, 해당 노드의 상태가 ‘미발견→발현→발견’으로 전이하고, 이는 보상 함수에 반영된다. 보상은 두 축으로 구성된다. 첫 번째는 ‘의도 발견 보상’으로, 새로운 구체적 의도를 얼마나 많이 끌어냈는가를 측정한다. 두 번째는 ‘의도 만족 보상’으로, 최종 대화 단계에서 I_T에 포함된 모든 의도를 충족하는 출력물의 품질을 평가한다. 이러한 다중 목표 보상은 강화학습(RLHF)과 지도학습(SFT)을 결합한 파인튜닝 파이프라인에 적용되어, 모델이 탐색(다양한 옵션 제시)과 수렴(구체적 요구 반영) 사이의 균형을 스스로 학습하도록 만든다. 실험에서는 Llama‑3.1‑8B‑Instruct와 Qwen‑3‑8B 두 모델에 동일 프레임워크를 적용했으며, 창의적 글쓰기(시·소설), 기술 문서(매뉴얼), SVG 그래픽(아이콘 디자인) 세 도메인에서 기존 ‘명시적 의도’ 기반 챗봇, 그리고 최신 멀티턴 프롬프트 기법과 비교했다. 결과는 평균 10% 이상의 성공률 향상, 대화 턴 수 32% 감소, 그리고 인간 평가자들이 매긴 ‘인터랙티브 점수’ 83% 상승으로 나타났다. 추가로 75명의 크라우드워커를 대상으로 한 사용자 연구에서는, DiscoverLLM을 사용한 그룹이 평균 작업 시간 22% 단축, 만족도 1.4점(5점 척도) 상승을 기록했다. 논문은 또한 의도 계층이 단조 증가(monotonic)라는 가정, 사용자가 ‘잠재 의도’를 이미 내재하고 있다는 전제, 그리고 시뮬레이터가 실제 인간의 복잡한 사고 과정을 완벽히 재현하지 못한다는 한계를 솔직히 인정한다. 향후 연구 방향으로는 비단계적(비계층적) 의도 형성, 의도 포기·전환 메커니즘, 그리고 도메인 외 일반화 능력 강화를 제시한다. 전반적으로 이 논문은 LLM이 단순히 사용자의 명시적 요구를 실행하는 수준을 넘어, 사용자가 스스로 원하는 바를 발견하도록 돕는 ‘협업적 탐색 파트너’ 역할을 수행하도록 설계·학습시키는 방법론을 제시한다는 점에서 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기