시각 언어 사슬 압축으로 환각을 억제하는 C3PO
초록
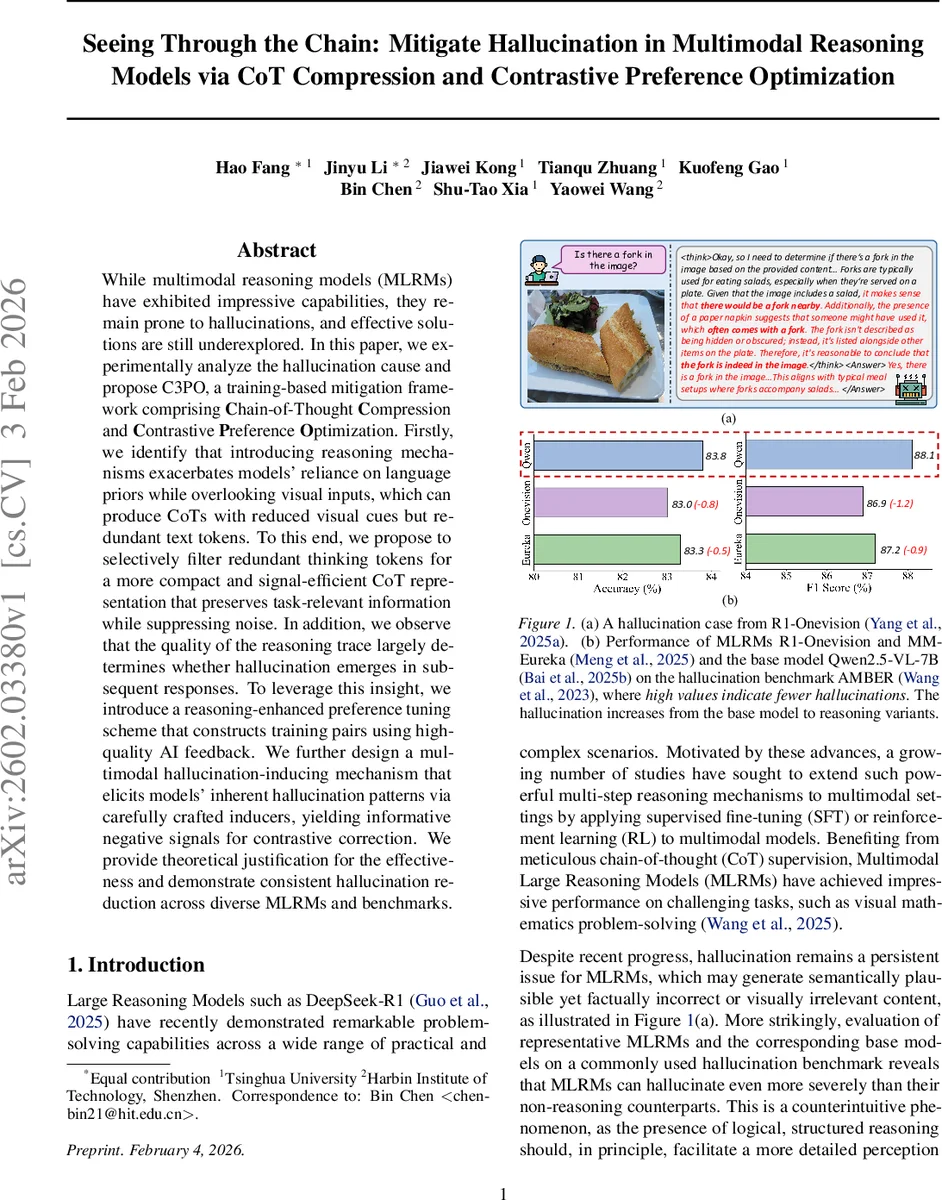
본 논문은 멀티모달 추론 모델이 사유 과정에서 시각 정보를 소홀히 하여 발생하는 환각 문제를 분석하고, 체인‑오브‑생각(Chain‑of‑Thought) 압축과 대비 선호 최적화(Contrastive Preference Optimization)를 결합한 C3PO 프레임워크를 제안한다. 시각‑언어 토큰의 중요도 기반 토큰 프루닝으로 CoT를 압축하고, 고품질 AI 피드백을 활용한 긍정 샘플과 의도적으로 유도한 환각 샘플을 대비 학습함으로써 다양한 멀티모달 모델과 벤치마크에서 환각률을 크게 낮추었다.
상세 분석
C3PO는 두 단계로 구성된 훈련 기반 환각 완화 전략이다. 첫 번째 단계인 CoT Compression은 정보 병목(Information Bottleneck) 관점에서 사유 체인을 시각 입력과 최종 답변 사이의 중간 표현으로 보고, 시각적 신호를 보존하면서 불필요한 텍스트 토큰을 제거한다. 이를 위해 저자들은 LLMlingua‑2라는 사전 학습된 토큰 중요도 모델을 이용해 각 토큰의 시각·언어 기여도를 점수화하고, 상위 γ 백분위수만을 남겨 압축된 사유 체인 z′를 만든다. 실험 결과, 압축된 CoT만으로도 기존 전체 CoT 대비 시각 토큰에 대한 어텐션 비율이 상승하고, 불필요한 언어 편향이 감소함을 확인했다.
두 번째 단계인 Contrastive Preference Optimization은 고품질 CoT와 의도적으로 환각을 유도한 부정 샘플을 대비 학습한다. 긍정 샘플은 Qwen‑3‑VL 같은 강력한 멀티모달 LLM에게 ‘문장 수준 환각 탐지·수정’ 프롬프트를 제공해 원본 모델의 사유 체인을 교정받은 결과이며, 부정 샘플은 (1) 이미지에 랜덤 마스크를 적용해 시각 정보를 약화시키고 언어 선입견에 의존하도록 만든 시각 환각, (2) “시각 정보를 무시하고 가능한 답을 만들어라”는 지시문을 삽입해 텍스트 환각을 유도한 인스트럭션 방식으로 생성된다. 이렇게 구성된 선호 데이터셋 Dₚ를 이용해 Direct Preference Optimization(DPO) 손실을 최소화함으로써 모델은 ‘고품질 사유 → 정답’ 경로를 강화하고, ‘환각 사유 → 오류 답변’ 경로를 억제한다.
이론적으로는 압축된 CoT가 정보 병목을 최소화해 시각 신호 전송 효율을 높이고, 대비 학습이 모델의 손실 함수에 환각 비용을 명시적으로 부여함으로써 최적화 과정에서 환각을 비용 높은 행동으로 만든다. 실험에서는 DeepSeek‑R1, R1‑OneVision, MM‑Eureka 등 다양한 최신 MLRM에 C3PO를 적용했으며, AMBER, CHAIR 등 표준 환각 벤치마크에서 평균 7~12%p의 환각 감소와 동시에 답변 정확도는 유지되거나 소폭 향상되었다. 특히, CoT 압축만으로도 기존 SFT 대비 4%p 정도의 환각 감소를 달성했으며, 대비 선호 최적화와 결합했을 때 최종 감소율이 최고 15%p에 이른다.
요약하면, C3PO는 (1) 시각‑언어 어텐션 불균형을 정량적으로 진단하고, (2) 토큰 중요도 기반 압축으로 시각 신호를 강화하며, (3) 고품질·저품질 사유 체인을 대비 학습해 모델이 스스로 환각을 인식·수정하도록 만든다. 이는 멀티모달 추론 모델이 복잡한 사유 과정을 거치면서도 시각 근거를 놓치지 않도록 하는 실용적이면서도 이론적으로 설득력 있는 해결책이다.
댓글 및 학술 토론
Loading comments...
의견 남기기