RL 기반 중간 학습으로 LLM 순환 진화
초록
본 논문은 사후 학습(RL) 단계에서 얻은 추론 프라이어를 사전 학습 중간 단계에 재활용하여 토큰 가중치를 동적으로 조정하는 ReMiT 프레임워크를 제안한다. 중간 학습 시 고품질 코퍼스를 이용해 토큰 손실 차이를 기반으로 가중치를 부여함으로써, 사전 학습 모델의 능력을 향상시키고 이후 RL 단계에서의 성능 향상을 지속한다. 실험 결과 10개 벤치마크에서 평균 3%·2%의 성능 개선을 확인하였다.
상세 분석
ReMiT은 기존 LLM 학습 파이프라인을 일방향에서 양방향으로 전환하는 혁신적 접근이다. 핵심 아이디어는 RL‑튜닝된 모델을 “참조 모델”로 활용해, 중간 학습(mid‑training) 단계에서 토큰 수준의 손실 차이 ΔL(xₜ)=−log pθ(xₜ|x<ₜ)+log pRL(xₜ|x<ₜ)를 계산하고, 이를 중심화(μΔ)한 뒤 시그모이드 함수를 통해 가중치 wₜ=clip(2·σ(bΔL), 1−ε, 1+ε)로 변환한다. 여기서 bΔL는 중심화된 손실 차이며, ε는 안정성을 위한 클리핑 하이퍼파라미터다. 이 가중치는 토큰별 그래디언트를 확대하거나 축소함으로써, RL 모델이 높은 신뢰도를 보이는 “핵심 토큰”에 더 큰 학습 신호를 전달한다.
수식적으로 ReMiT의 목표는 가중치가 적용된 음의 로그우도 L_ReMiT(θ)=−∑ₜ wₜ·log pθ(xₜ|x<ₜ) 를 최소화하는 것이며, 이는 암묵적인 목표 분포 q_w(xₜ|x<ₜ)∝p_data(xₜ|x<ₜ)·wₜ와 모델 분포 π_θ 사이의 KL 발산을 최소화하는 것과 동등함을 논문 부록에서 증명한다. 따라서 ReMiT 업데이트는 모델을 RL‑참조가 암시하는 “향상된 데이터 분포” 쪽으로 점진적으로 이동시킨다.
중간 학습 단계는 고품질 수학·코드·과학 텍스트를 빠르게 학습률을 감소시키며 진행하는데, 이 시점에서 모델은 고차원 추론 능력을 급격히 획득한다. 논문은 사전 학습과 사후 학습 사이의 토큰‑레벨 분포 차이를 시각화해, 중간 학습 전후에 RL 모델과의 로그 확률 격차가 크게 감소함을 보여준다. 이는 중간 학습이 모델의 확률 분포를 RL 모델에 가깝게 변형시키는 결정적 전환점임을 의미한다.
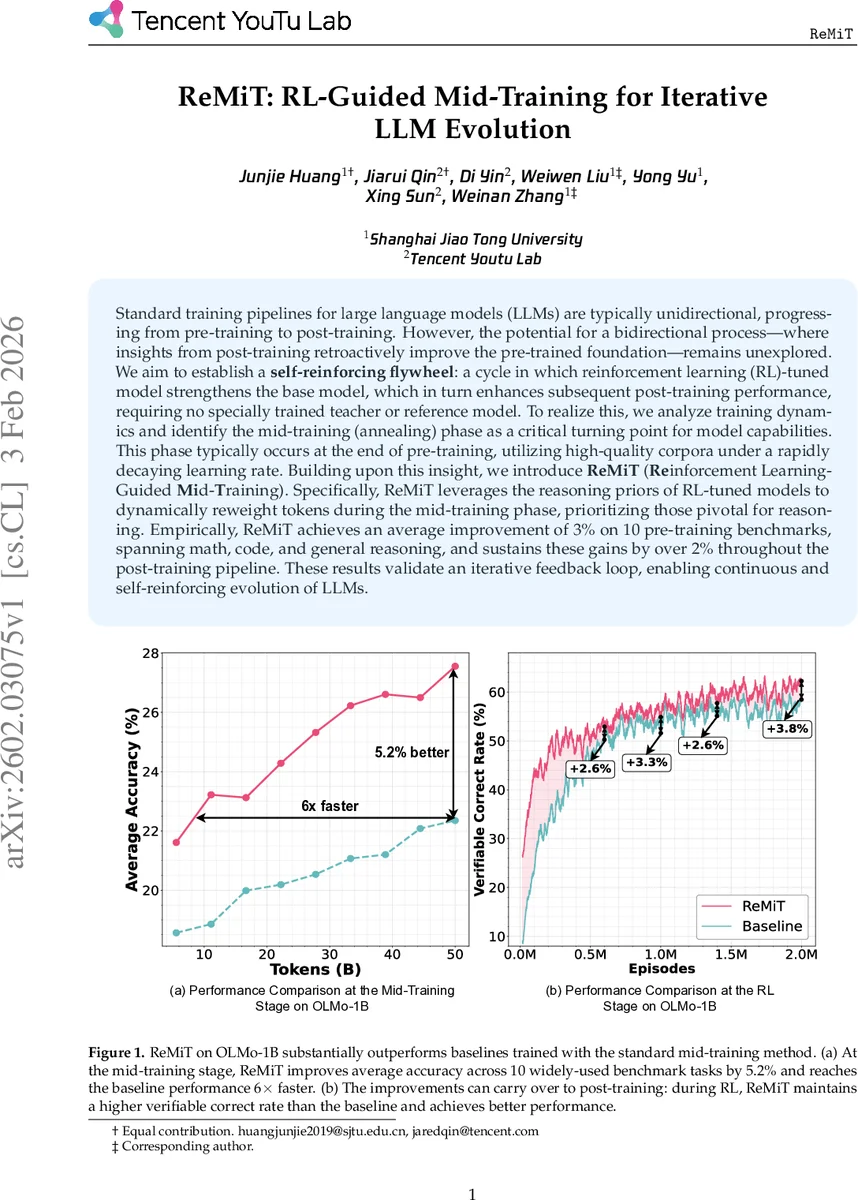
ReMiT은 외부 교사 모델을 필요로 하지 않는다. 기존 방법들은 문서‑레벨 혹은 샘플‑레벨 가중치를 적용해 데이터 품질을 향상시키지만, 토큰‑레벨의 미세 조정은 거의 다루지 않았다. ReMiT은 RL 모델이 제공하는 미세한 토큰‑레벨 신호를 직접 활용함으로써, 기존의 균일 가중치 손실 함수보다 효율적으로 추론에 핵심적인 토큰을 학습한다. 실험에서는 OLMo‑1B 모델에 적용했을 때, 중간 학습 단계에서 평균 정확도가 5.2% 상승하고, 학습 속도는 6배 가속화되었으며, 이후 RL 단계에서도 검증 정확도가 지속적으로 우위에 있었다.
이러한 결과는 “플라이휠 효과”를 실증한다. 강화학습 단계에서 얻은 추론 프라이어가 중간 학습에 피드백되어 베이스 모델을 강화하고, 강화된 베이스 모델은 다시 더 나은 RL 단계 성능을 가능하게 한다. 따라서 ReMiT은 LLM 개발 파이프라인을 순환형으로 전환시켜, 지속적인 성능 향상을 도모한다.
댓글 및 학술 토론
Loading comments...
의견 남기기