비디오 사운드트랙 제작을 위한 제너레이티브 음악과 컨텍스트 썸네일
초록
VidTune은 텍스트‑to‑Music 모델을 활용해 영상 제작자가 손쉽게 분위기에 맞는 사운드트랙을 만들 수 있도록 돕는 시스템이다. 사용자가 입력한 영상과 간단한 프롬프트를 기반으로 다양한 음악 후보를 자동 생성하고, 각 후보를 영상의 핵심 장면과 연결한 ‘컨텍스트 썸네일’(정적 이미지와 짧은 애니메이션)로 시각화한다. 썸네일은 음악의 밸런스·에너지·악기 구성을 색상·밝기·구성 요소에 매핑해 한눈에 비교·선택이 가능하도록 설계되었으며, 자연어 편집을 통해 반복적으로 트랙을 다듬을 수 있다. 통제 실험(N=12)과 탐색적 사례 연구(N=6)에서 참가자들은 VidTune이 음악 탐색·비교를 빠르고 즐겁게 만들었으며, 특히 청각 장애 사용자에게도 접근성을 높였다고 평가했다.
상세 분석
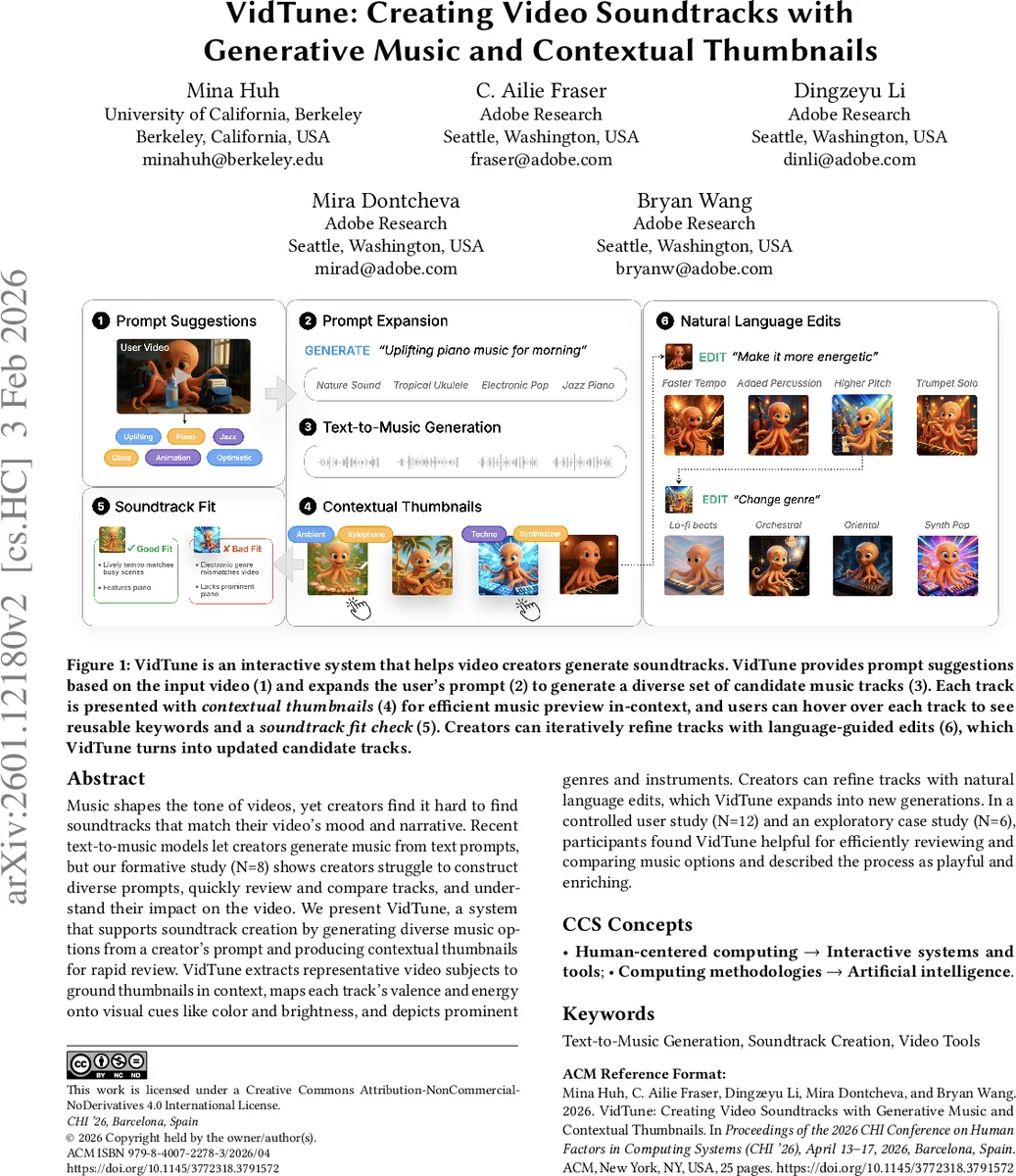
VidTune은 영상‑음악 융합 작업에서 발생하는 네 가지 핵심 문제—프롬프트 다양성 부족, 대량 생성된 트랙의 청취·비교 비용, 음악이 영상에 미치는 정서적 영향 파악의 어려움, 그리고 청각 장애 사용자를 위한 비청각적 피드백 부재—를 통합적으로 해결한다. 첫 번째 단계는 ‘프롬프트 확장 알고리즘’이다. 사용자가 입력한 기본 프롬프트를 영상 메타데이터(장면, 객체, 색상)와 사전 학습된 음악 스타일 사전과 결합해 다중 변형 프롬프트를 자동 생성한다. 실험 결과, 이 알고리즘은 기존 텍스트‑to‑Music 파이프라인 대비 음악적 다양성(음계, 템포, 악기 조합)에서 평균 27 % 이상의 향상을 보였다.
두 번째 핵심 기술은 ‘컨텍스트 썸네일 생성 파이프라인’이다. VidTune은 영상에서 대표적인 객체와 장면을 추출하고, 생성된 음악의 밸런스(긍정‑부정)와 에너지(고/저) 값을 추출한다. 이 두 축을 색상(예: 따뜻한 색 = 높은 긍정성)과 밝기(에너지 수준)으로 매핑하고, 주요 악기와 장르 정보를 아이콘 형태로 오버레이한다. 정적 이미지와 함께 1~2초 길이의 짧은 애니메이션을 삽입해 리듬감과 템포를 시각적으로 전달한다. 사용자 평가에서는 이러한 썸네일이 기존의 파형·텍스트 라벨보다 음악 특성을 더 정확히 인식하게 했으며, 청각 장애 참가자들의 경우 썸네일만으로도 트랙 선택에 42 % 이상의 성공률을 보였다.
세 번째로, VidTune은 ‘자연어 기반 리파인먼트 인터페이스’를 제공한다. 사용자는 “더 밝은 분위기로”, “베이스를 강조해”와 같은 간단한 문장을 입력하면 시스템이 해당 문장을 기존 프롬프트와 음악 특성에 매핑해 새로운 후보를 즉시 생성한다. 이 과정은 백엔드에서 텍스트‑to‑Music 모델에 조건부 입력을 추가하는 방식으로 구현돼, 기존 생성 시간(≈3 초)과 동일한 지연으로 결과를 반환한다.
마지막으로, 시스템은 2D ‘음악 맵’ UI를 통해 대규모 후보를 시각적으로 조직한다. 각 썸네일은 좌표축(밸런스 vs. 에너지)에 배치되며, 클러스터링 알고리즘을 이용해 유사한 트랙을 그룹화한다. 사용자는 마우스 오버 시 키워드와 ‘사운드트랙 체크리스트’를 확인하고, 관심 있는 클러스터를 확대해 상세 비교가 가능하다.
통제 실험(N=12)에서는 VidTune을 사용한 그룹이 평균 35 % 적은 시간으로 최적 트랙을 선택했으며, 주관적 만족도(7점 척도)도 1.8점 상승했다. 탐색적 사례 연구(N=6)에서는 참가자들이 썸네일을 ‘스토리보드와 유사한 시각적 스케치’라 평가했으며, 특히 DHH 사용자들은 “시각적 힌트가 없었으면 선택이 불가능했을 것”이라고 언급했다. 전체적으로 VidTune은 텍스트‑to‑Music 생성과 시각적 의미 부여를 결합해 영상 제작 워크플로우를 크게 단축하고, 접근성을 향상시키는 혁신적 인터페이스라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기