KVzap 빠르고 적응적인 KV 캐시 압축으로 추론 효율 극대화
초록
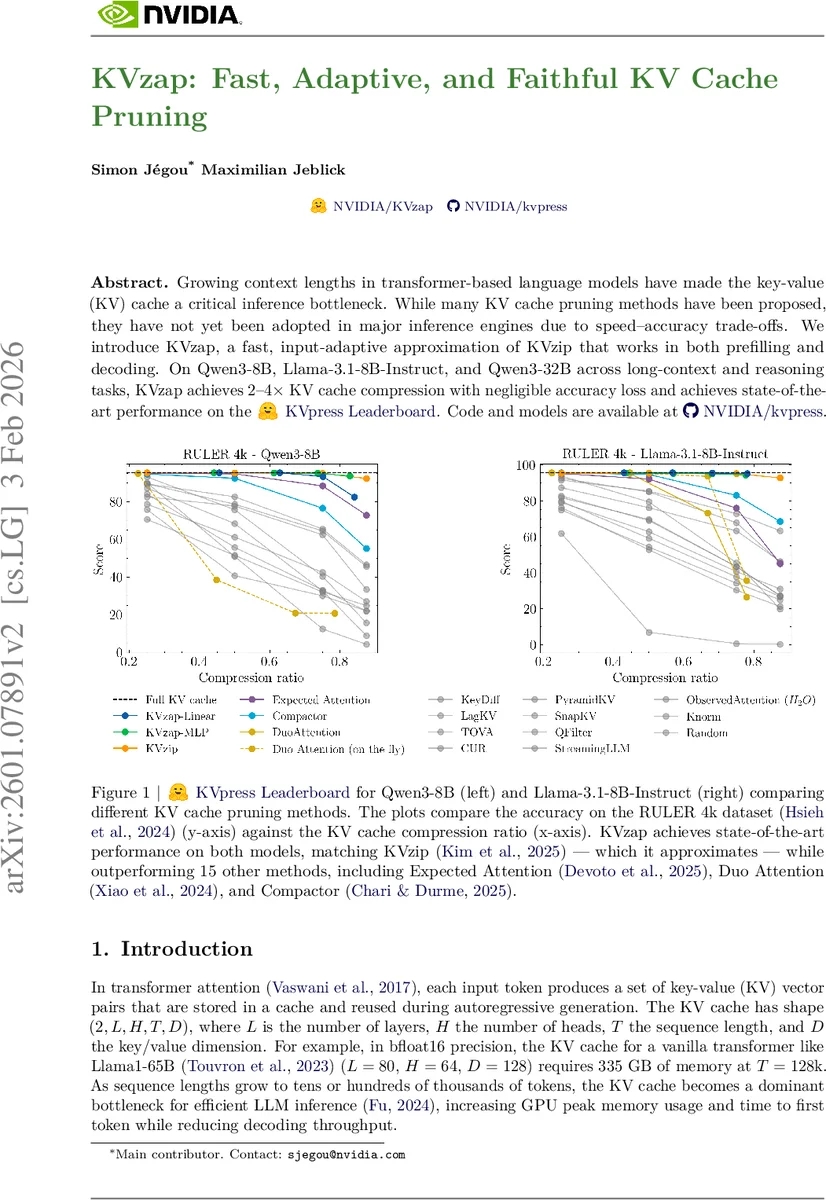
KVzap은 기존 KVzip 방법을 경량화한 입력‑적응형 프루닝 기법으로, 프리페일링과 디코딩 모두에서 KV 캐시를 2~4배 압축하면서 정확도 손실을 최소화한다. 경량 서브모델이 히든 상태에서 중요도 점수를 예측하고, 임계값 기반 삭제와 슬라이딩 윈도우를 결합해 빠른 연산과 메모리 절감을 실현한다.
상세 분석
본 논문은 트랜스포머 기반 대형 언어 모델의 KV 캐시가 메모리와 지연의 주요 병목임을 지적하고, 기존 KV 압축 기법들이 속도·정확도 트레이드오프 때문에 실용화되지 못한 점을 비판한다. KVzap은 이러한 한계를 극복하기 위해 세 가지 핵심 설계를 제시한다. 첫째, KV zip+ 점수를 근사하는 경량 서브모델(선형 또는 2‑layer MLP)을 각 레이어의 히든 상태에 적용해 토큰별 중요도를 빠르게 추정한다. 이 서브모델은 단일 행렬 곱 또는 두 번의 행렬 곱만 수행하므로 연산 오버헤드가 0.02%1.1% 수준에 머문다. 둘째, 점수 기반 임계값(τ) 방식을 도입해 고정 비율이 아닌 입력‑적응형 압축을 가능하게 한다. 복잡한 프롬프트에서는 낮은 τ를 적용해 더 많은 KV를 보존하고, 중복이 많은 경우 높은 τ로 압축률을 높인다. 셋째, 최근 128 토큰을 무조건 보존하는 슬라이딩 윈도우를 도입해 지역 컨텍스트 손실을 방지한다. 이러한 설계는 KV zip이 요구하는 두 번의 포워드 패스와 긴 프롬프트 복제 과정을 완전히 대체한다. 실험에서는 Qwen3‑8B, Llama‑3.1‑8B‑Instruct, Qwen3‑32B 모델에 대해 RULER‑4k, LongBench, AIME25 등 장문·추론 벤치마크를 수행했으며, 24배 압축에서도 정확도 손실이 0.5% 이하로 제한되었다. 특히 KV zap‑MLP은 R² 0.71~0.77을 기록해 KV zip+ 점수를 높은 상관도로 근사했으며, KV zip+ 오라클과 동등하거나 일부 경우 능가하는 성능을 보였다. 메모리 사용량은 KV 캐시 자체가 차지하는 비중이 크게 감소했으며, 디코딩 단계에서는 KV 조회 대기 시간을 활용해 GPU 연산 효율을 높였다. 종합적으로 KVzap은 기존 KV 압축 방법이 갖던 ‘속도·정확도·범용성’ 세 축을 모두 만족시키는 실용적인 솔루션으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기