효율적인 확산 변환을 위한 VFM 압축·정제 프레임워크
초록
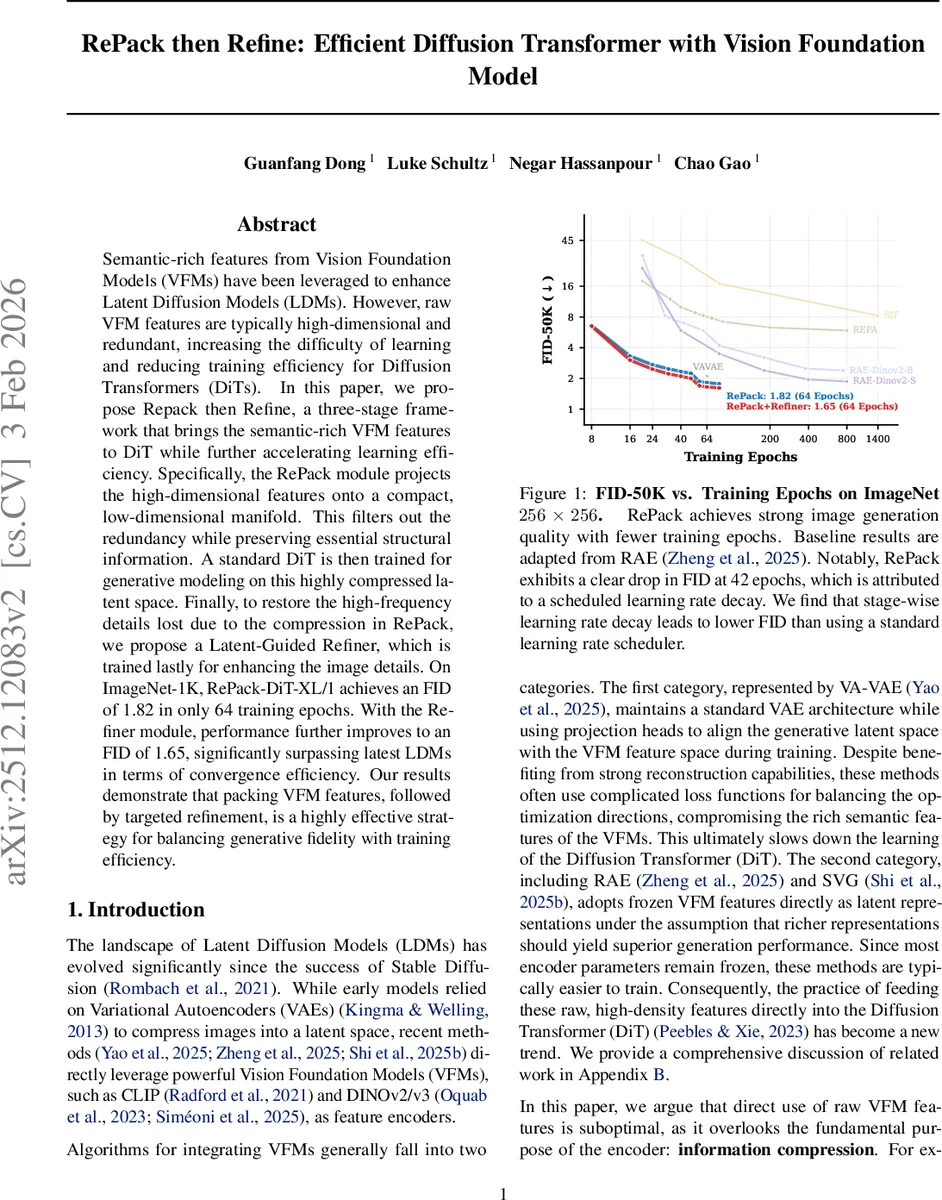
본 논문은 Vision Foundation Model(VFM)에서 추출한 고차원 특징을 32차원 저밀도 잠재공간으로 압축하는 RePack 모듈을 제안하고, 압축된 잠재를 Diffusion Transformer(DiT)로 학습한 뒤, 고주파 디테일을 복원하는 Latent‑Guided Refiner를 추가한다. 64 epoch만에 ImageNet‑1K에서 FID 1.82(Refiner 적용 시 1.65)를 달성하며, 기존 LDM 대비 학습 효율과 생성 품질 모두 크게 향상된다.
상세 분석
이 연구는 최근 VFM(예: CLIP, DINOv2/v3)을 LDM의 인코더로 활용하는 흐름에 대한 근본적인 문제점을 지적한다. VFM은 원본 이미지와 동일한 수의 요소(예: DINOv3‑B/16은 768채널, 16×16 패치)로 표현되지만, 실제 의미론적 정보는 저차원 매니폴드에 집중돼 있다. 저자들은 ImageNet‑1K 검증셋에 대해 PCA를 수행해 누적 설명 분산이 차원 32에서 77%에 도달하고, 이후는 긴 꼬리 형태로 거의 기여도가 없음을 확인했다. 이는 고차원 특징이 중복과 잡음으로 가득 차 있음을 의미한다.
이에 대한 해결책으로 제안된 RePack은 bias‑free 선형 프로젝션 Pθ를 사용해 768→32 차원으로 압축한다. 파라미터는 0.04M에 불과해 경량이며, 압축 과정에서 핵심 의미론적 구조만 남기고 불필요한 차원을 제거한다. 압축된 잠재는 가벼운 디코더 Dψ를 통해 복원 이미지 Irec을 생성하고, 이때 L1, LPIPS, adversarial, Watson, focal 등 복합 손실을 적용해 시각적 품질을 유지한다.
압축된 잠재를 이용해 학습되는 Diffusion Transformer는 LightningDiT을 기반으로 한다. RMSNorm, SwiGLU, RoPE, Rectified Flow 등 최신 설계를 도입해 학습 안정성과 수렴 속도를 높였다. 중요한 점은 RePack 단계에서 이미 의미론적 압축이 이루어졌기 때문에 DiT가 고차원 잡음에 휘둘리지 않고, 보다 부드러운 최적화 경로(blue path)를 따라 빠르게 수렴한다는 것이다. 실험 결과, 64 epoch만에 FID 1.82를 기록했으며, 이는 동일 epoch에서 기존 VAE‑기반 LDM이나 raw VFM‑직접 입력 방식보다 현저히 우수하다.
고주파 디테일 복원을 위해 별도의 Refiner를 도입한다. Refiner는 U‑Net 구조에 압축된 잠재를 bilinear upsample한 뒤 이미지와 concat하여 입력한다. 이는 “latent‑guided” 방식으로, 구조적 정보는 DiT가 담당하고, 텍스처와 세부 묘사는 Refiner가 전담한다. Refiner는 L1, LPIPS, PatchGAN 기반 adversarial loss를 사용해 훈련되며, 최종 FID는 1.65까지 개선된다.
전체 파이프라인은 3단계(Representation Packing → Generative Modeling → Latent‑Guided Refinement)로 구성되며, 각 단계는 독립적으로 학습된다. 이는 모듈 간 상호 의존성을 최소화해 구현과 확장이 용이하게 만든다. 또한, RePack이 VFM의 압축 역할을 수행함으로써 “정보 압축 = 효율적인 확산”이라는 LDM의 핵심 가정을 재확인한다.
성능 비교표를 보면, 동일한 XL/1 백본을 사용한 기존 DiT(2.27 FID)와 대비해 RePack‑DiT‑XL/1은 1.82, Refiner 적용 시 1.65로 크게 앞선다. 파라미터 규모는 비슷하거나 약간 낮으며, 학습 epoch도 현저히 적다. 이는 대규모 이미지 생성 모델에서 학습 비용을 크게 절감할 수 있음을 시사한다.
요약하면, 고차원 VFM 특징의 장기적 중복성을 정량적으로 분석하고, 경량 선형 압축을 통해 의미론적 핵심만 남긴 뒤, 효율적인 DiT와 고품질 Refiner를 결합함으로써, 빠른 수렴과 높은 이미지 품질을 동시에 달성한 혁신적인 프레임워크라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기