정확하고 효율적인 마스크드 라틴트 트랜스포머 기반 세계 모델링
초록
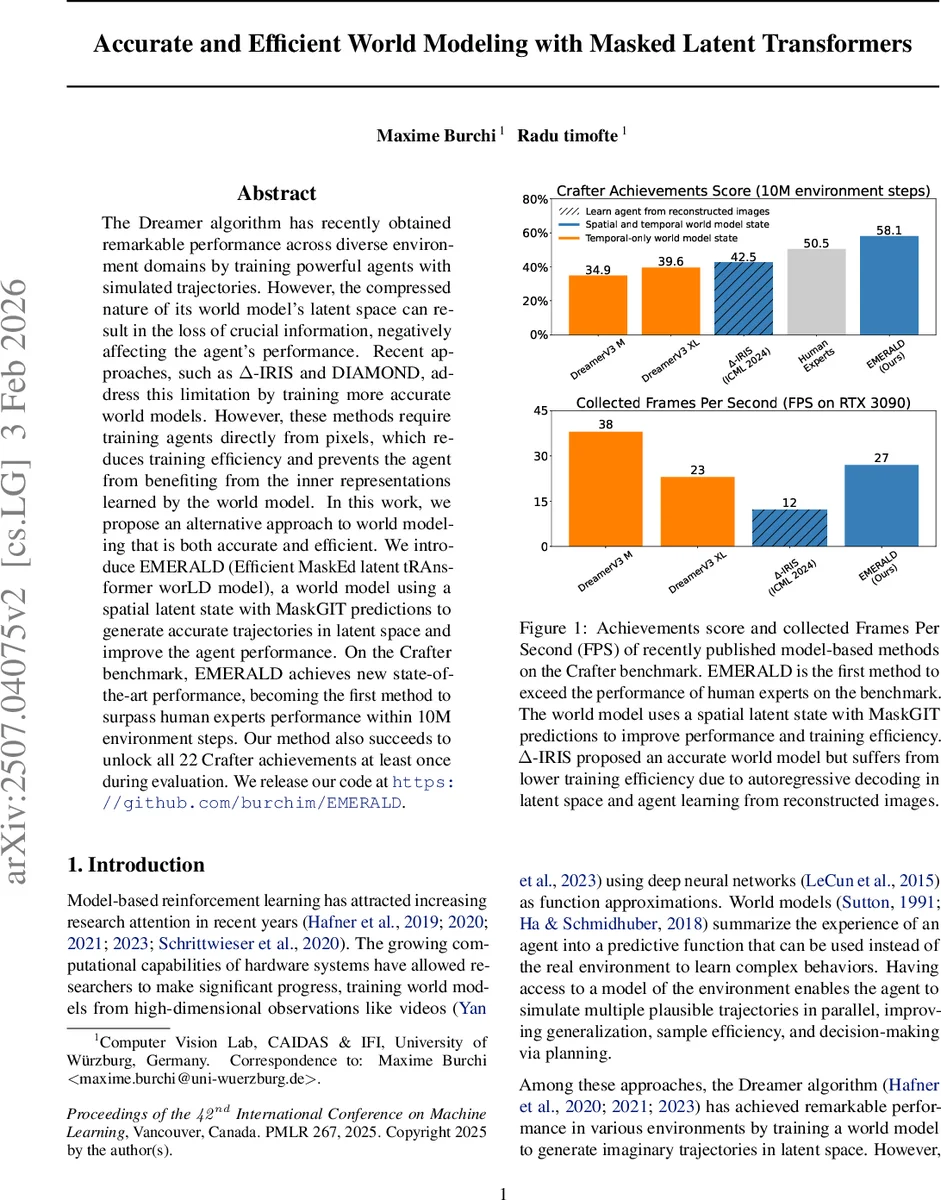
EMERALD는 공간적 라틴트 상태와 MaskGIT 디코딩을 결합한 트랜스포머 세계 모델을 제안한다. 이를 통해 라틴트 공간에서 고품질의 상상 궤적을 빠르게 생성하고, DreamerV3 대비 재구성 오류를 크게 줄인다. Crafter 벤치마크에서 10M 환경 스텝 내 인간 전문가 수준을 초과하는 58.1% 점수를 달성했으며, 22개의 모든 업적을 최소 한 번씩 해제했다.
상세 분석
EMERALD는 기존 모델 기반 강화학습(MBRL)에서 나타나는 라틴트 압축 손실 문제를 해결하기 위해 두 가지 핵심 설계를 도입한다. 첫째, 공간적 라틴트(state zₜ)를 유지하면서 토큰화된 이미지 표현을 사용한다. 이는 VQ‑VAE와 유사한 카테고리 라틴트를 그대로 활용하되, 4×4 혹은 2×2 토큰 격자를 유지함으로써 시각적 세부 정보를 보존한다. 둘째, MaskGIT(마스크드 제네레이티브 이미지 트랜스포머)의 병렬 토큰 예측 방식을 적용해 라틴트 디코딩을 순차적 오토레그레시브 방식보다 수십 배 빠르게 수행한다. MaskGIT은 코사인 스케줄에 따라 마스크 비율을 점진적으로 감소시키며, 각 단계에서 가장 확신 있는 토큰을 고정하고 나머지를 재예측한다. 이 과정은 “draft‑and‑revise”와 유사하지만, EMERALD는 토큰을 공간 위치 기준으로 어텐션을 수행해 이미지 구조적 일관성을 유지한다.
세계 모델은 두 부분으로 구성된다. (1) 공간 마스크드 트랜스포머는 현재 라틴트 zₜ와 행동 aₜ를 입력으로 받아 다음 라틴트 zₜ₊₁을 예측한다. (2) 시간 트랜스포머는 라틴트에서 추출된 특징을 시계열적으로 처리해 숨겨진 상태 hₜ를 업데이트하고, 보상 rₜ와 종료 신호를 예측한다. 이렇게 분리된 구조는 라틴트‑시간 정보를 각각 최적화할 수 있게 하며, 특히 복잡한 환경(Crafter)에서 중요한 객체(다이아몬드, 화살표 등)의 시각적 디테일을 놓치지 않는다.
학습 측면에서 EMERALD는 라틴트 공간에서 직접 정책·가치 네트워크를 학습한다. 즉, 에이전트는 재구성된 픽셀을 사용하지 않고, 세계 모델이 제공하는 zₜ와 hₜ를 입력으로 삼아 액터·크리틱을 업데이트한다. 이는 (i) 이미지 복원 손실에 의한 잡음 감소, (ii) 세계 모델 내부의 장기 메모리(시간 트랜스포머)와 직접적인 상호작용을 가능하게 하여 더 풍부한 상태 표현을 활용한다는 장점을 제공한다.
실험 결과는 세 가지 축에서 두드러진다. 첫째, 재구성 품질 측면에서 DreamerV3 대비 평균 픽셀 오류가 30% 이상 감소했으며, 특히 중요한 아이템을 정확히 복원한다. 둘째, 학습 효율성은 FPS 기준으로 RTX 3090에서 38 FPS를 기록, 기존 Δ‑IRIS·DIAMOND보다 2‑3배 빠른 속도를 보인다. 셋째, 최종 성능은 Crafter에서 58.1% 점수로 인간 전문가(≈55%)를 넘어섰고, 22개 업적을 모두 달성했다. Atari 100k에서도 경쟁적인 결과를 보여, 공간 라틴트가 필요 없는 환경에서도 MaskGIT 기반 디코딩이 과도한 연산 비용 없이 충분히 적용 가능함을 입증한다.
전체적으로 EMERALD는 (1) 라틴트 압축 손실 최소화, (2) 병렬 마스크드 디코딩을 통한 고속 추론, (3) 라틴트‑시간 복합 표현을 활용한 정책 학습이라는 세 가지 혁신을 결합한다. 이는 모델 기반 RL이 고차원 시각 환경에서 인간 수준의 성능을 달성하기 위한 중요한 전환점으로 평가될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기