구조 정렬: 대형 언어 모델을 인간‑유사 담화 구조와 맞추다
초록
본 논문은 장문 텍스트 생성 시 일관성과 논리적 흐름이 부족한 문제를 해결하고자, 인간이 사용하는 담화 구조(문제‑해결, 원인‑결과 등)와 계층적 RST(수사 구조 이론) 트리를 보상 신호로 활용하는 “구조 정렬(Structural Alignment)” 방법을 제안한다. PPO 기반 강화학습에 토큰‑단위 밀집 보상을 도입하고, 두 종류의 보상 모델(표면‑레벨 텍스트 구조 평가와 계층적 담화 모티프 기반 저자식별기)을 통해 LLM을 인간‑같은 구조적 글쓰기로 정렬한다. 실험 결과, 기존 RLHF 및 표준 LLM 대비 장문 에세이와 요약에서 가독성·일관성·수사적 품질이 크게 향상되었다.
상세 분석
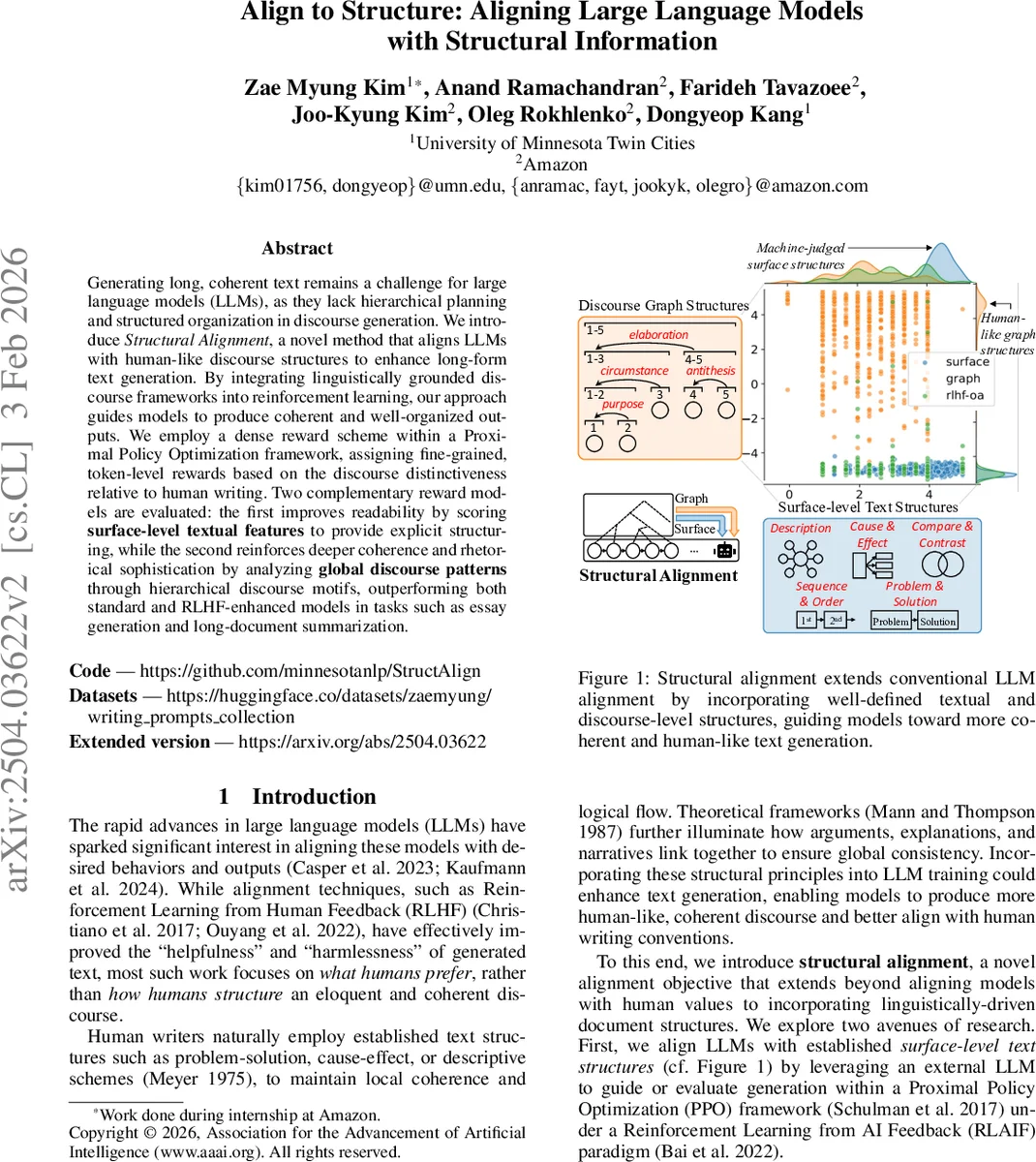
이 연구는 LLM 정렬 분야에 “구조적 정렬”이라는 새로운 목표를 도입한다는 점에서 혁신적이다. 기존 RLHF·RLAIF는 주로 인간 선호도(친절함, 안전성 등)를 최적화했지만, 텍스트의 내부 조직 원리를 직접적으로 다루지는 못했다. 논문은 두 단계의 구조 정보를 활용한다. 첫 번째는 표면‑레벨 텍스트 구조(서술 순서, 비교‑대조, 원인‑결과 등)를 외부 LLM에게 평가받아 0‑5 점수로 정량화하고, 이를 평균해 토큰‑단위 보상으로 전파한다. 두 번째는 RST 파서를 이용해 문서를 EDU 단위로 분해하고, 하이퍼그래프 형태의 “담화 모티프”를 추출한다. 이 모티프 분포는 Longformer 기반 저자식별기에 입력돼 인간·AI 텍스트를 이진 분류한다. 분류 확률을 보상으로 사용함으로써, 모델은 인간 글에 특유한 복합적 계층 구조를 모방하도록 학습된다.
핵심 기술적 기여는 다음과 같다.
- 밀집 보상 설계: 토큰‑레벨 보상을 통해 장문 생성 시 PPO의 보상 희소성을 완화하고, 학습 안정성을 높인다. 보상은 “에피소드 보상”과 “모티프 보상”을 선형 결합해, 구조적으로 중요한 토큰에 높은 가중치를 부여한다.
- 두 종류의 보상 모델 병행: 표면‑레벨 보상은 빠른 피드백을 제공해 기본적인 논리 흐름을 잡아주고, 모티프 기반 보상은 전역적인 담화 일관성을 강화한다. 두 보상이 상호 보완적으로 작동해 전체 텍스트 품질을 종합적으로 향상시킨다.
- RST 파서 확장: 기존 RST 파서는 512 토큰 이하의 입력에 제한이 있었으나, 논문은 문단 단위로 슬라이싱하고 비중첩 세그먼트를 사용해 긴 텍스트도 처리하도록 설계했다. 이렇게 얻은 모티프 벡터를 평균해 전체 텍스트의 구조적 특성을 포착한다.
실험에서는 1,000 토큰 이상 길이의 에세이와 문서 요약 과제를 사용했으며, 평가 지표는 자동화된 가독성 점수, 인간 평가자에 의한 일관성·수사성 점수, 그리고 기존 RLHF 모델 대비 인간‑AI 구분 정확도이다. 구조 정렬 모델은 특히 “논리 흐름”과 “계층적 조직” 항목에서 평균 0.6~0.8 포인트 상승했으며, 저자식별기 기반 보상을 적용한 경우 인간‑AI 구분 정확도가 92%에 달해 인간 수준의 구조를 성공적으로 모방했다.
한계점으로는 (1) RST 파서와 모티프 추출 과정이 계산 비용이 높아 대규모 사전 학습에 직접 적용하기 어려울 수 있다, (2) 현재 보상 모델은 영어 데이터에 최적화돼 있어 다국어 확장 시 추가 연구가 필요하다, (3) 인간 평가가 주관적이므로 평가 프로토콜의 표준화가 요구된다. 향후 연구에서는 경량화된 담화 파서, 다언어 RST 자원 구축, 그리고 보상 신호와 인간 선호도를 동시에 최적화하는 다중‑목표 RL 프레임워크를 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기