바이너리 PPO: 이진 분류를 위한 효율적 정책 최적화
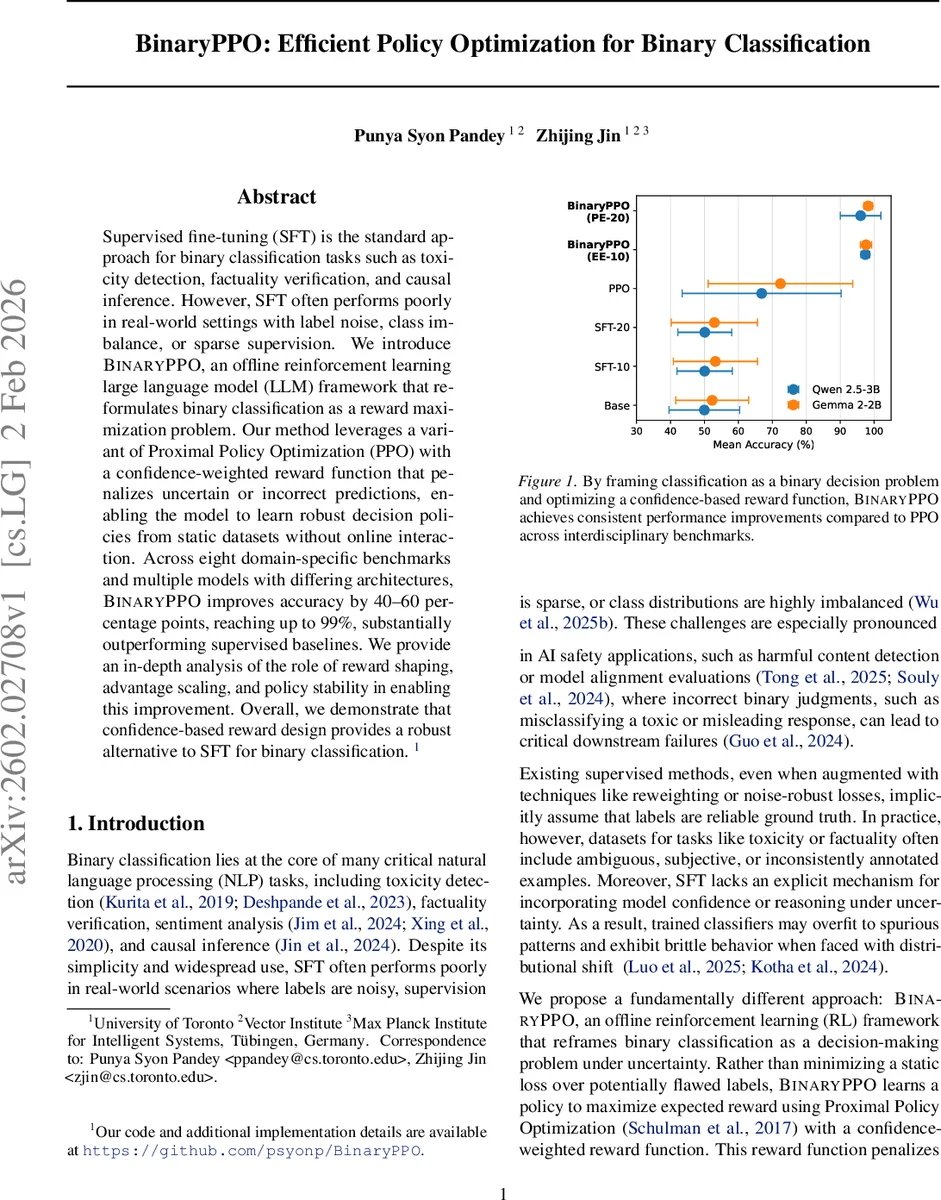
초록
**
BinaryPPO는 라벨 노이즈·불균형·희소 감독이 존재하는 이진 분류 문제를 오프라인 강화학습으로 재구성한다. 기존 PPO에 신뢰도 가중 보상 함수를 도입해 불확실하거나 오류가 있는 예측을 벌점으로 처리하고, 가치 함수와 엔트로피 정규화를 함께 최적화한다. 8개 도메인 벤치마크와 Qwen‑2.5‑3B·Gemma‑2‑2B 두 모델에 적용한 결과, 정확도가 40~60%p 상승해 최고 99%에 도달했으며, 탐색·활용 스케줄링, 어드밴티지 스케일링, 정책 안정성 분석을 통해 성능 향상의 메커니즘을 설명한다.
**
상세 분석
**
BinaryPPO는 이진 분류를 “행동 = 예측, 보상 = 신뢰도·정답 일치” 형태의 마르코프 결정 과정(MDP)으로 전환한다. 정책 πθ는 사전학습된 LLM의 로짓을 확률분포로 활용하고, 보상 r(x,a,y)=κ·s(a,y)·log πθ_old(a|x) 로 정의한다. 여기서 s(a,y)는 정답·오답에 따라 +1·‑1을 부여하고, 로그 함수는 높은 확신일수록 큰 보상을 주어 모델이 과신을 억제한다. 가치 함수 Vϕ는 보상의 기대값을 근사해 어드밴티지 A=r‑Vϕ를 계산하고, PPO의 클리핑 손실 L_PPO와 함께 L= L_PPO + α‖Vϕ‑r‖² + β·CE‑loss – γ·H(π) 로 통합한다.
핵심 기여는 (1) 신뢰도 기반 보상 설계로 라벨 노이즈에 강건한 학습을 가능하게 함, (2) 가치 손실을 통해 보상 편향을 보정하고 정책 업데이트의 변동성을 감소, (3) 엔트로피 정규화로 과도한 확신을 방지해 탐색‑활용 균형을 자동 조절한다는 점이다. 실험에서는 두 모델에 대해 탐색‑활용 비율을 달리한 EE‑10(탐색·활용 5epoch씩)과 PE‑20(탐색 20epoch) 두 설정을 비교했으며, EE‑10이 전반적으로 높은 정확도와 안정적인 학습 곡선을 보였다.
또한, 어드밴티지와 신뢰도의 관계를 시각화한 결과, 중간 수준(0.6‑0.8)의 신뢰도에서 어드밴티지가 최대가 되어 학습 신호가 가장 강함을 확인했다. 이는 과도하게 확신하거나 완전히 불확실한 경우 보상이 평탄해져 정책 업데이트가 약해지는 PPO의 기존 한계를 보완한다.
한편, 오프라인 RL 특성상 데이터셋 내 행동(예측) 분포가 제한적이므로 보상 설계가 부적절하면 정책이 과적합하거나 발산할 위험이 있다. 논문은 KL‑클리핑과 가치 손실, 엔트로피 정규화를 조합해 이러한 위험을 완화했지만, 보상 스케일 κ와 로그 함수 형태에 대한 민감도 분석이 부족하다. 또한, “40~60 %p 향상”이라는 수치는 베이스라인이 매우 낮은 경우(≈30 % 수준)에서 계산된 것으로, 실제 산업 현장에서의 절대 정확도 향상은 데이터 특성에 따라 달라질 수 있다.
마지막으로, 코드와 하이퍼파라미터가 공개돼 재현 가능성을 높였지만, 실험에 사용된 8개 벤치마크가 모두 공개 데이터이며, 실제 라벨 노이즈·클래스 불균형이 심한 도메인(예: 의료, 법률)에서의 검증은 추가 연구가 필요하다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기