희소 지도 학습을 통한 확산 모델의 전역 일관성 강화
초록
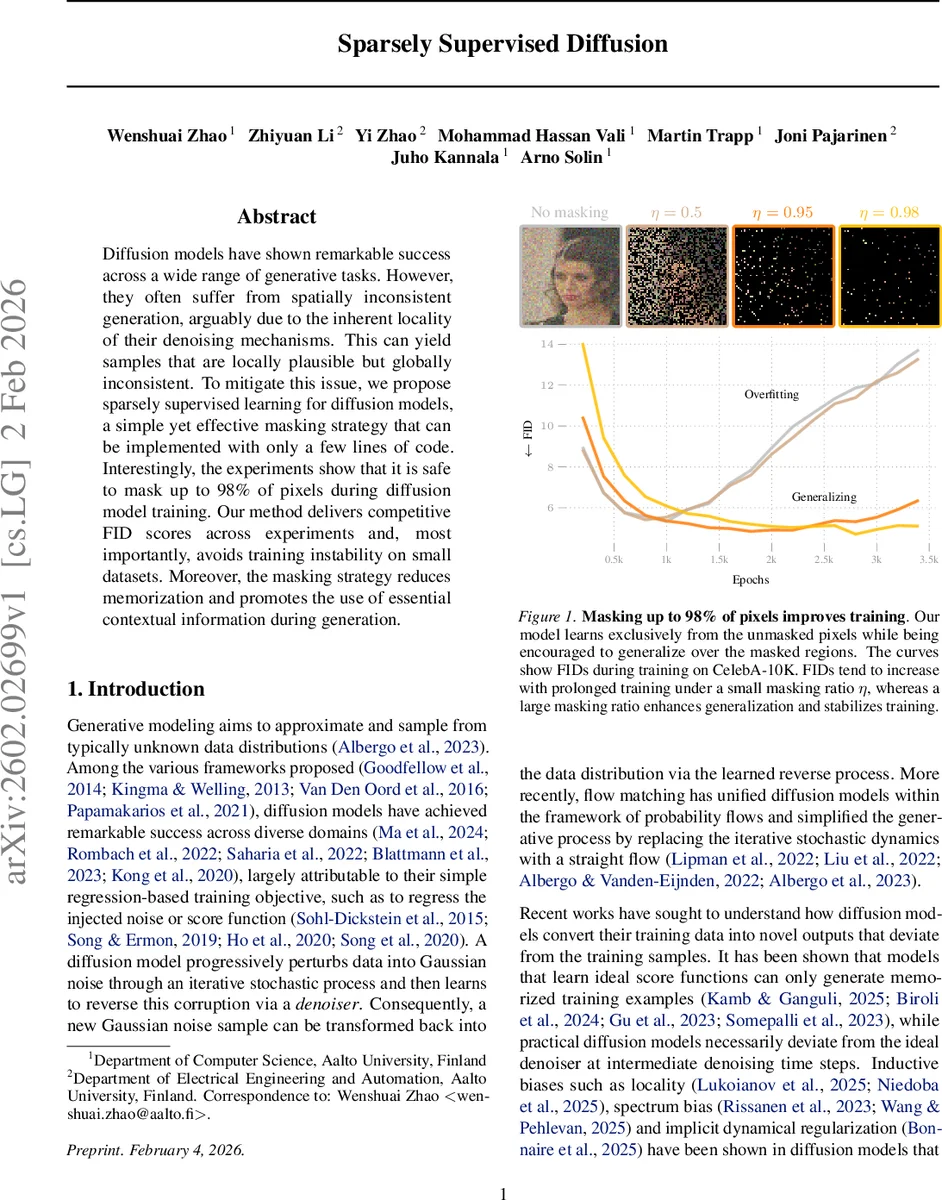
본 논문은 확산 모델 학습 시 픽셀을 무작위로 마스킹하는 “Sparsely Supervised Diffusion(SSD)” 기법을 제안한다. 98%까지 마스크 비율을 높여도 학습이 안정적이며, 전역적인 이미지 일관성을 개선하고 작은 데이터셋에서의 과적합과 기억 현상을 완화한다. 마스킹은 데이터 공분산 스펙트럼을 변형시켜 학습 역학을 바꾸고, 컨텍스트 기반 예측을 유도한다. 실험 결과 CelebA‑10K, CIFAR‑10 등에서 FID 점수가 경쟁력을 유지하면서도 훈련 안정성이 크게 향상됨을 보인다.
상세 분석
SSD는 기존 확산 모델의 회귀 손실에 무작위 이진 마스크 m을 적용해, 마스크된 픽셀을 손실 계산에서 제외한다. 마스크 비율 η가 0.98에 달해도 모델은 남은 2% 픽셀만을 보고 전체 이미지를 복원하도록 학습한다. 이 과정에서 모델은局所적인 주변 정보에만 의존하던 기존의 “locality bias”를 넘어, 남은 픽셀들 사이의 전역적인 컨텍스트를 활용하게 된다. 논문은 마스킹이 데이터 공분산 Σ에 미치는 영향을 수식적으로 분석한다. 마스크 적용 후 공분산 ˜Σ는 ˜Σ = (1‑η)² Σ + η(1‑η) D 형태이며, 여기서 D는 Σ의 대각 성분만을 남긴 행렬이다. 즉, 마스킹은 비대각 원소(특히 저주파 상관관계)를 크게 억제하고, 대각 원소(픽셀 개별 분산)를 상대적으로 보존한다. 이로 인해 스펙트럼 비율 βᵢ = ˜λᵢ/λᵢ가 (1‑η)² + η(1‑η)·(uᵢᵀDuᵢ)/λᵢ 형태로 변형돼, 저주파 성분이 약화되고 고주파 성분이 상대적으로 강조된다. 결과적으로 학습 초기에 저주파 일반화가 빠르게 진행되며, 이후 고주파 세부 정보를 학습할 때 과적합 위험이 감소한다. 실험에서는 η = 0.8, 0.95, 0.98 등 다양한 마스크 비율을 적용했을 때, FID가 초기에는 상승하지만 장기적으로는 낮은 마스크 비율보다 더 안정적인 수렴을 보였다. 특히 작은 데이터셋(CelebA‑10K)에서 마스크 없이 학습하면 빠르게 과적합해 FID가 급격히 악화되지만, 98% 마스크 적용 시 훈련이 3 k step까지도 안정적으로 진행된다. 또한, 마스크된 영역을 복원하는 과정에서 모델이 “컨텍스트 기반 추론”을 학습함으로써, 동일 이미지에 대해 여러 번 다른 마스크를 적용해도 일관된 전역 구조를 유지한다. 이는 기존 MAE‑형식 마스크와 달리 회귀 손실에 직접 마스크를 삽입함으로써 아키텍처에 독립적인 접근법을 제공한다는 점에서도 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기