선형 어텐션 LLM의 상태 랭크 계층화와 효율적 프루닝
초록
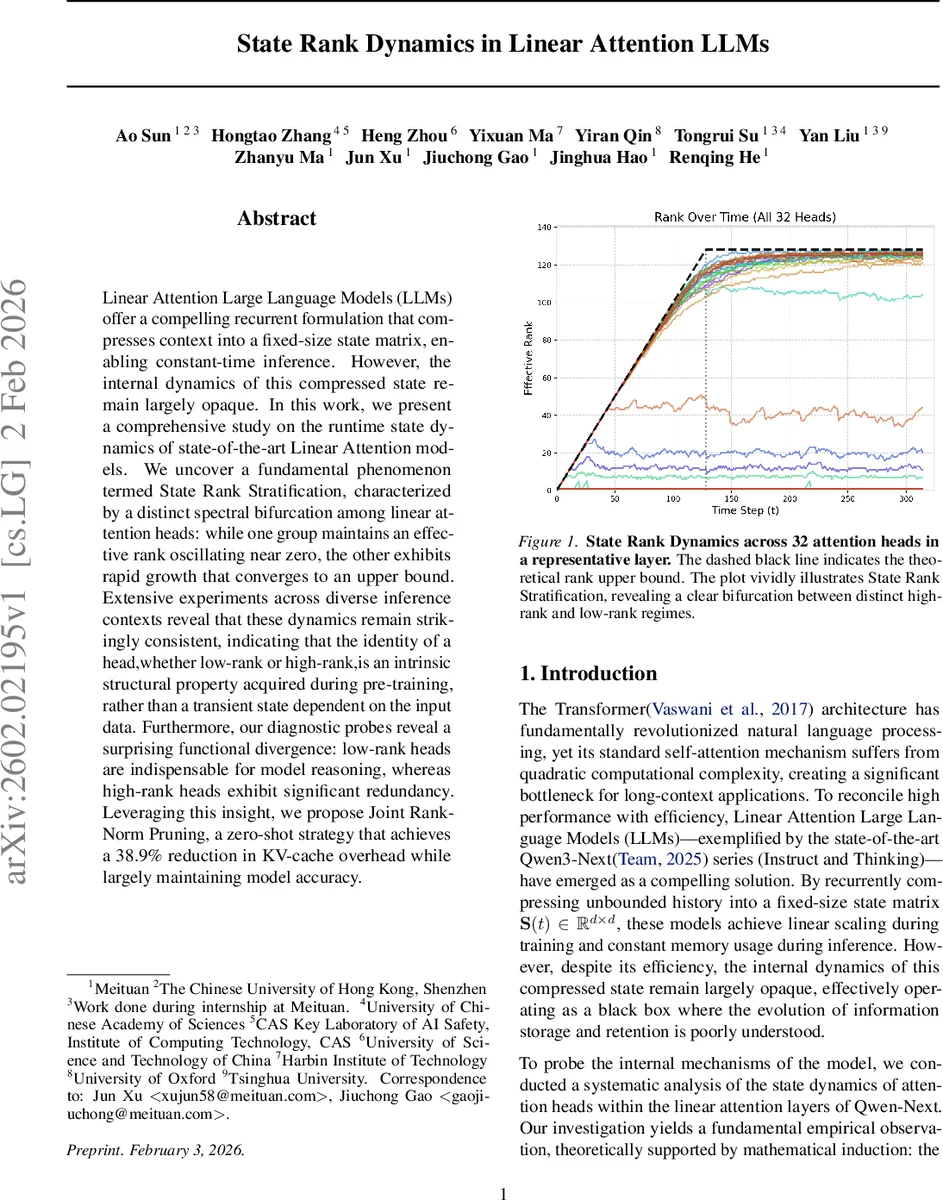
본 논문은 선형 어텐션 기반 대형 언어 모델에서 내부 상태 행렬의 랭크가 두 그룹으로 명확히 구분되는 현상, 즉 “상태 랭크 계층화(State Rank Stratification)”를 발견한다. 한 그룹은 거의 영에 가까운 낮은 랭크를 유지하고, 다른 그룹은 빠르게 성장해 이론적 상한에 수렴한다. 이러한 구분은 시간·데이터에 대해 불변이며, 저랭크 헤드가 모델의 추론 능력에 핵심적인 반면 고랭크 헤드는 상당히 중복됨을 보인다. 이를 기반으로 제안된 “Joint Rank‑Norm Pruning”은 KV‑캐시 메모리를 38.9 % 절감하면서 정확도 손실을 최소화한다.
상세 분석
본 연구는 최신 선형 어텐션 LLM인 Qwen‑Next 시리즈를 대상으로, 각 어텐션 헤드가 유지하는 상태 행렬 S(t) 의 스펙트럼을 지속적으로 추적하였다. 먼저, 상태 행렬의 랭크는 rank(S(t)) ≤ min(t, d) 라는 정리(정리 3.1)를 통해 이론적 상한이 존재함을 증명한다. 여기서 d 는 모델 차원, t 는 현재 토큰 위치이며, t ≥ d 시점부터는 랭크 포화(Rank Saturation) 단계에 진입한다. 실험적으로는 32개의 헤드가 두 개의 뚜렷한 군집으로 나뉘는 것을 확인했는데, 하나는 초기 단계부터 거의 영에 가까운 Effective Rank 값을 유지하며 변동이 미미하고, 다른 하나는 빠르게 성장해 상한에 근접한다.
시간적 일관성 분석에서는 헤드별 랭크 벡터 r(t) 와 핵노름 벡터 n(t) 에 대해 코사인 유사도와 스피어만 순위 상관을 계산하였다. t = 128 과 t = 2048 사이의 비교에서 ρ(rₜ₁, rₜ₂) > 0.90, CosSim(nₜ₁, nₜ₂) > 0.98 이라는 높은 일관성을 보였으며, 이는 헤드의 “고‑랭크/저‑랭크” 속성이 초기 단계에 고정되고 이후 토큰에 의해 크게 변하지 않음을 의미한다.
데이터 독립성 실험에서는 자연어(WikiText), 코드(GitHub), 수학 텍스트(arXiv) 등 서로 다른 도메인에 대해 동일한 헤드 구성이 유지되는지를 검증하였다. 결과는 입력 데이터의 통계적 차이가 상태 행렬의 구체적 값에는 영향을 주지만, 고‑랭크와 저‑랭크 헤드의 분포 자체는 변하지 않음을 보여준다. 이는 사전 학습 단계에서 W_K, W_V 가 이미 헤드별 정보 처리 용량을 암묵적으로 정의한다는 강력한 증거이다.
또한, 적대적 반복 입력(특정 문자·숫자 루프)에서는 랭크가 주기적으로 감소하고, 일반적인 성장 패턴이 깨지는 현상이 관찰되었다. 이는 반복적인 토큰이 새로운 차원 정보를 제공하지 못해 상태 행렬이 기존 서브스페이스에 머무르게 함을 시사한다.
이러한 관찰을 바탕으로 저자들은 “Joint Rank‑Norm Pruning”이라는 무학습(zero‑shot) 프루닝 전략을 제안한다. 핵심 아이디어는 고‑랭크 헤드가 핵노름이 크게 축적되지만 실제 추론에 기여도가 낮은 경우가 많다는 점이다. 따라서 고‑랭크 헤드 중 핵노름이 상대적으로 낮은 헤드를 선택적으로 제거하고, 남은 저‑랭크 헤드는 그대로 유지한다. 실험 결과, KV‑캐시 메모리를 38.9 % 절감하면서도 베이스 모델과 거의 동일한 퍼플렉시티·정확도를 유지한다.
이 논문은 선형 어텐션 모델의 내부 메모리 메커니즘을 최초로 정량적으로 규명하고, 헤드‑레벨 스펙트럼 특성을 이용한 효율적인 모델 압축 방법을 제시함으로써, 장기 컨텍스트 처리와 실시간 추론 모두에서 실용적인 가치를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기