초고속 온칩 온라인 학습을 가능하게 하는 KAN 스플라인 로컬리티
초록
본 논문은 서브마이크로초 수준의 초저지연이 요구되는 양자 컴퓨팅·핵융합 제어 등 고주파 시스템에서, 고정소수점 연산과 제한된 메모리 환경에 최적화된 Kolmogorov‑Arnold Network(KAN)의 온라인 학습 구현을 제안한다. B‑스플라인의 국소성을 이용해 파라미터 업데이트를 희소하게 만들고, 고정소수점 양자화에 대한 내성을 증명함으로써 FPGA 상에서 MLP 대비 훨씬 낮은 레이턴시와 자원 사용량을 달성한다. 실험 결과, 회귀, 단일샷 큐비트 판독, 비정상적인 Acrobot 제어 등 다양한 스트리밍 작업에서 KAN이 MLP보다 높은 정확도·수렴 속도와 10‑100배 빠른 업데이트를 보인다.
상세 분석
이 논문은 초고속 온칩 온라인 학습이라는 매우 제한된 하드웨어 조건(서브마이크로초 레이턴시, 고정소수점 연산, 온칩 메모리 제한)에서 기존의 다층 퍼셉트론(MLP)이 갖는 근본적인 비효율성을 체계적으로 분석한다. 핵심 아이디어는 Kolmogorov‑Arnold Network(KAN)의 활성화 함수가 B‑스플라인 기반이라는 점이다. B‑스플라인은 차수 p에 따라 최대 p+1개의 베이스 함수만이 특정 입력 구간에 활성화되므로, 한 샘플에 대해 계산해야 할 파라미터는 전체 파라미터 수 N이 아니라 O(p) 수준으로 제한된다. 논문은 이를 정리한 Lemma 3.2와 Theorem 3.3을 통해 “업데이트 복잡도 감소”를 수학적으로 증명하고, 동일 파라미터 예산 하에서 KAN이 MLP보다 1~2 orders of magnitude 적은 연산량을 요구함을 보여준다.
또한 KAN은 그 자체가 파라미터의 선형 결합 형태이기 때문에 출력값이 파라미터 범위 내에 제한된다(Theorem 3.4). 이는 고정소수점 양자화 시 발생하는 오버플로우와 언더플로우 위험을 크게 감소시킨다. 반면 MLP는 입력값과 가중치의 곱으로 인해 입력 스케일에 민감하고, 양자화 오차가 입력 분산에 비례해 증폭된다(Theorem 3.5). 따라서 KAN은 동일 비트폭에서도 수치적으로 더 안정적이며, 학습률을 크게 낮추지 않아도 수렴이 가능하다.
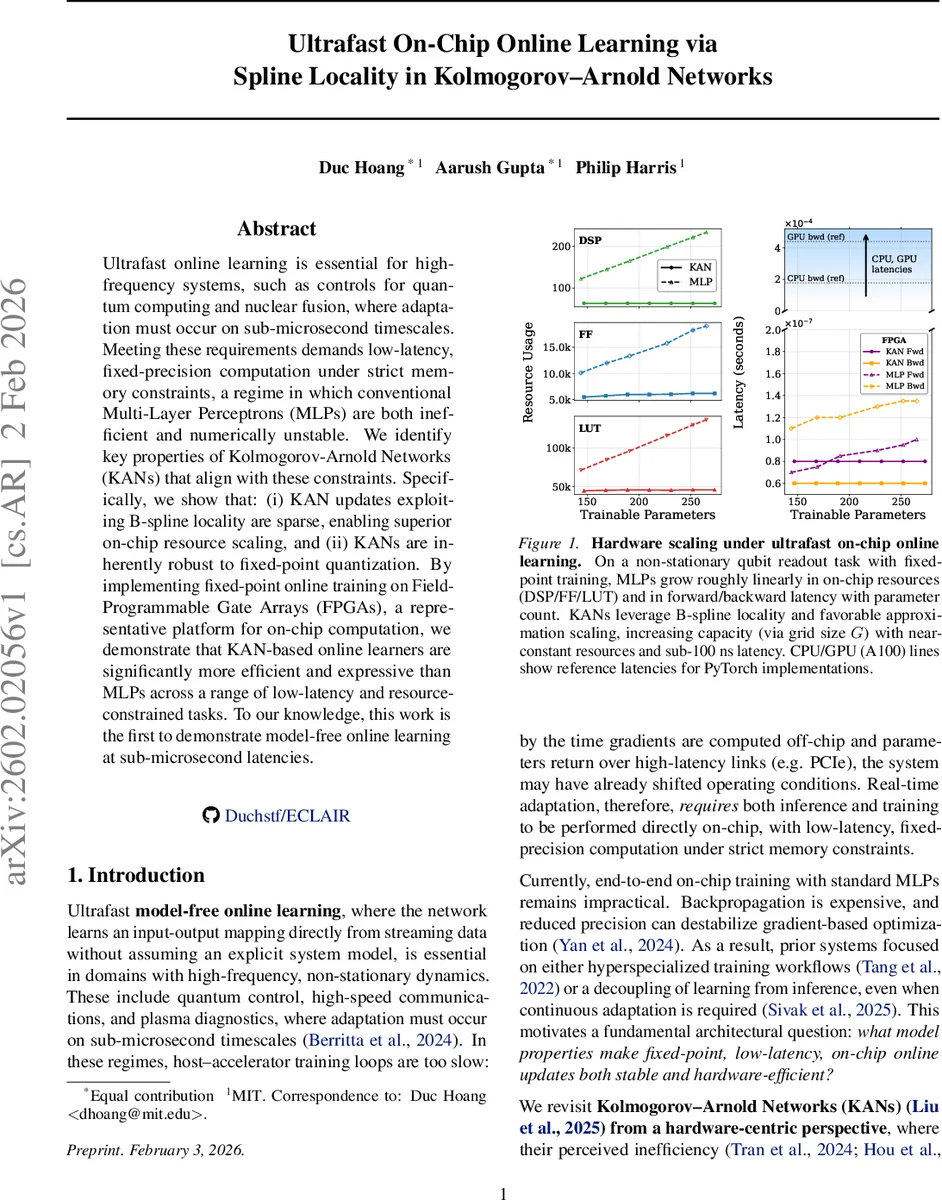
하드웨어 구현 측면에서는 FPGA(AMD Virtex UltraScale+ XCVU13P) 위에 HLS 기반 커스텀 커널을 설계하였다. KAN 커널은 입력을 그리드 인덱스로 매핑하고, 사전 계산된 ROM LUT에서 활성 B‑스플라인 값과 그 도함수를 읽어와 연산한다. 업데이트 단계에서는 해당 인덱스에 해당하는 p+1개의 계수만을 선택적으로 수정한다. 반면 MLP 커널은 전통적인 dense MAC 연산과 전체 가중치·바이어스 업데이트를 수행한다. 실험 결과, KAN은 200 MHz 클럭에서 전방·후방 레이턴시가 4~5 ns 수준으로, MLP는 100 ns 이상으로 차이가 났으며, DSP·LUT 사용량도 각각 8k vs 15k 등 크게 절감되었다.
세 가지 벤치마크(드리프트 회귀, 단일샷 큐비트 판독, 비정상 Acrobot 제어)에서 KAN은 동일 파라미터 수(N≈300)에서도 MLP‑P(파라미터 매칭)보다 23배 높은 정확도·수익을 기록했고, 파라미터를 늘린 MLP‑L과도 경쟁하거나 우위를 차지했다. 특히 고정소수점(⟨6,2⟩⟨22,8⟩) 환경에서도 KAN은 학습 안정성을 유지했으며, 양자화에 민감한 MLP는 종종 발산하거나 성능 저하를 보였다. 마지막으로 고차원 MNIST‑like 실험에서 그리드 크기 G를 늘려도 연산량이 거의 변하지 않아, 메모리만 충분히 확보한다면 KAN은 매우 높은 표현력을 유지할 수 있음을 시연했다.
전체적으로 이 논문은 KAN이 “스파스·로컬·정량화-안정”이라는 세 가지 하드웨어 친화적 특성을 갖추고 있음을 증명하고, FPGA와 같은 온칩 플랫폼에서 실시간 온라인 학습을 구현할 수 있는 실용적인 로드맵을 제공한다. 이는 기존 MLP 중심의 온칩 학습 연구가 직면한 수치 불안정성·연산량·메모리 병목을 근본적으로 해소하는 중요한 진전이다.
댓글 및 학술 토론
Loading comments...
의견 남기기