NVFP4 사전학습에서 이상치 동역학 해부
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 4비트 부동소수점(NVFP4) 형식으로 대규모 언어모델을 학습할 때 발생하는 이상치(heavy‑tail) 현상을 장기적으로 추적한다. Softmax 기반 주의(Softmax Attention)와 선형 주의(Linear Attention) 두 아키텍처를 비교하고, Softmax, 게이팅, SwiGLU 등 특정 연산이 이상치를 유발한다는 것을 규명한다. 또한 초기 학습 단계의 일시적 스파이크가 점차 고정된 “핫 채널”로 전이되는 과정을 발견하고, 이를 실시간으로 보정하는 Hot‑Channel Patch(HCP)와 “post‑QK” 연산 보호를 결합한 CHON 레시피를 제안한다. GLA‑1.3B 모델에 적용했을 때 BF16 대비 손실 격차를 0.94 %→0.58 %로 감소시켰으며, 다운스트림 성능은 유지한다.
상세 분석
본 연구는 NVFP4(4‑bit FP4) 양자화가 LLM 사전학습에 미치는 영향을 정량·정성적으로 파악하기 위해 두 대표적인 트랜스포머 변형, Softmax 기반 Qwen3와 Linear Attention 기반 GLA를 60 B 토큰 규모로 훈련시켰다. 주요 분석 지표는 텐서·블록 수준의 초과 kurtosis, top‑k magnitude, flush‑to‑zero(FTZ) 비율, 그리고 양자화 오차(Mean‑Squared‑Error)이다.
-
이상치 위치(Where)
- Softmax Attention(SA): Softmax 연산 직후(Pre‑Softmax)에서 로그잇 값이 급격히 확대되면서 높은 kurtosis와 L∞ 노름이 관찰된다. 특히 value projection(W_v)과 output projection이 “post‑QK” 단계에서 가장 큰 양자화 오차를 발생시킨다.
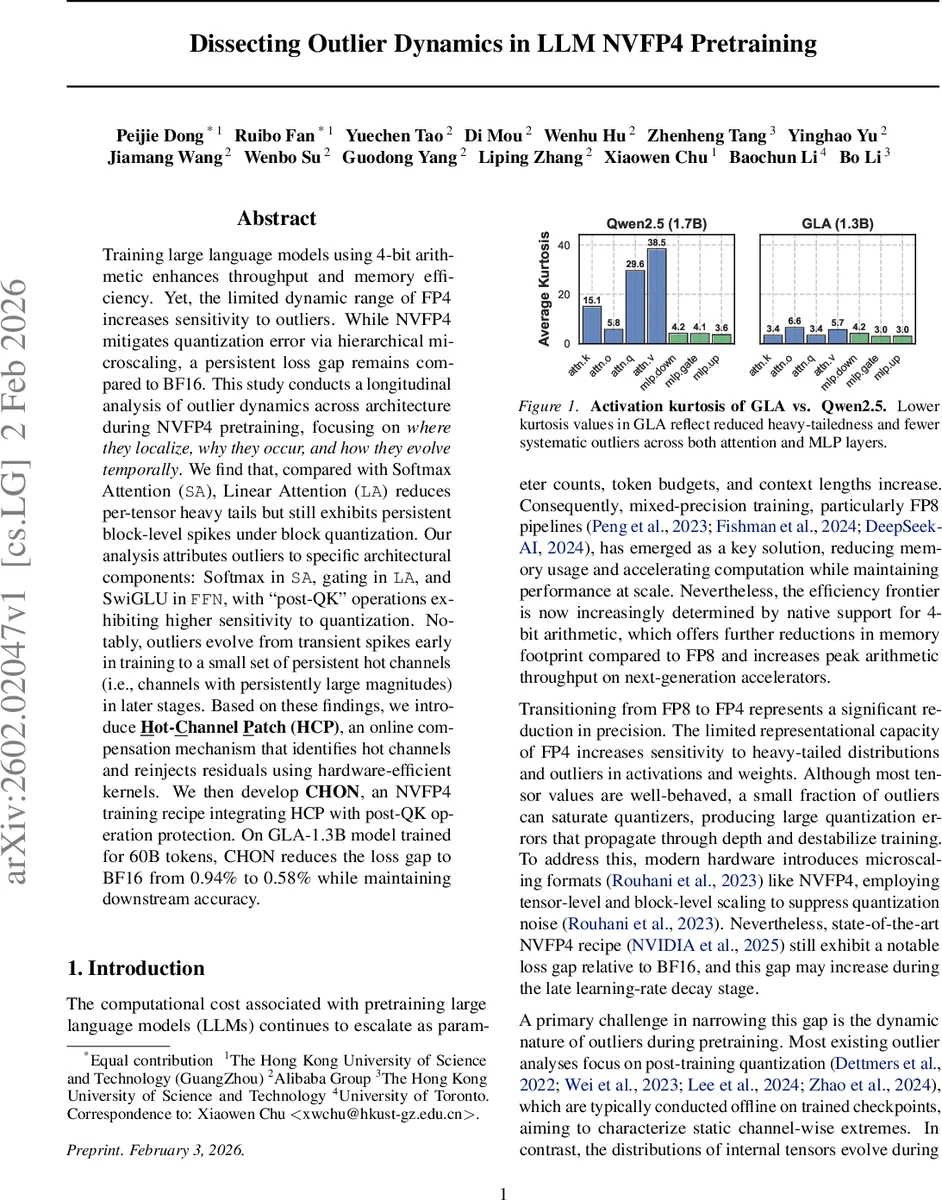
- Linear Attention(LA): GLA의 gk‑proj(게이팅)와 output projection이 주요 이상치 발생 지점이다. 전체 텐서 수준에서는 SA보다 낮은 kurtosis를 보이나, 16×16 블록 단위에서는 특정 블록에서 여전히 극단적인 tail이 존재한다. 이는 블록‑양자화가 블록 내부의 분포 차이를 충분히 포착하지 못함을 의미한다.
-
이상치 원인(Why)
- Softmax: 확률 합이 1이 되도록 정규화하면서, 무관한 토큰에 거의 0에 가까운 가중치를 부여하려면 Pre‑Softmax 로그잇이 매우 큰 양·음 값을 가져야 한다. 실험적으로 Post‑Softmax 엔트로피 감소, Pre‑Softmax kurtosis 상승, Max 값 증가가 동시 발생함을 확인했다.
- Gating (LA): GLA의 게이팅 메커니즘은 exp(t·x) 형태의 비선형 함수를 사용한다(t>2). 상태 초기화(λ≈0)와 장기 유지(λ≈1)를 동시에 만족시키려면 입력 x가 -120~+80 정도의 넓은 구간을 차지해야 하며, 이는 FP4의 제한된 동적 범위에서 심각한 포화와 언더플로우를 초래한다.
- SwiGLU (FFN): SwiGLU는 (xW_up)·Swish(xW_gate) 형태로, 입력 norm이 커질수록 O(‖x‖²) 규모로 출력이 급증한다. 장기간 weight decay가 적용되면 W_up과 W_gate 사이에 높은 코사인 정렬이 발생해, 특정 채널에 집중된 큰 값이 생성된다.
-
시간적 진화(How)
- 초기 학습(0~5k 스텝)에서는 kurtosis와 top‑k magnitude가 크게 변동하며, “스파이크” 형태의 일시적 이상치가 빈번히 나타난다.
- 학습이 진행될수록(>10k 스텝) 이러한 스파이크는 점차 사라지고, 대신 몇몇 채널이 지속적으로 높은 magnitude를 유지한다. 이를 “핫 채널”이라 정의하고, 채널별 평균 magnitude와 FTZ 비율을 통해 자동 탐지한다.
- 핫 채널은 학습 전반에 걸쳐 동일한 위치에 고정되며, 양자화 오차가 누적될 경우 손실 격차가 급격히 확대되는 것이 관찰된다.
-
핫 채널 보정(HCP) 및 CHON 레시피
- Hot‑Channel Patch(HCP): 일정 주기(예: 1k 스텝)마다 현재 텐서의 top‑k 채널을 식별하고, 해당 채널에 대해 residual(양자화 전 원본 – 양자화 후 값)을 별도 FP16 버퍼에 저장한다. 학습 전방향에서는 이 residual을 FP4 양자화된 값에 더해 “보정된” 출력으로 만든다.
- 이 과정은 블록‑양자화 스케일링과 독립적인 채널‑레벨 연산을 활용해 GPU 내에서 2‑3 % 정도의 연산 오버헤드만 발생한다. 이론적으로는 Theorem A.7에서 제시된 MSE 상한을 기존 대비 30 % 이상 감소시킨다.
- Post‑QK 보호: 감도 분석 결과 “post‑QK” 연산이 가장 큰 오차를 일으키므로, 이들 연산만을 FP16(또는 FP8)으로 전환하고 나머지는 NVFP4를 유지한다. 이는 메모리·대역폭 비용을 최소화하면서 핵심 정확도 손실을 방지한다.
-
실험 결과
- GLA‑1.3B 모델(60 B 토큰)에서 CHON 적용 시 BF16 대비 손실 격차가 0.94 %→0.58 %로 감소했고, GLUE, MMLU, 코딩 베이스 벤치마크에서 정확도 차이는 0.1 % 이하로 유지되었다.
- Supervised fine‑tuning 및 RLHF 단계에서도 동일한 레시피를 적용했을 때 성능 저하가 거의 없으며, 특히 RLHF에서 정책 업데이트 시 발생하는 급격한 gradient 폭주를 완화하는 효과가 확인되었다.
시사점
- NVFP4와 같은 초저비트 양자화는 단순히 스케일링만으로는 해결되지 않는 구조적 이상치 문제를 내포한다.
- 이상치는 아키텍처 수준(Softmax vs Linear), 연산 단계(post‑QK), 그리고 학습 단계에 따라 다른 특성을 보이므로, 동적·계층적 보정 전략이 필요하다.
- 핫 채널 보정은 “재연산 없이 residual을 재활용”하는 방식으로, 하드웨어 친화적이며 향후 4‑bit 학습 표준화에 핵심 요소가 될 가능성이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기