초고속 FPGA 학습의 필요성
초록
본 논문은 현재 FPGA 기반 추론 가속기가 정적 모델에 의존하고 있어, 물리 현상의 빠른 변동에 실시간으로 적응하지 못한다는 문제를 제기한다. 저자는 서브마이크로초 수준의 결정론적 지연으로 온칩 학습을 구현함으로써 양자 오류 정정, 플라즈마 제어, 입자 검출기 등 비정상적·고주파 환경에서 닫힌 루프 적응 시스템을 가능하게 해야 한다고 주장한다. 이를 위해 알고리즘, 아키텍처, CAD 툴플로우의 공동 재설계가 필요함을 강조한다.
상세 분석
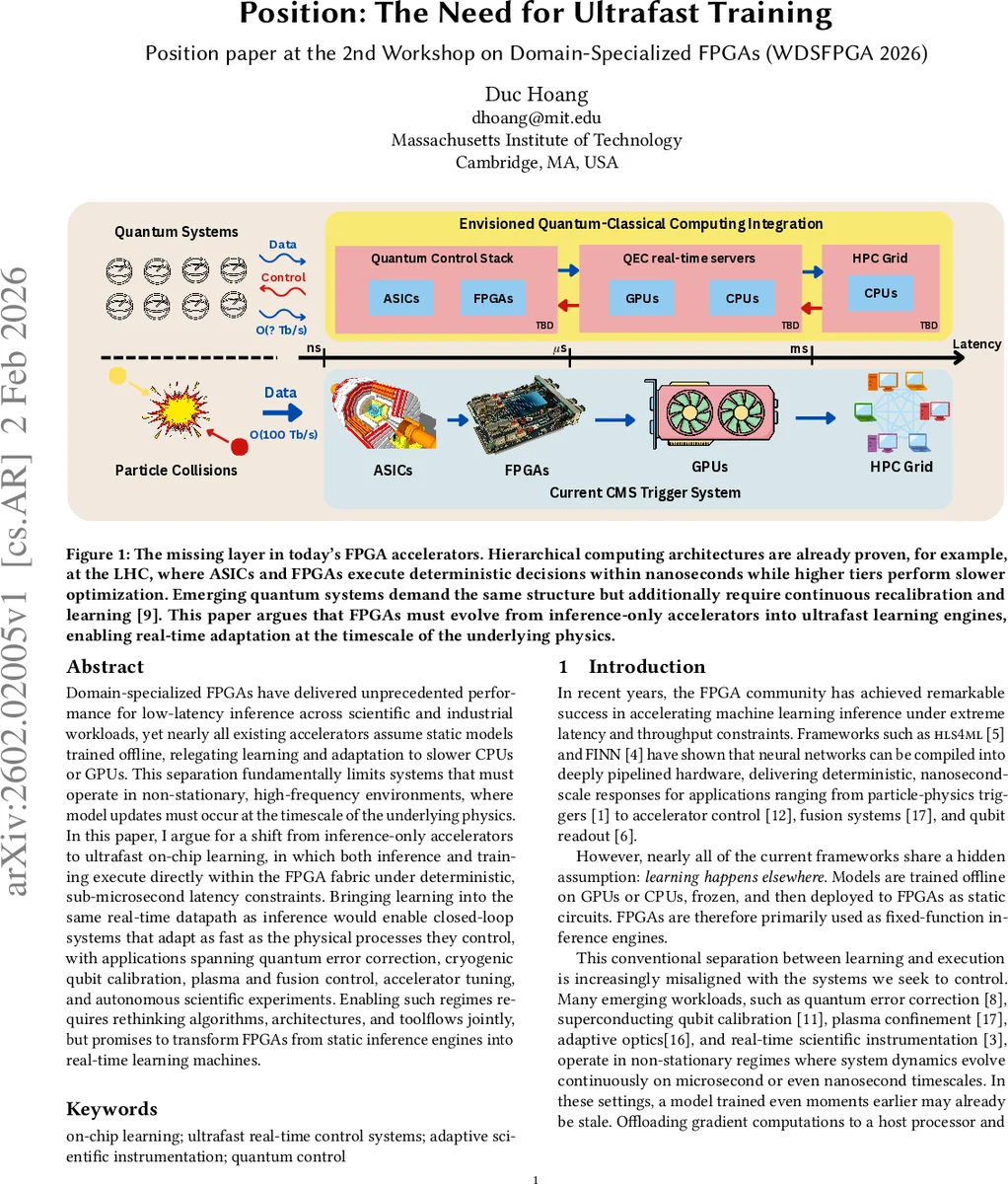
이 논문은 FPGA가 과거 수십 년간 추론 전용 가속기로 진화해 온 과정을 짚으며, 현재의 설계 패러다임이 “학습은 외부에서 수행한다”는 전제에 기반하고 있음을 비판한다. 특히, 양자 컴퓨팅, 초저온 큐비트 보정, 플라즈마 구속, 적응 광학 등에서 제어 파라미터가 마이크로초 혹은 나노초 단위로 변동하는 비정상(non‑stationary) 환경을 다룰 때, 기존의 CPU/GPU 기반 오프라인 학습은 인터커넥트 지연과 스케줄링 변동으로 인해 실시간 피드백 루프를 파괴한다.
핵심 기술적 도전 과제로는 (1) 결정론적 초저지연: 학습 단계에서도 지연 변동(jitter)이 허용되지 않으며, 파이프라인 전체가 고정된 사이클 수를 유지해야 한다. (2) 제한된 로컬 메모리: 활성값, 그래디언트, 옵티마이저 상태 등을 저장할 온칩 SRAM/BRAM/URAM 용량이 제한적이므로, 메모리 접근 패턴을 최소화하고 스트리밍 방식으로 업데이트를 수행해야 한다. (3) 고정소수점 연산의 수치 안정성: FPGA는 일반적으로 정밀도와 면적을 절감하기 위해 고정소수점 연산을 사용하지만, 그래디언트 전파는 동적 범위와 양자화 오차에 민감해 수렴이 어려울 수 있다. 따라서 스케일링, 클리핑, 양자화 친화적 옵티마이저 설계가 필수적이다. (4) 툴체인 부재: 현재 hls4ml, FINN 등은 순방향(인퍼런스) 전용 파이프라인을 최적화하도록 설계돼 있어, 상태를 유지하고 지속적으로 파라미터를 업데이트하는 백프로파게이션 로직을 자동으로 합성하기 어렵다.
논문은 이러한 제약을 극복하기 위한 연구 로드맵을 제시한다. 알고리즘 측면에서는 희소/구조화된 모델(예: 스파스 뉴럴 네트워크, 바이너리/테너리 가중치)과 온라인 학습(예: 스트리밍 SGD, 메모리 효율적인 RLS) 등을 탐색하고, 학습 가능성을 평가하기 위한 실시간 학습 벤치마크와 지연·메모리·정밀도 트레이드오프 메트릭을 정의한다. 아키텍처 측면에서는 업데이트 전용 엔진(예: 파이프라인형 그래디언트 축적기, 파라미터 버퍼링 구조)과 인퍼런스와 학습을 동시에 수행할 수 있는 이중 포트 메모리를 제안한다. 또한, 학습 중에도 인퍼런스 파이프라인을 방해하지 않는 무중단 파라미터 교체 메커니즘이 필요하다. 툴플로우에서는 상태ful HLS와 시간 보장 스케줄링을 지원하는 새로운 합성 옵션, 그리고 비트‑정밀도 자동 튜닝 및 수치 검증을 위한 시뮬레이션 프레임워크가 요구된다.
양자 제어 사례를 통해, 1 µs 이하의 보정 루프가 실리콘 큐비트의 10 µs 수준 디코히런스 시간보다 빠르게 동작하면, 저주파 1/f 노이즈를 평균화하면서 고주파 변동에도 즉각 대응할 수 있음을 보인다. 이는 기존의 주기적 재보정 방식보다 수십 배 빠른 적응성을 제공한다.
전반적으로, 논문은 “학습 자체를 실시간 원시 연산으로 만든다”는 급진적 비전을 제시하면서, 현재의 FPGA 생태계가 이를 지원하기 위해서는 알고리즘, 하드웨어, 툴 전반에 걸친 구조적 변혁이 필요함을 설득력 있게 논증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기