IntraSlice 블록 내부 PCA 기반 구조적 프루닝으로 LLM 고성능 압축
초록
IntraSlice는 트랜스포머 모듈 내부에서 블록 단위로 PCA 압축을 수행해 구조적 프루닝을 구현한다. 근사 PCA와 진행형 슬라이스 반복 PCA를 결합해 변환 행렬을 가중치에 완전히 융합함으로써 추가 파라미터 없이 압축 효율을 높이고, 전역 비균일 프루닝 비율 추정기로 활성화 분포까지 고려한다. Llama2·Llama3·Phi 시리즈에 대한 실험에서 동일 압축 비율·속도 조건에서 기존 최첨단 방법들을 앞선다.
상세 분석
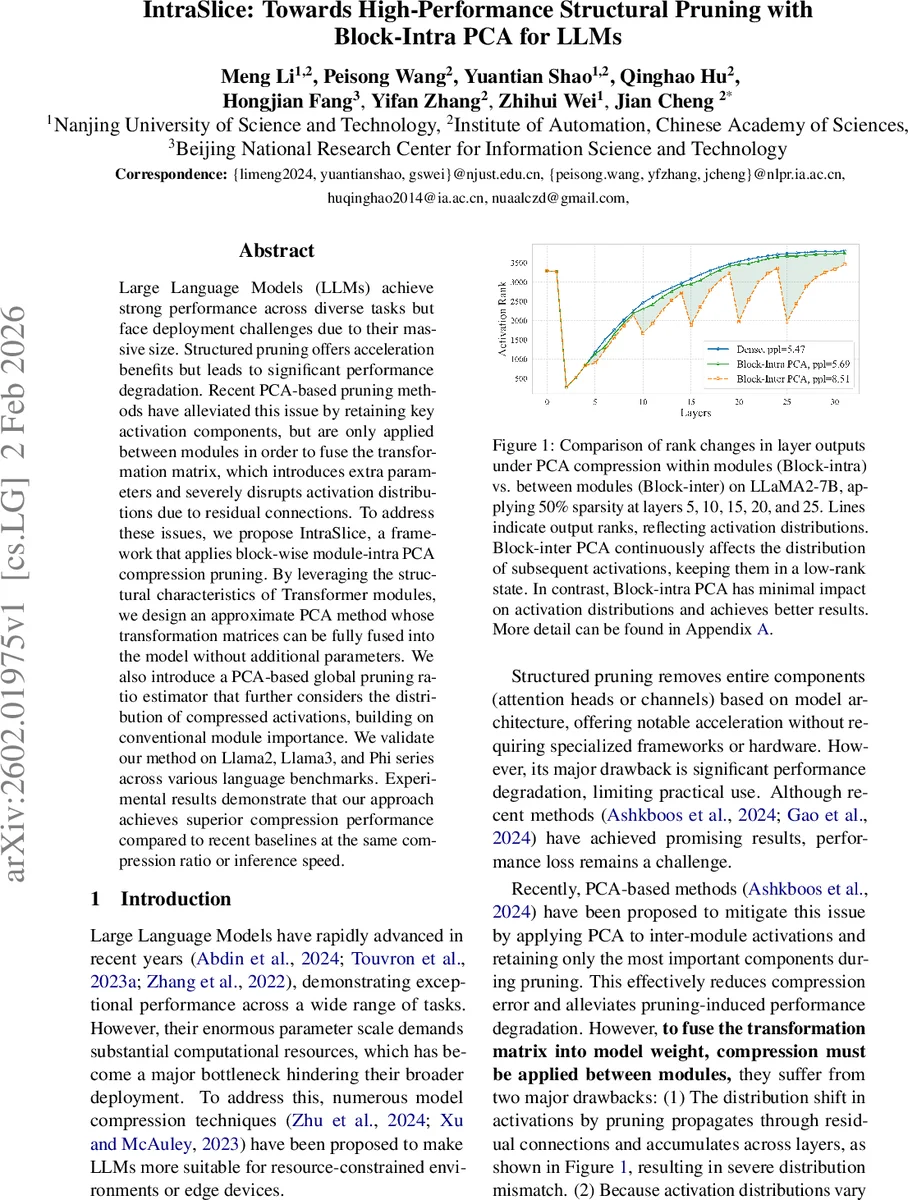
IntraSlice는 기존 PCA 기반 프루닝이 “모듈 간”에만 적용돼 잔차 연결을 통해 활성화 분포가 크게 변형되는 문제를 근본적으로 해결한다. 논문은 트랜스포머의 MHA와 FFN이 각각 다른 비선형 특성을 갖는다는 점을 출발점으로 삼아, 두 모듈에 특화된 두 가지 근사 PCA 기법을 제시한다. 첫 번째는 “Adaptive Head Compression with Block‑PCA”이다. 여기서는 각 어텐션 헤드의 중요도를 채널‑가중치와 활성화 크기의 곱으로 정의하고, 헤드별 고유 고유값(헤시안) 기반 재구성 점수를 계산한다. 이 점수를 바탕으로 가장 낮은 점수를 가진 헤드를 완전 제거하고, 남은 헤드에 대해 동일 압축 차원을 할당해 블록‑단위 PCA를 수행한다. 변환 행렬 Q₁은 query·key 가중치에, Q₂는 value·output 가중치에 직접 융합되며, Q₂는 블록‑와이즈가 아닌 완전 밀집 형태로 설계돼 다른 헤드와의 보완을 가능하게 한다. 두 번째는 “Progressive Sliced Iterative PCA”이다. FFN의 경우 비선형 활성화와 복합 구조 때문에 단순 행렬 변환만으로는 압축을 구현하기 어렵다. 저자들은 전체 활성화 데이터를 한 번에 로드하는 전통적 PCA의 비효율성을 피하기 위해 데이터 차원을 슬라이스하고, 각 슬라이스마다 부분 PCA를 수행해 Q_c와 Q_r을 순차적으로 업데이트한다. 이 과정은 고압축 비율(≈10 % 레이어)에서만 선택적으로 적용돼 전체 연산 비용을 최소화한다. 또한 전역 비균일 프루닝 비율을 결정하기 위해 기존 마스크‑기반 중요도 평가에 PCA 변환 후 활성화 분포 변화를 시뮬레이션한다. 즉, 단순 중요도 점수에 더해 압축 후 예상되는 출력 랭크 변화를 고려해 각 블록에 최적의 프루닝 비율을 할당한다. 실험에서는 Llama2‑7B, Llama3‑8B, Phi‑2 등 다양한 규모의 모델에 대해 30 %~50 % 압축을 적용했으며, 동일 압축 비율·추론 속도 조건에서 기존 SliceGPT, SP³, DISP‑LLM 등을 크게 앞선 퍼플렉시티·정확도 향상을 기록했다. 특히 블록‑내 PCA가 잔차 경로에 미치는 영향이 최소화돼, 활성화 랭크가 급격히 낮아지는 현상이 완화되고, 이는 후속 레이어에서의 정보 손실을 방지한다는 점에서 큰 의미가 있다. 전체적으로 IntraSlice는 “모듈 내부”라는 새로운 차원의 구조적 프루닝을 제시함으로써, 파라미터·연산량 감소와 성능 유지 사이의 트레이드오프를 크게 개선한다.
댓글 및 학술 토론
Loading comments...
의견 남기기